04. 序列模型
第二周 自然语言处理与词嵌入
2.1 & 2.2 词嵌入
前面我们都是借助词典用one-hot向量表示词汇,这样做有个缺点,就是不能表示词汇之间的相关性,比如苹果、橘子应该有着相似的表达。
另一种词汇的表示方法是用特征化的表示,可以选择一些抽象特征来归纳不同词汇的特点:

这种将词汇转换为特征向量的做法也叫做词嵌入(word embedding),意为将词嵌入到高维空间。其实在计算机视觉领域我们习惯叫编码(encoding).
使用词嵌入确实会带来很多好处,比如一个识别句子中人名的任务采用词嵌入作为输入:
- 训练集:Sally Johnson is an orange farmer.
- 测试集:Robert Lin is an apple farmer.
- 测试集:Bruce Ma is a durian cultivator(榴莲培育师).
模型就可以根据orange和apple相似,来推断Robert Lin也是一个人名;甚至durian cultivator可能并不包含在10000词的词典中,模型也可以通过词嵌入知道durian和orange相似,cultivator和farmer相似,以此推断Bruce Ma是人名。
NLP的很多任务可以借助词嵌入可以实现迁移学习:
- 在一个很大的语料库(1-100B词)中学习词嵌入,或者直接利用网上的预训练模型;
- 用很小的数据集(100k词)将词嵌入迁移到特定任务上。比如一个很小的人名标记数据集。
- (可选)如果数据集很大的话,可以考虑finetune词嵌入模型
2.3 类比推理
利用词嵌入可以做很多事情,类比推理(analogy reasoning)就是一个。
什么是类比推理?老祖宗说得好啊,那就是天对地,雨对风,大陆对长空,山花对海树,赤日对苍穹。如果我告诉模型词汇“Man”对应“Woman”,模型需要给我找出词汇“King”对应的那个词。
有了词嵌入\( e \),模型就可以根据一个词的词嵌入\( e_w \)满足\( e_{\text{man}} - e_{\text{woman}} \approx e_{\text{king}} - e_{w} \)来寻找,也就是:
\( \arg\max_w sim(e_w, e_{\text{king}} - e_{\text{man}} + e_{\text{woman}} ) \)
常用来度量相似性的指标是余弦相似性:\( sim(u,v) = \frac{u^T v}{\|u\|_2 \|v\|_2} \)
2.4 & 2.5 学习词嵌入
前面讲了那么多词嵌入的好处、用处,而学习词嵌入其实就是学习一个嵌入矩阵(embedding matrix)。

这个嵌入矩阵\( E \)应当满足\( E \dot O_j = e_j \),其中\( O_j \)是one-hot向量,\( e_j \)是这个词的词嵌入。
不过实际中计算词嵌入并不使用矩阵乘法(太大),而是专门的函数。
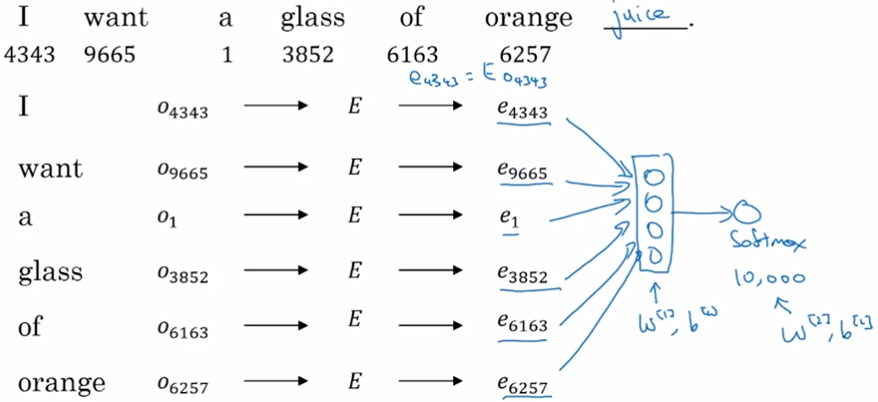
下面是一个用来学习词嵌入的模型。给出文本的前几个词,模型要预测下一个词。具体来说,首先初始化一个嵌入矩阵\(E\),将文本中的词转换为词嵌入,然后把这些词嵌入连起来构成一个向量输入到神经网络中,这里可以固定输入网络的词长度,比如只输入前四个词汇。网络可能包含一个隐层一个softmax层,都有待学习参数,同时嵌入矩阵也需要学习。
2.6 Word2Vec
Skip-gram是另一种学习词嵌入的方法,不同于选择文本中的前几个词来推断下一个词,这种方法首先选择一个上下文词(context)\( c \),然后在这个词的前后一定范围内(比如10词之内)选择一个目标词(target)\( t \),训练网络学习从\(c\)到\(t\)的映射。

从one-hot向量转换为词嵌入,然后经过softmax层输出预测的词(比如10000维的向量),参数包括嵌入矩阵\(E\)和softmax层的参数。
可能看完了有点摸不着头脑,但这样训练的目的并不是为了完成这个词预测的任务,而是为了学习一个较好的词嵌入。
问题就是词典非常大时,softmax计算量太大,下面介绍另一种方法。
2.7 负采样
我们将学习问题转换为:给出一对词,模型学习判断这是不是一对context-target。为了学习这个任务,我们先构建数据集:
- 先从文本中抽取一对context-target,作为正样本;
- 从词典中随机抽取 k 个词与context构成一对负样本;
比如“I want a glass of orange juice to go along with my cereal.”
| Context | Word | Target |
| orange | juice | 1 |
| orange | king | 0 |
| orange | book | 0 |
| orange | the | 0 |
| orange | of | 0 |
注意,即使“of”也在语料中存在,但由于是从词典中随机抽取的,也作为负样本。如果数据集很小,k一般取5~20,如果数据集很大,k一般取2~5。
具体实现方法是输入context词的词嵌入,输出是10000个二分类器(不是softmax),对应词典中的10000个词。这样每组样本训练只更新 k+1 个分类器的参数,比softmax的计算量要大大降低。

表格中三列分别记为\( c,t,y \),二分类器为 \( P(y=1|c,t) = \sigma(\theta_t^T e_c) \)
而对词典进行采样时并不是均匀采样,常用的方法是根据其在语料库中的词频计算:
\( \begin{gathered} P(w_i) = \frac{f(w_i)^{3/4}}{\sum_{j=1}^{10000}f(w_j)^{3/4}} \end{gathered} \)
2.8 GloVe方法
这个没看懂……算了咱也不是搞这个NLP的,简单看看吧。
引入了一个新的量\( X_{ij} \)表示\(i\)出现在\(j\)上下文中的频次,梯度下降法优化下面的式子:
![]()
2.9 情感分类
这个任务的目的是从一段文本中分析说话人的情绪,主要困难是标注数据太少,但利用一个预训练好的词嵌入就可以构建不错的模型。
你可选择的方法很多,比如最简单的,对一段文本的词嵌入直接取平均后送入分类器:

或者采用RNN模型:

显然第二种方法更好,第一种方法丢掉了词序信息。
2.10 词嵌入除偏
在学习了大量语料之后会有一个有意思的现象:词嵌入学习到了人类的偏见。
比如性别偏见:
Man → Computer Programmer, Woman → Homemaker;
Father → Doctor,Mother → Nurse;
要消除这种偏见,有一些专门的工作,不再详述。