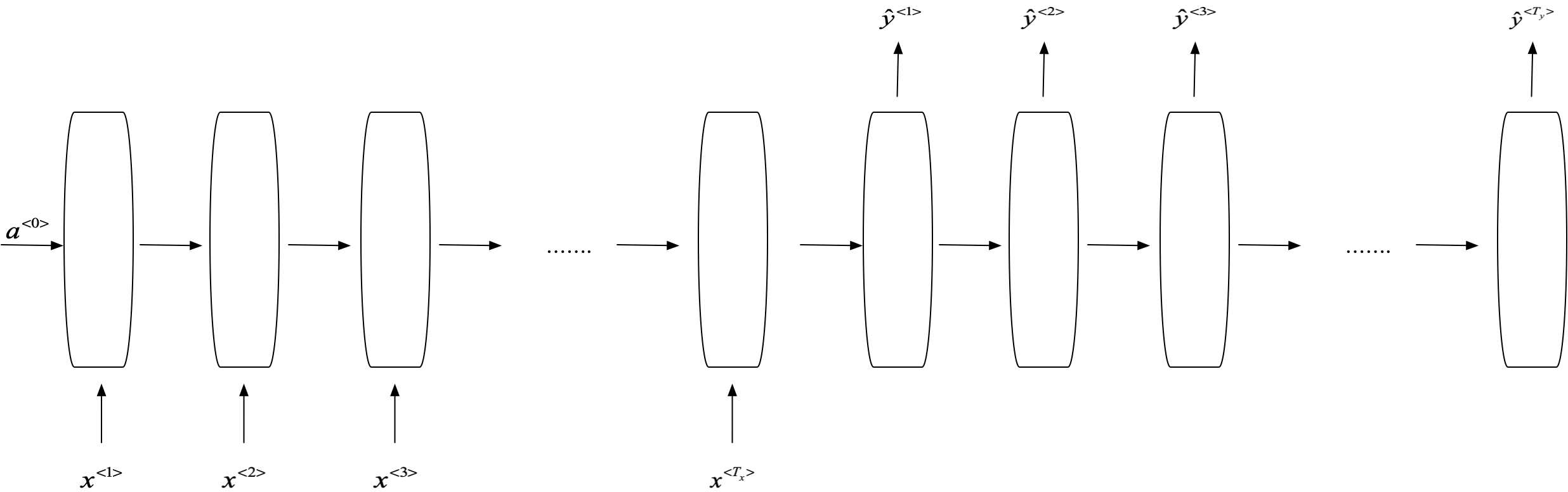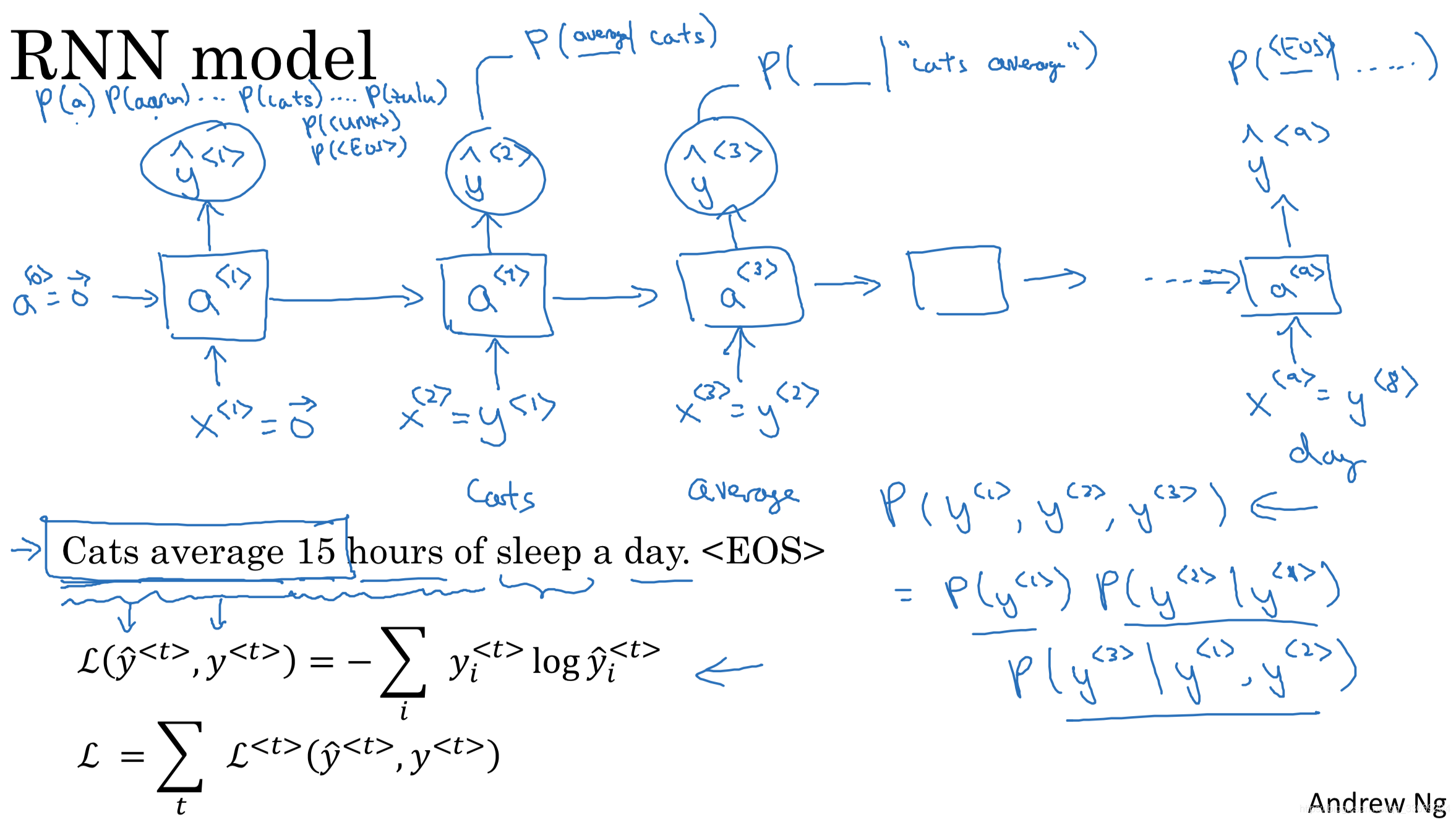Recurrent Neural Networks
1.会议识别:输入一段会议的语音信息,输出语音中的内容
特点都是输入带有前后或者时间顺序的输入进行识别
对输入来说,我们使用
x
<
t
>
x^{<t>}
x < t >
x
<
t
>
x^{<t>}
x < t >
x
<
t
>
x^{<t>}
x < t >
y
<
t
>
y^{<t>}
y < t >
t
t
t
x
(
i
)
<
t
>
:第
  
i
  
个样本中的第
  
t
  
个元素
x^{(i)<t>}\text{:第}\;i\;\text{个样本中的第}\;t\;\text{个元素}
x ( i ) < t > :第 i 个样本中的第 t 个元素
y
(
i
)
<
t
>
:第
  
i
  
个样本中的第
  
t
  
个元素的输出
y^{(i)<t>}\text{:第}\;i\;\text{个样本中的第}\;t\;\text{个元素的输出}
y ( i ) < t > :第 i 个样本中的第 t 个元素的输出
T
x
(
i
)
:第
  
i
  
个样本的长度
T_x^{(i)} \text{:第}\;i\;\text{个样本的长度}
T x ( i ) :第 i 个样本的长度
T
y
(
i
)
:第
  
i
  
个样本的输出长度
T_y^{(i)} \text{:第}\;i\;\text{个样本的输出长度}
T y ( i ) :第 i 个样本的输出长度
为什么不直接使用一般的神经网络:
输入输出在不同样本中长度可以不同,一般神经网络不同样本的输入输出大小相同
在文档的不同位置没有可以共享的特征
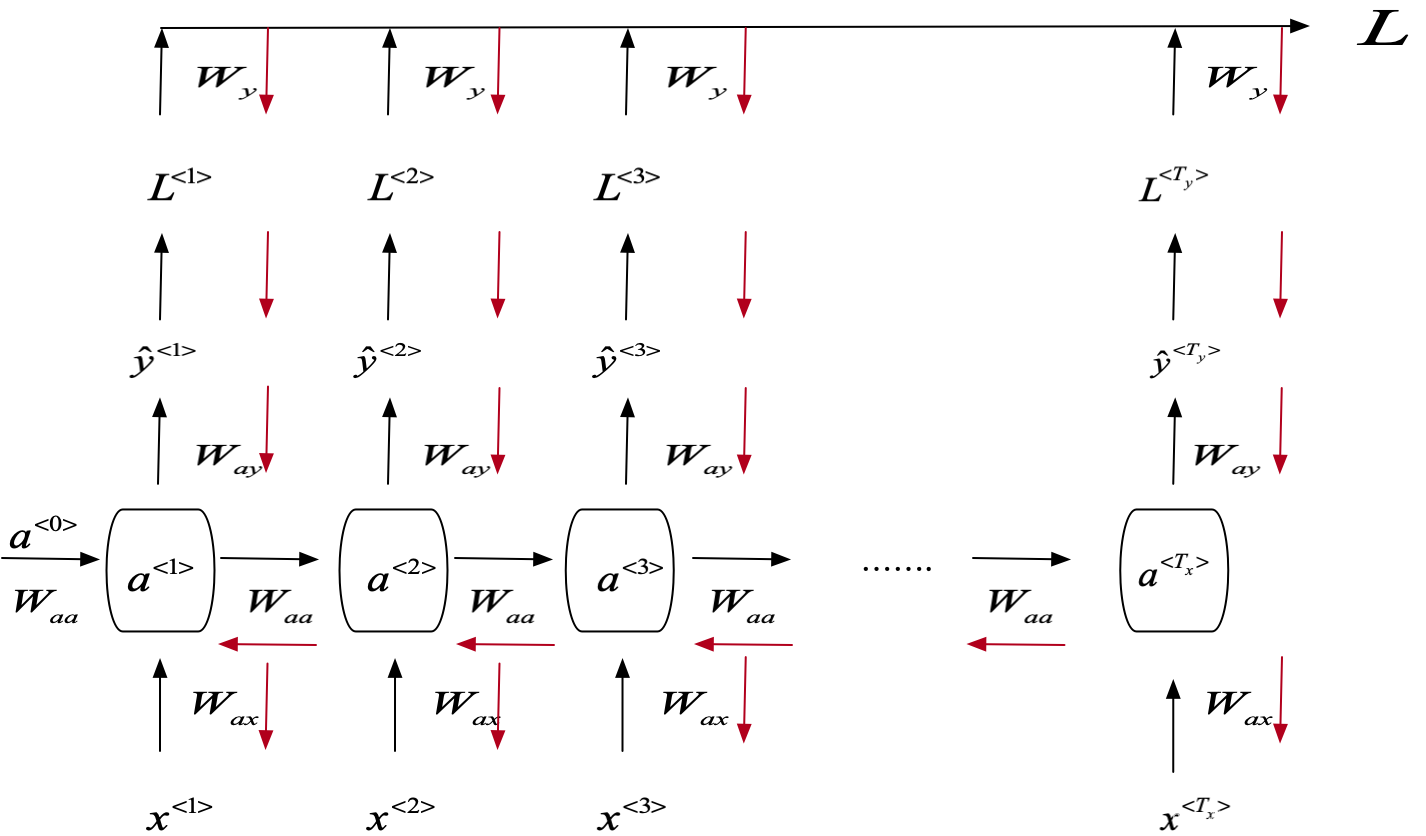
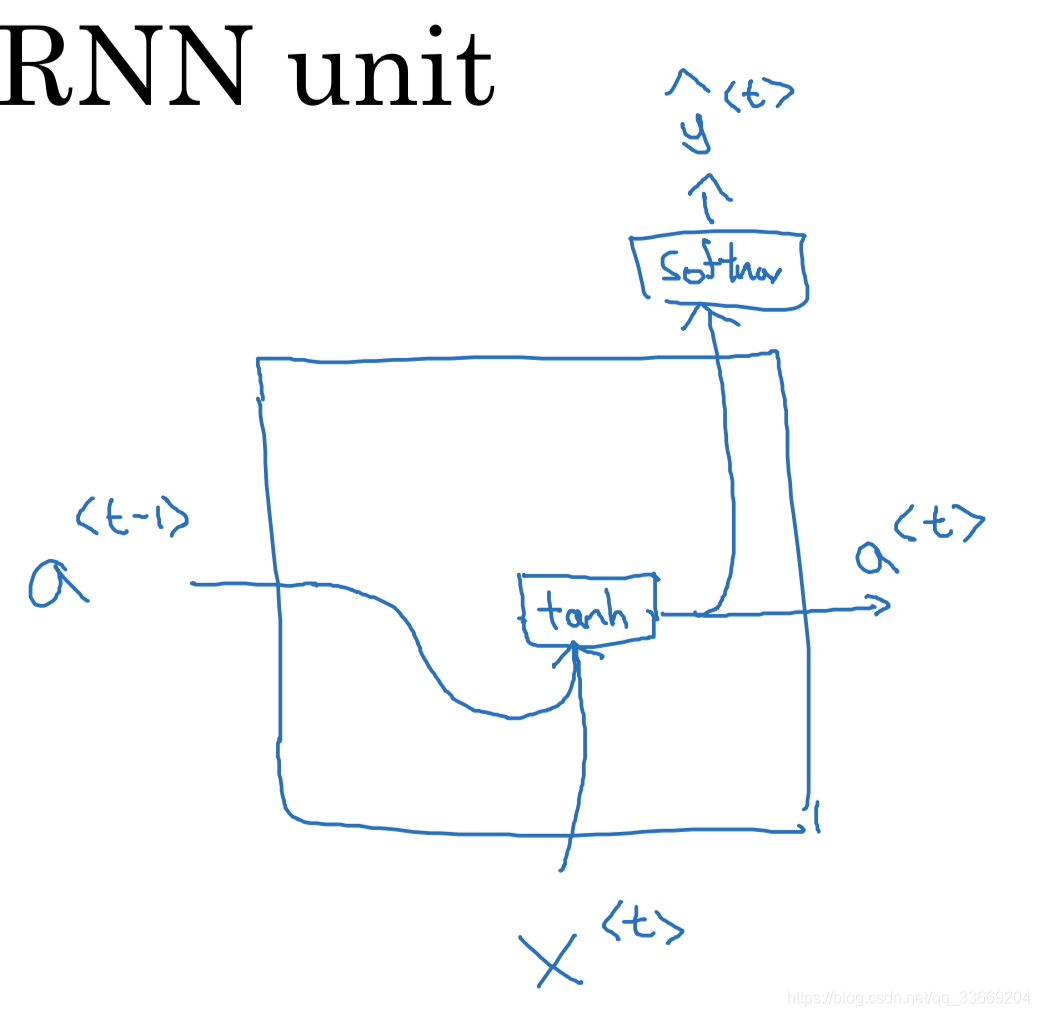
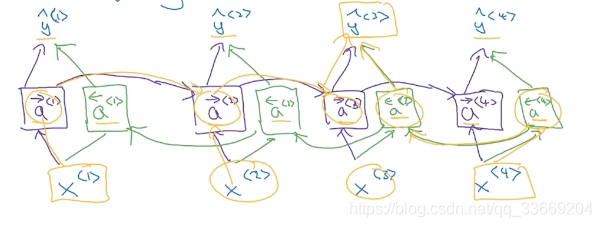
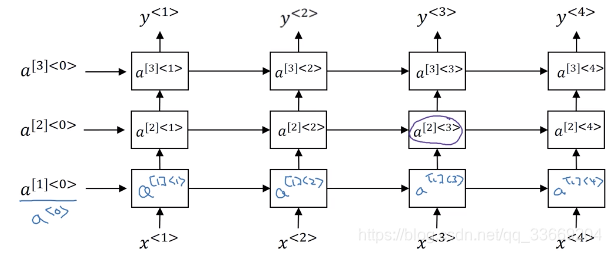
循环神经网络结构:
a
<
0
>
a^{<0>}
a < 0 >
a
<
0
>
a^{<0>}
a < 0 >
a
<
1
>
=
g
1
(
W
a
a
a
<
0
>
+
W
a
x
x
<
1
>
+
b
)
a^{<1>} = g_1(W_{aa}a^{<0>}+ W_{ax}x^{<1>} + b)
a < 1 > = g 1 ( W a a a < 0 > + W a x x < 1 > + b )
y
^
<
1
>
=
g
2
(
W
y
a
a
<
1
>
+
b
)
\hat{y}^{<1>} = g_2(W_{ya}a^{<1>} + b)
y ^ < 1 > = g 2 ( W y a a < 1 > + b )
g
1
g_1
g 1
g
2
g_2
g 2
a
<
t
>
=
g
1
(
W
a
a
a
<
t
−
1
>
+
W
a
x
x
<
t
>
+
b
)
a^{<t>} = g_1(W_{aa}a^{<t-1>}+ W_{ax}x^{<t>} + b)
a < t > = g 1 ( W a a a < t − 1 > + W a x x < t > + b )
y
^
<
