自然语言处理与词嵌入
词汇表征
之前我们表示一个词汇都是创建一个词典,然后基于词汇在词典中的位置创建一个在该位置为1其他位置为0的向量表示词汇。比如我们创建一个10000个单词构成的字典,那么每个单词的向量维度为10000,apple在字典中的第1个位置,那么apple的表示为
,这种表示方法称为 one-hot表示。该表示方法存在很大的缺点:将每个词的完全分隔开,无法知道两个词之间的联系,对相关词汇的泛化能力不强。
另一种表述方法:特征表述(word embedding),即用其他的词来表述当前词汇。
通过这种表述可以更好地发现两个词之间的相似度,embedding是指将词汇以向量的形式嵌入到空间的某点上
基于迁移学习训练word embedding
步骤
- 从大量文集中训练word embedding或者直接从网上下载开源的预训练模型
- 根据新任务给定的小数据集,转换embedding(比如新的任务中有100k个词汇,对embedding进行转换)
- (可选)基于新的数据集对embedding进行调整(只有当新任务的数据集很大时才需要这样做)
这种word embedding的方法通常用于命名实体识别,文本摘要,文本解析,对拥有大量数据的任务应用不是很多。
分析可知 word embedding方法和人脸识别中的 face encoding方法类似,都是将待识别的目标转换为一个向量,但是这两个任务存在着一些不同:Face encoding可以对任意一张图片识别出人脸,而word embedding 只能学习词汇表中的单词,对于未在单词表中的单词标记为 “UNK”
类比推理算法
类比推理算法时由已知的两个词A、B,根据给定的单词C,找出词汇表中与C的关系最像A、B之间关系的词。
例如:我们已知women对应着men,那么在词汇表中与Queen相对应的词是?
