人脸识别
分类
- Verification:一对一识别,给一张照片,看是否是给定的照片
- Recognition:一对n识别,给一张照片看是否是数据库中的人
显然 Recognition可以通过n次Verification完成
One-shot learning
人脸识别需要解决的一个问题是one-shot learning,即通过一张照片或一个样例就能识别这个人。一种方法是可以基于数据集搭建一个神经网络,输入一张照片时判断属于哪个类别。这样做的缺点是如果数据库加入新人那么需要重新训练网络很不方便。于是提出了构建一个similarity function。d(img1, img2)即反映了img1和img2之间的相似度,基于该公式就可以将输入图片归类于最相似的图片。
Sigmese network
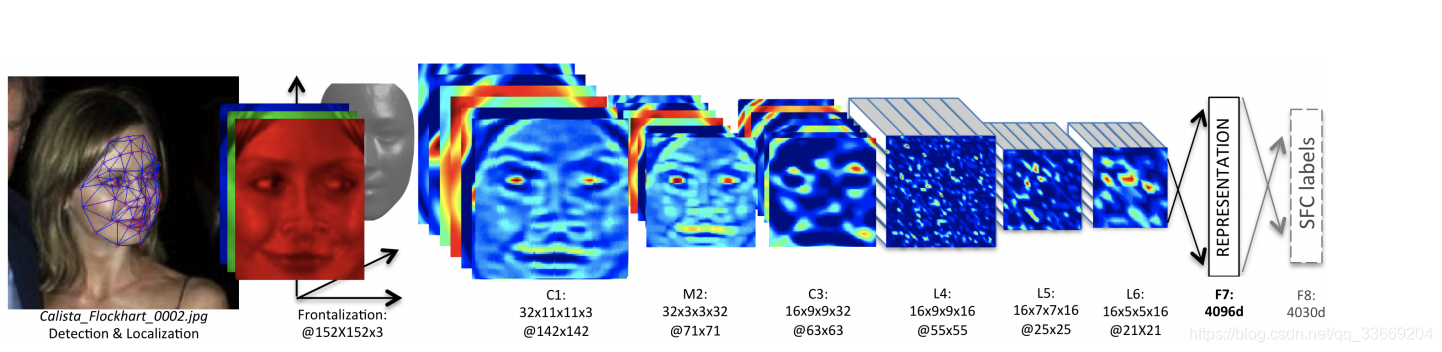
该网络是将输入图像分析为一个向量,通过比较两个向量的相似度来分析是否是同一个人。
也就是说
d(x(1),x(2))=∣∣f(x(1))−f(x(2))∣∣22
通过
d 的大小来反映两张图片中人脸的相似度。
如果
x(i),
x(j)来自同一个人,那么
∣∣f(x(i))−f(x(j))∣∣2很小,反之如果
x(i),
x(j)来自不同人,那么
∣∣f(x(i))−f(x(j))∣∣2很大。
论文地址:https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Taigman_DeepFace_Closing_the_2014_CVPR_paper.pdf
Triplet loss
这里提出了一种损失函数的构造方法。
给出三张图片,一张为样本图片(anchor),一张为同一个人的另一张图片(positive),一张为不同人的图片(negative),这些图片在通过sigmese网络之后,我们希望这三张图片的输出满足
∣∣f(A)−f(P)∣∣2+α≤∣∣f(A)−f(N)∣∣2
这里添加
α 的原因是为了拉大
A→P 与
A→N 之间的差距(这里与支持向量机的处理类似,感兴趣可以看另一篇博客 https://blog.csdn.net/qq_33669204/article/details/83239793 )。
该式也等于
∣∣f(A)−f(P)∣∣2−∣∣f(A)−f(N)∣∣2+α≤0
这样
α 也可以避免所有的编码的输出都等于0。
所以loss function可以定义为
L(A,P,N)=max(∣∣f(A)−f(P)∣∣2−∣∣f(A)−f(N)∣∣2+α,0)
J=i=1∑mL(A(i),P(i),N(i))
通过
L(A,P,N) 的定义我们可以知道三张图片的
L一定是一个大于等于0的值,我们希望来自相同人向量之间的差距小于来自不同人向量之间的差距,但这样又会使loss function小于0违背了loss function必须大于等于0的原则,因此需要添加一个Max函数。
在构筑数据集时也应该注意由于我们需要 A和 P,因此在数据集中应该有来自同一个人的不同图片,在挑选 A,P,N时也应该注意如果我们随机选,那么两个差距很大的人很容易满足loss function,因此挑选时尽量使A和P的差距不大即
d(A,P)≈d(A,N)
训练时应该使用别人开源的预训练模型来加快训练,不要从头开始。