t
>
=
g
2
(
W
y
a
a
<
t
>
+
b
)
\hat{y}^{<t>} = g_2(W_{ya}a^{<t>} + b)
y ^ < t > = g 2 ( W y a a < t > + b )
W
a
x
W_{ax}
W a x
W
a
a
W_{aa}
W a a
W
a
=
[
W
a
a
∣
W
a
x
]
W_a = \left[\begin{matrix}W_{aa}& | &W_{ax}\end{matrix}\right]
W a = [ W a a ∣ W a x ]
a
<
t
>
=
g
(
W
a
×
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
a
)
a^{<t>} = g(W_a\times [a^{<t-1>},x^{<t>}] + b_a)
a < t > = g ( W a × [ a < t − 1 > , x < t > ] + b a )
[
a
<
t
−
1
>
,
x
<
t
>
]
=
[
a
<
t
−
1
>
x
<
t
>
]
[a^{<t-1>},x^{<t>}] = \left[\begin{matrix}a^{<t-1>} \\x^{<t>}\end{matrix}\right]
[ a < t − 1 > , x < t > ] = [ a < t − 1 > x < t > ]
W
a
y
=
W
y
W_{ay} = W_y
W a y = W y
y
^
<
t
>
=
g
(
W
y
a
<
t
>
+
b
y
)
\hat{y}^{<t>} = g(W_ya^{<t>} + b_y)