对于这个问题,我们可以将词汇表示为word embedding的形式
,这个问题可以转化为找到一个单词
使得
,其中
是指输入之间的相似度,通常我们可以使用 cosine similarity描述相似度,即
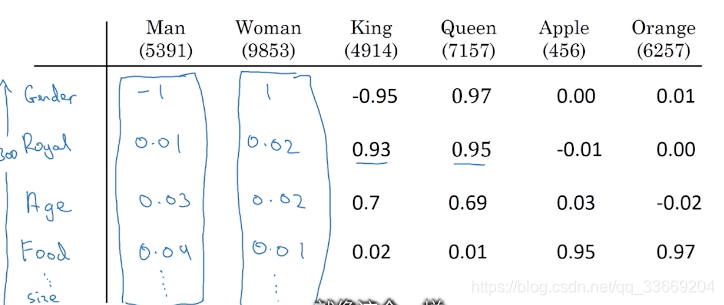
Embedding matrix
embedding matrix是由一系列表征单词的向量构成的矩阵,矩阵中的每一列代表一个单词,在矩阵
中单词的位置与one-hot中单词的位置一致,在神经网络的框架中,通常会有专门的方法从embedding matrix中提取单词,不需要其与one-hot vector相乘。
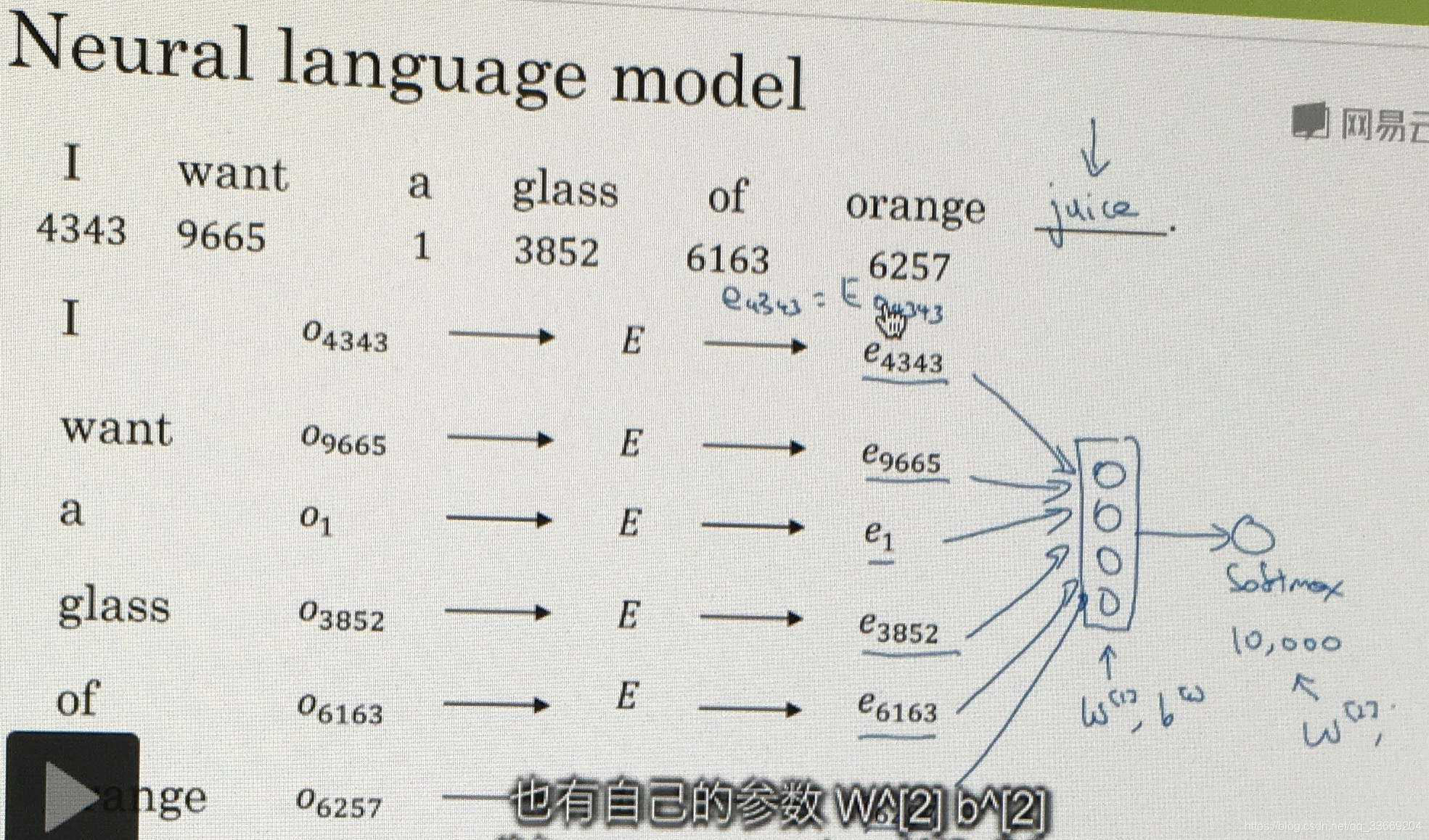
从这个网络中我们可以了解Neural language model的工作模式,首先从embedding matrix中提取出需要的向量,将向量放到网络中进行训练,最后经过softmax得到one-hot中的一个向量。
在训练过程中存在一个超参数:相关词汇的数目。在图示的网络结构中,我们选择了前6个作为预测值的相关词汇,在实际的调试过程中,常见的选择方式有:1. 前4个词汇;2. 前后各4个;3. 前1个; 3. 附近的一个词汇;4. skip gram。
skip gram
skip gram:skip gram时选择一个词作为context,另一个词作为target,选择的方法有很多,前一个或者前几个,后一个或后几个。
在计算softmax时,我们计算的是一个整个词汇表大小的向量,这大大增加了计算复杂度。为了减小计算量提出了hierarchical softmax:先看属于那一部分,再继续分类(类似于建立了一个决策树)。在实际应用时,hierarchical softmax不会是一个balance tree,通常将常用的词放到tree优先级较高的节点上(即靠近root)不用的归为叶节点。