论文地址:https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Schroff_FaceNet_A_Unified_2015_CVPR_paper.pdf
Face verification和二分类
y^=σ(k=1∑nωk∣f(x(i))k−f(x(j))k∣+b)
上式表示第 i 张图片和第 j 张图片之间的差距,使用sigmoid函数激活后判断两张图片是否来自一个人。
Neural style transfer
卷积神经网络可视化
这里提出了一个很重要的概念:卷积可视化,通过理解这个原理,我们可以知道卷积神经网络的每一层在干什么。
由视频中我们可以知道,随着网络层数的加深,一个隐藏单元激活的部分对应的特征越来越大(从边缘特征到物体的整个特征)。

这里需要提到几个概念:
- 输出图片九个作为一组是一个channel的输出
- 视频中提到的隐藏单元我们可以认为是卷积层的一层
- 一个channel的九张图片是将验证集输入到网络后,在映射的特征上随机构造一个子集,在这个集合上选择9个激活值最大的位置反向映射到原图上
基于上边三个概念,我们可以对图中的图片进行理解,以layer2第一行第二列的9张图为例,这9张图很明显都存在垂直纹理,那么就可以说明layer2的卷积层对图片中的垂直纹理特征有很好的激活。
论文地址:https://arxiv.org/pdf/1311.2901.pdf
Content cost function
J(G)=αJcontext(C,G)+βJstyle(S,G)
基于这个式子,我们可以知道风格转换需要同时考虑内容与风格上的相似度,假设
α[l](C) 与
α[l](G) 是卷积层的激活值,如果这两个值相似,那么就说明卷积网络的输出可以保证在内容上与内容图片相似。
Content
我们可以通过
Jcontext(C,G)=21∣∣α[l](C)−α[l](G)∣∣2 求解。
Style
在求解style的cost function之前需要先定义一些名词:
- 风格:不同channel之间的关联程度
- 相关系数:同一个地方出现两种channel表示特征的可能性
通过这两个定义我们可以知道风格也就是不同channel之间相关系数的反映。
假设
ai,j,k[l](S) 为第
l 层卷积在
(i,j,k) 处的激活值,
G[l] 为当前层的相关值矩阵(G是指 gran matrix),大小为
nc[l]×nc[l],
G[l] 在
(k,k′)处相关值为
Gkk′[l](S)=i=1∑nH[l]j=1∑nw[[l]aijk[l](S)aijk′[l](S)
上式表示输入风格图像的相关值矩阵
Gkk′[l](G)=i=1∑nH[l]j=1∑nw[[l]aijk[l](G)aijk′[l](G)
上式表示卷积神经网络的style输出。
Jstyle[l](S,G)=τ1∣∣G[l](S)−G[l](G)∣∣F2
Jstyle[l](S,G)=2nH[l]nW[l]nC[l]1k∑k′∑(Gkk′[l](S)−Gkk′[l](G))
τ为归一化常数
1D 和 3D卷积核
对于序列输入,经常使用1D,这在之后的课程中会使用
3D在目标动作检测中使用过,多出的一维可用于检测时间维度上的信息,一篇相关论文:https://ieeexplore.ieee.org/abstract/document/6165309