y ^ < t > = g ( W y a < t > + b y )
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
=
−
y
<
t
>
log
y
^
<
t
>
−
(
1
−
y
<
t
>
)
log
(
1
−
y
^
<
t
>
)
L^{<t>}(\hat{y}^{<t>},y^{<t>}) = -y^{<t>}\log\hat{y}^{<t>}-(1-y^{<t>})\log(1-\hat{y}^{<t>})
L < t > ( y ^ < t > , y < t > ) = − y < t > log y ^ < t > − ( 1 − y < t > ) log ( 1 − y ^ < t > )
L
(
y
^
,
y
)
=
∑
t
=
1
T
y
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
L(\hat{y}, y) = \sum_{t=1}^{T_y}L^{<t>}(\hat{y}^{<t>},y^{<t>})
L ( y ^ , y ) = t = 1 ∑ T y L < t > ( y ^ < t > , y < t > )
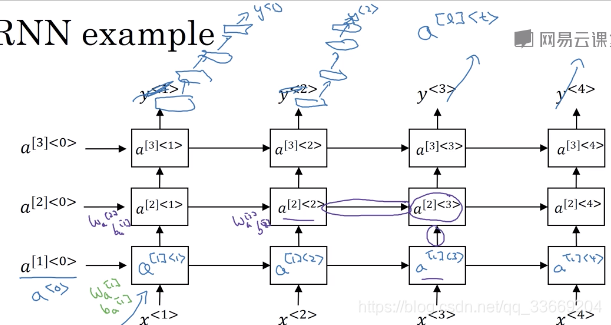
针对循环神经网络的不同任务引入了不同的循环神经网络
many to many:
one to one:一般的神经网络即为one to one
many to one:
one to many:
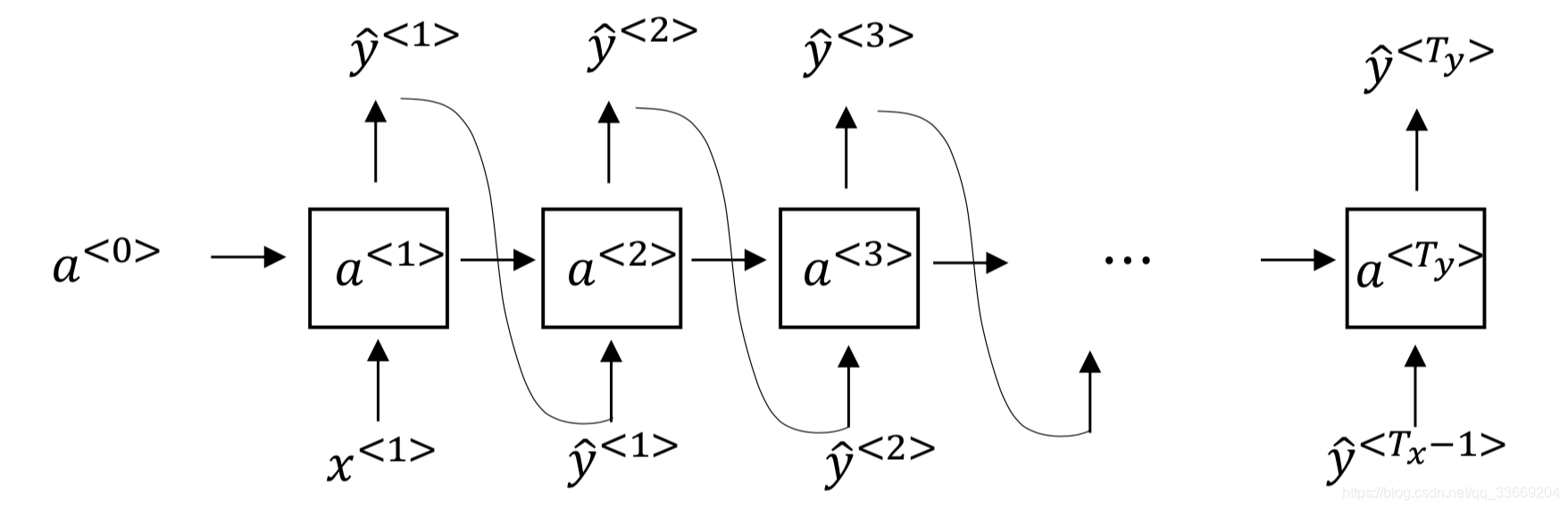
