机器学习基石 Lecture4: Feasibility of Learning
Learning is Impossible?
假设有一个实际的面向人的益智问题,给出上面6个例子,判断下方图形对应的y:

根据不同的规律,可以给出不同的对应函数f。于是最后一张图片也会有相反的结果。比如:

因此对于这个问题来说没有一个正确的答案。这只是一个引例。那么对于一个实际的机器学习二分类问题,假设有如下的数据样例:

对于这个问题,由于输入和输出都是有限的,因此可以枚举出所有的实际对应的函数
。如果使用了类似PLA的算法得到一个在训练数据
中都和
的结果一致的结果
,那么是否能够说明这个
?可以枚举出所有的
,可以看出得出的
并不一定接近实际函数
。
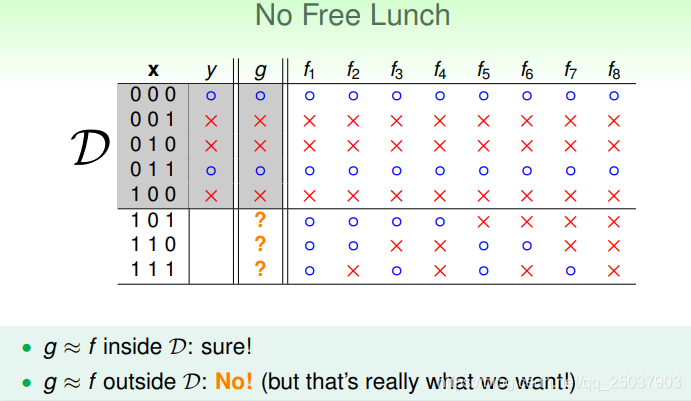
可以看出来并没有一个固定的
能够在
之外确定地接近
。这就是No Free Lunch Theorem,也就是说,在没有限制的情况下,没有一个算法得到的结果能够确定比其它所有算法都好。除非做一定的限制。
Probability to the Rescue
既然很难推断出
之外的
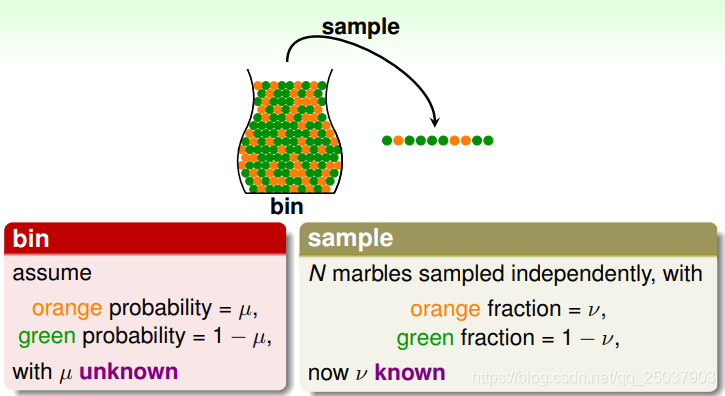
的表现,那么是否可以推断出其他情况下的一些东西呢?比如有一个瓶子里有一些绿色和黄色的弹珠。如果想要推断两种颜色各自所占比例
,那么就可以选择从中采样出
个弹珠观察样本里两种颜色各自所占比例
。但是样本采样得到的概率
能够说明样本之外的瓶子中玻璃珠所占比例呢?
根据 Hoeffding’s Inequality,采样的概率与样本外的概率关系为:
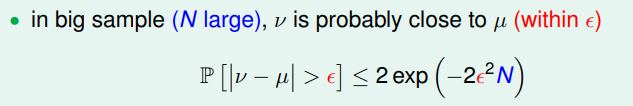
也就是概率
与概率
相等这样的说法有可能是大致正确的(probably approximately correct,PAC)。因此对于比较大的
来说,可以大致通过
来推断
。
Connection to Learning
而上述不等式与机器学习算法有何关联呢?如下图所示:

