一.Perceptron Learning Algorithm
1.回顾机器学习流程
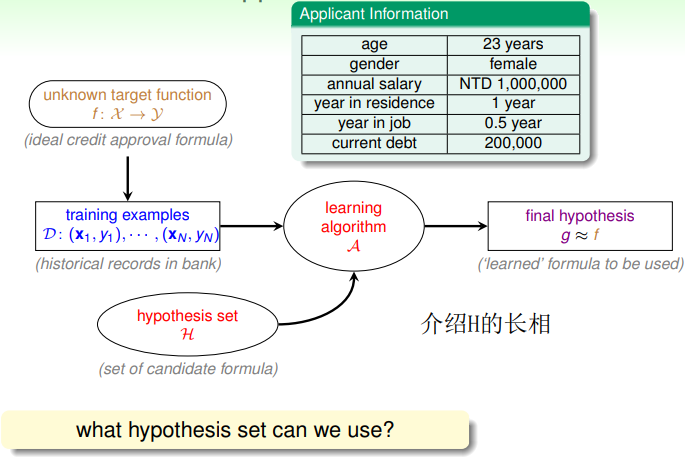
思考假设空间H是什么样的,学习算法A确定后,h的样子就确定了,根据W的不同可以得到不同的h,构成假设空间H,学习算法从H中挑选表现最好的h即为最终的g,g和f在D上表现应该尽量一致,在未知数据(test data)上越接近代表性能越高。
2.PLA原理
PLA是二元线性分类算法,找一条线或平面或超平面可以将数据根据标签的不同一分为二。银行发信用卡问题,给用户不同的信息赋不同的权值,当累加超过阈值时,发行用卡,当没有超过阈值时不发信用卡。

当算法确定后,H的形式确定,即为h(x),由wi和threshold决定,看PLA在二维空间的情况,根据w0(-threshold),w1,w2的不同取值,得到不同的h,这些h构成了假设空间H,算法的目标是在H中找一条最好的直线(没有误分类点)将D中的数据一分为二。

公式化简,将阈值的相反数表示为w0,W的维数增加了一维,相应地数据X的维数也要增加一维x0,x0=1。

前面提到算法的目标是找到一条最好的直线,但是二维空间中的直线有无数条,找最好的并不容易,我们一般采取的方法是选定一条直线,对该直线进行修正。
3.修正方法(更新过程)
遍历数据集D,当出现误分类点时,更新W,重复该过程直到在数据集上没有误分类点为止。

更新规则有两种情况:①yn=+1,而计算出来的h(xn)=-1,说明W和X的内积<0,说明W和X的夹角太大,需要W+X,调小角度。
②yn=-1,而计算出来的h(xn)=+1,说明W和X的内积>0,说明W和X的夹角太小,需要W-X,调大角度。
更新W其实就是在H中找到与目标f更为相似的h的过程。
更新使异常程度变小,尝试把线转到正确的方向上去,即h越接近目标函数f。


4.停止更新
思考:算法迭代一定会停吗?
回顾停止条件:在当前W下,遍历数据集D中的所有数据点,没有误分类点时,停止。
当数据集线性可分时,算法能够停止。

每次更新使Wt接近Wf

跟新一轮后,Wf和Wt+1的内积>Wf和Wt的内积,内积=||Wf||*||Wt||cosθ,内积变大有可能是cosθ变大,也有可能是||Wt||变大,不能说明Wt和Wf越来越接近,还需解决长度问题。

可见Wt不会增加太快,所以每次更新Wt会越来越接近Wf。

5.PLA的优缺点