many to many2(machine translation):
语言模型的输出给出了一个句子中各个单词出现的概率。
在训练了一个序列模型之后,我们想知道这个模型到底学习到了什么,可以采用sample novel sequence来验证。
x
<
1
>
x^{<1>}
x < 1 >
x
<
2
>
x^{<2>}
x < 2 >
y
^
<
1
>
\hat{y}^{<1>}
y ^ < 1 >
无法捕捉到句子单词间的前后依赖
句子一般包含多个character,因此训练成本高昂
梯度爆炸:梯度修剪,限制梯度的上限来保证梯度不会过大
梯度消失:对于一般的神经网络而言,当网络很深时,反向传播很难影响到最前边层的参数。对于RNN来说,如果句子后边的某一个单词需要依据前边单词判定(如The cats ,which ate…, were full。were需要根据前边的cats判断),一般的RNN网络很难做到,于是造成了梯度消失。
a
<
t
−
1
>
a^{<t-1>}
a < t − 1 >
x
<
t
>
x^{<t>}
x < t >
a
<
t
>
a^{<t>}
a < t >
a
<
t
>
a^{<t>}
a < t >
y
^
\hat{y}
y ^
a
<
t
>
a^{<t>}
a < t >
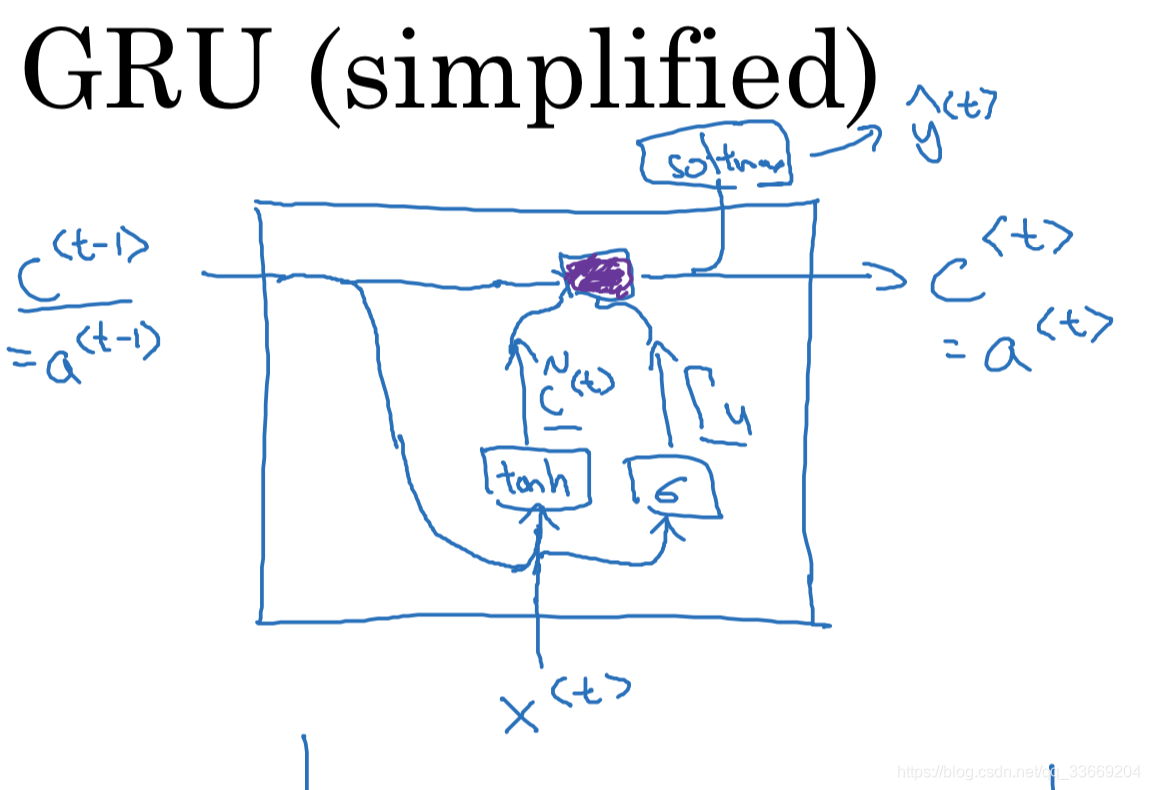
c
<
t
−
1
>
c^{<t-1>}
c < t − 1 >
x
<
t
>
x^{<t>}
x < t >
c
~
<
t
>
=
t
a
n
h
(
W
c
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
