机器学习基石 Lecture2: Learning to Answer Yes/No
Perceptron Hypothesis Set
还是关注是否给客户发信用卡的问题。回顾上节中机器学习的流程,假设已知如下图中的一些客户信息,做出怎样的假设来得到假设集合
H呢?
可以把客户信息写为一个向量
x=(x1,x2,...,xd),每个维度都代表客户的一个特征。可以假设把这些特征维度进行加权求和来得到一个分数,如果这个分数超过某个阈值就下发信用卡,否则不下发。即假设h为:

这个假设就叫做感知机(perceptron)模型。
Perceptron Learning Algorithm
可以将上图等式中的阈值(threshold)也当做一个系数
w0,对应第0个特征
x0=1。则上述感知机模型可以写为向量内积的sign函数形式:

于是在二维平面上这个假设函数体现为一条线,一边被判断为+1(蓝色),另一边的点被判断为-1(红色)。而样本实际的y为+1时画为圈,-1时画为叉。
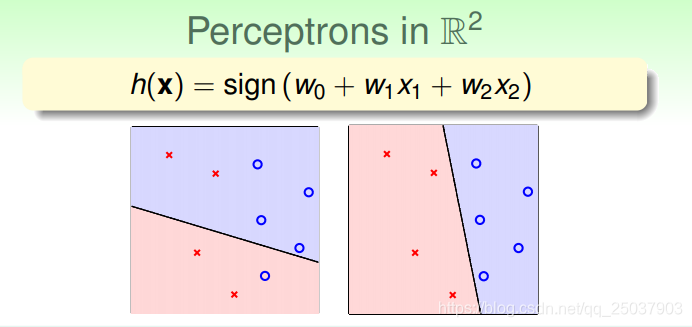
因此可以看出,感知机实际上是一个线性的二分类器。
有了假设空间
H,如何从中选出一个最接近实际函数
f的
g呢?可以根据在已有的数据集合上来判断。因为
g需要接近
f,因此在已有数据记录
D上,
g(xn)的结果需要等于
f(xn)(必要不充分条件?)。
但是有个问题是假设空间
H是无穷大的,所以直接搜索比较困难。有一个想法是,从一个任意的函数
g0开始,根据它在数据集
D的错误来不断改进自身。于是我们就有了感知机学习算法(Perceptron Learning Algorithm,PLA):

- 从任意一个参数为
w0表示的函数
g0开始,找到一个预测的结果和实际对应的
y值不同的样本。
- 然后根据公式
wt+1←wt+yn(t)xn(t)来对系数进行更新。
直到找不到错误的样本为止,此时的参数
wPLA对应的函数就是
g。
实际中算法第一步通常采用遍历数据集
D的方式,因此也叫作Cyclic PLA。
算法看起来很简单,但是还有一些遗留问题。比如:算法如何进行遍历样本? 可以是普通遍历,随机遍历等。最后得到的算法
g是否真的约等于
f? 如果在
D上没有错误算法停止了,那么在
D上的效果肯定是近似相等的。但是在数据集
D之外的数据上表现如何呢?而且如果算法不停止更加无法知道
g是否与
f近似了。所以算法是否真的能够保证最终停止而不是无限循环呢? 下面会给出算法确定会停止的证明。
Garrantee of PLA
如果存在一个对应的系数
w能够在数据集
D上不犯错误,也就是说
D中的样本能够被一条线性平面正确分隔开。我们说这样的
D具有线性可分性。
假设我们的数据集
D是线性可分的,那么是否PLA算法一定会停止呢?
线性可分的
D一定有一条不会犯错的分隔面对应的参数
wf。
- 对于任意的样本都有
yn(t)wfTxn(t)≥minnynwfTxn>0.(因为每个样本都正确分类)
-
wf与
wt的乘积为
wfTwt+1=wfT(wt+yn(t)xn(t))≥wfT+minnynwfTxn>wfTwt
- 两者乘积在变大,但是需要证明并非是因为其长度增加而是夹角变小,这样才能说明我们的
wt在靠近最好的分隔面对应的
wf
- 计算
wt的模。
∣∣wt+1∣∣2=∣∣wt+yn(t)xn(t)∣∣2=∣∣wt∣∣2+2yn(t)wtTxn(t)+∣∣yn(t)xn(t)∣∣2≤∣∣wt∣∣2+0+∣∣yn(t)xn(t)∣∣2≤∣∣wt∣∣2+maxn∣∣ynxn∣∣2因为我们是在分类错误的样本上进行更新,因此
ynwtTxn≤0。
- 根据以上几点,能够推出
∣∣wf∣∣wfT∣∣wT∣∣wT≥T
∗constant。 过程如下:
1≥∣∣wf∣∣wfT∣∣wT∣∣wT≥∣∣wT∣∣∣∣wf∣∣TminnynwfTxn≥Tmaxn∣∣xn∣∣2
∣∣wf∣∣TminnynwfTxn≥T
Rρ
于是T≤ρ2R2,因此算法一定在有限步骤内停止。其中
R2=maxn∣∣xn∣∣2,ρ=minnyn∣∣wf∣∣wfTxn。都是常数。
因此,只要是数据集是线性可分而且不断地纠错,那么在PLA算法中:
-
wf和
wt的内积快速增大,而
wt的长度缓慢增大
- PLA算法得到的“线”会越来越接近
wf,直到不犯错停止
PLA算法的优缺点:
- 优点:实现简单,运行速度快,在任意维度可行
- 缺点:1.需要假设样本线性可分。 2.不知道算法停止需要的时间。
Non-Separable Data
假设数据集中有一些噪音,这样就会导致数据集并不是完全线性可分的。这时候就需要进行一定的容错。对于PLA算法而言,可能从选择完全不犯错的分隔面变为选择一个犯错误最少的分隔面。

可以对PLA算法做一些简单的修改,先保有一条当前最好的分隔面,然后和先前一样进行更新。如果更新后的分隔面比当前最好更优,那么把当前最好换成这个更新后的分隔面,否则继续保有原来的。直到足够多的循环次数为止。