弹珠可以看成样本,假设
的结果是否正确可以对应两种颜色。N个采样可以对应数据集
中的数据样例。类似的,通过较大的采样数量
,可以通过在已知数据集
上的
的正确率来大致估计数据集之外的
相对于
的正确率。也就是:

但是对于返回一个固定的假设
作为结果
的算法,不能够叫做一个好的学习算法。因为对于数据集
上的错误率
比较大的情况时这个
(PAC)不等于
。
因此一个真正的学习算法 需要能够在假设集合 中进行选择得到最终的 而不是返回一个固定的 作为 。
Connection to Real Learning
在不同的假设函数里进行选择如下图所示,每个
都对应一个
和一个
:
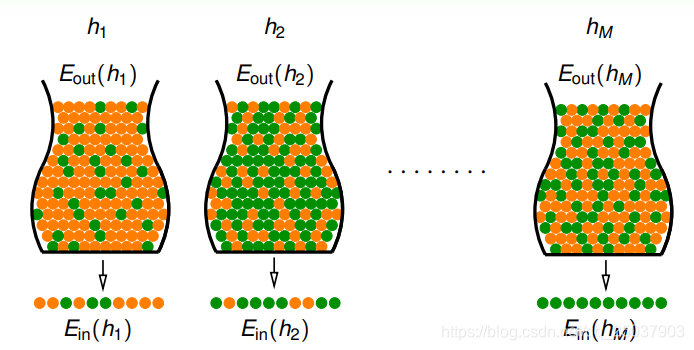
那么一个最重要的问题是,是否在集合
上的例子中错误率最小的假设函数就是最好的假设呢?
假设150个人丢同样的硬币,每个人丢5次。有大于99%的几率会有至少一个人丢出来5次都是正面向上。但是这并不能说明这个人的硬币丢出正面的概率比其它人更大。在这个采样里
和
相差很远,也就是说这个人的采样是一个比较失败的采样。但是这样的采样对于选择假设函数时影响非常大。只要有比较失败的采样那么算法就不能够按照
进行自由选择不同的假设函数。对于一个假设集合而言,数据集合
只要对其中一个假设函数来说是比较失败的采样,那么它就是失败的。

假设空间一共有M个假设函数,那么这个假设空间遇到比较坏的采样的概率上限为:

也就是说,对于比较大的N和有限的M来说,不论是什么样的算法,
是有可能大致正确的(PAC)。因此最合理的算法
会选择在数据集
上错误率最小的假设
作为
。
因此整体的学习过程如下:
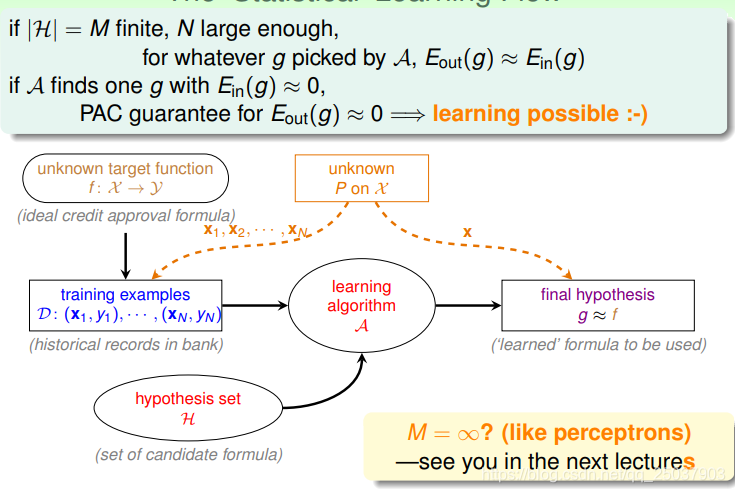
也就是说对于假设空间是有限的情况下,学习是可行的。而一个合理的算法最终会选择一个在
上错误率最小的假设
作为结果
。但是对于假设空间无限大的情况,以后的课上再讲。