\tilde{c}^{<t>} = tanh(W_c[c^{<t-1>}, x^{<t>}] + b_c)
c ~ < t > = t a n h ( W c [ c < t − 1 > , x < t > ] + b c )
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
+
b
u
)
\Gamma_u = \sigma(W_u[c^{<t-1>}, x^{<t>} + b_u)
Γ u = σ ( W u [ c < t − 1 > , x < t > + b u )
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
c^{<t>} = \Gamma_u * \tilde{c}^{<t>} + (1-\Gamma_u)*c^{<t-1>}
c < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 >
Γ
u
\Gamma_u
Γ u
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
+
b
u
)
\Gamma_u =\sigma(W_u[c^{<t-1>}, x^{<t>} + b_u)
Γ u = σ ( W u [ c < t − 1 > , x < t > + b u )
Γ
r
=
σ
(
W
r
[
c
<
t
−
1
>
,
x
<
t
>
+
b
r
)
\Gamma_r = \sigma(W_r[c^{<t-1>}, x^{<t>} + b_r)
Γ r = σ ( W r [ c < t − 1 > , x < t > + b r )
c
~
<
t
>
=
t
a
n
h
(
W
c
[
Γ
r
∗
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
\tilde{c}^{<t>} = tanh(W_c[\Gamma_r * c^{<t-1>}, x^{<t>}] + b_c)
c ~ < t > = t a n h ( W c [ Γ r ∗ c < t − 1 > , x < t > ] + b c )
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
c^{<t>} = \Gamma_u * \tilde{c}^{<t>} + (1-\Gamma_u)*c^{<t-1>}
c < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 >
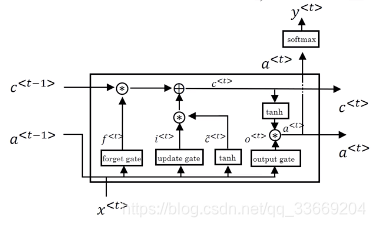
GRU其实是LATM的一个简化版本,LSTM构造更复杂的单元来保证前后之前的依赖
c
~
<
t
>
=
t
a
n
h
(
W
c
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
\tilde{c}^{<t>} = tanh(W_c[c^{<t-1>}, x^{<t>}] + b_c)
c ~ < t > = t a n h ( W c [ c < t − 1 > , x < t > ] + b c )
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