CBOW
CBOW与skip gram类似,将两边的词选做context,然后将中间的词作为target
负采样
先选择一个词作为context,在context一定范围内选择一个词作为正样本;负样本选择同样的context,再随机选择一个词作为负样本,因此是随机选择,我们认为负样本与context无关。负样本的数目k一般在5-20,若数据集很大,那么k在2-5之间,这里用sigmoid函数来训练loss function。
负样本的选取:综合考虑出现频率和重要性(因为出现频率最多的单词如the,of,and的重要性一般不高),使用
作为每一个词汇的选择概率,其中
为总词汇量(embedding的列数),
为词汇的出现频率。
GloVe(Global vectors for word representation)
我们用
表示单词
出现在单词
周围的次数,这里
类似于 target,
类似于 context。
将差距最小化:
其中
给不常出现的单词有意义的运算,给经常出现的单词更大但不过分的权重,当
为0时,
也为0
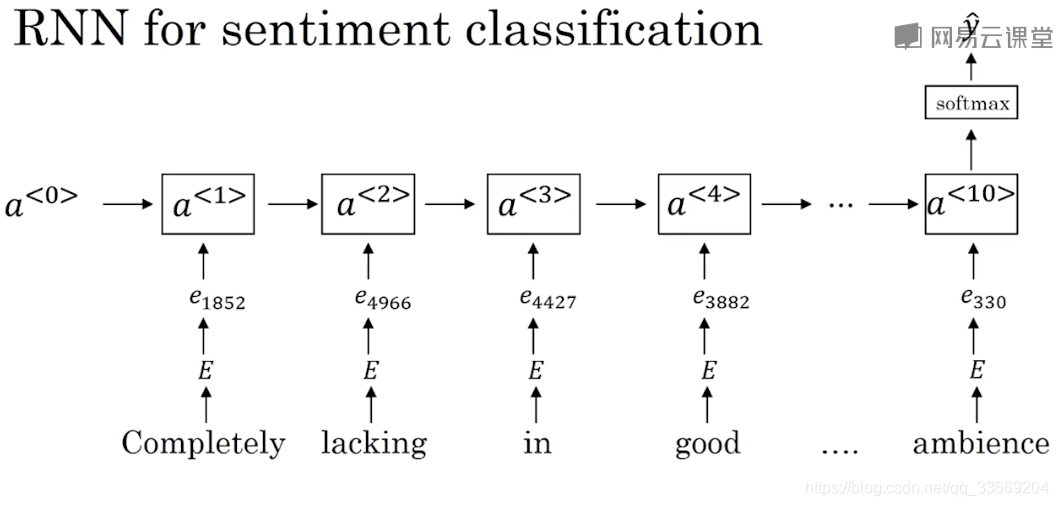
情绪分类
由于情绪分类时不仅仅需要简单的单词识别,也需要先后顺序的判定才能正常识别出情绪,因此在文字识别的基础上引入了RNN网络。
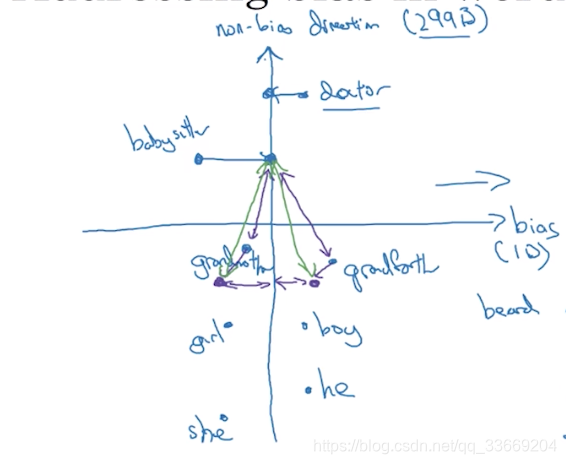
除偏
- 分辨偏见存在的方向,即用坐标轴将存在偏见的词汇与不存在偏见的词汇分隔开(不一定是一维的)
- 基于偏见坐标轴建立无偏坐标轴,将不存在偏见的词汇映射到无偏坐标轴上
- 使得有偏见的词汇到映射后无偏见词汇的距离相等(基于无偏见坐标轴等距,与偏见坐标轴平行)