+
b
u
)
\Gamma_u =\sigma(W_u[c^{<t-1>}, x^{<t>} + b_u)
Γ u = σ ( W u [ c < t − 1 > , x < t > + b u )
Γ
r
=
σ
(
W
r
[
c
<
t
−
1
>
,
x
<
t
>
+
b
r
)
\Gamma_r = \sigma(W_r[c^{<t-1>}, x^{<t>} + b_r)
Γ r = σ ( W r [ c < t − 1 > , x < t > + b r )
Γ
o
=
σ
(
W
o
[
c
<
t
−
1
>
,
x
<
t
>
+
b
o
)
\Gamma_o = \sigma(W_o[c^{<t-1>}, x^{<t>} + b_o)
Γ o = σ ( W o [ c < t − 1 > , x < t > + b o )
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
Γ
f
∗
c
<
t
−
1
>
c^{<t>} = \Gamma_u * \tilde{c}^{<t>} + \Gamma_f*c^{<t-1>}
c < t > = Γ u ∗ c ~ < t > + Γ f ∗ c < t − 1 >
a
<
t
>
=
Γ
o
∗
c
<
t
>
a^{<t>} = \Gamma_o*c^{<t>}
a < t > = Γ o ∗ c < t >
GRU更简单,更易构造大型网络且计算够快,便于扩大模型规模
在序列的某点处,不仅可以获取前面的信息,也可以获取将来的信息。
y
^
<
3
>
\hat{y}^{<3>}
y ^ < 3 >