版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/coffee_cream/article/details/60473789
【上一篇 2 从Multi-arm Bandits问题分析 - RL进阶 】4 动态编程(Dynamic Programming, DP) 】
本次总结中的 1-4 小节主要介绍了增强学习中的一些重要的概念,如:Goals、Rewards、Returns、Episode 等,第 5 小节介绍了 Markov Property,第 6 小节介绍了 Markov Decision Processes,第 7、8 小节介绍了 RL 中的 Value Function。可以说这次总结也是为之后介绍 RL 相关算法做了铺垫。
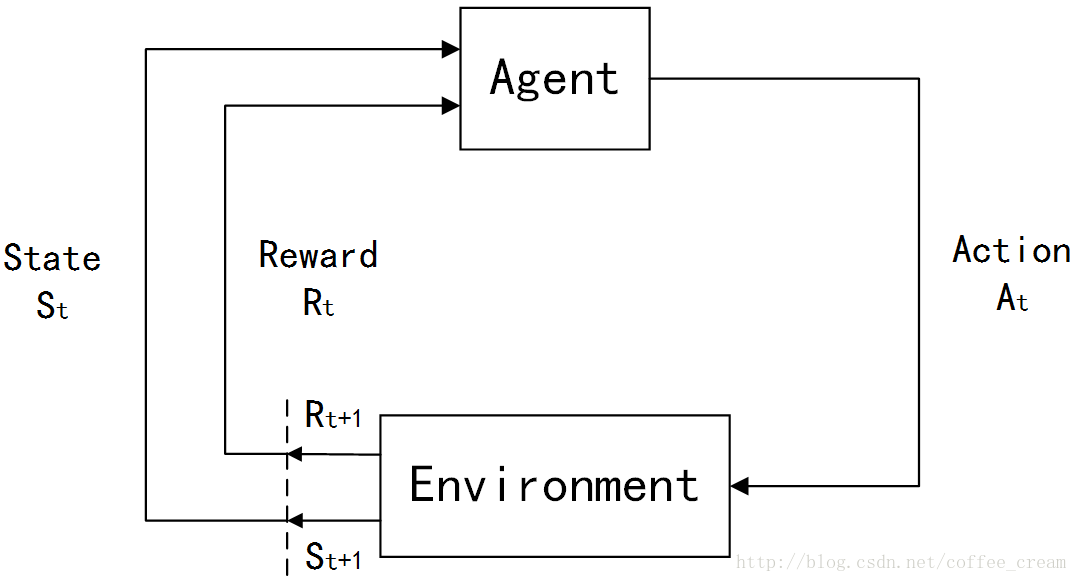
在强化学习(Reinforcement Learning, RL)初步介绍 中曾经介绍了 RL 问题的一般模型,下面再简单回顾一下:
在 RL 中,agents 是具有明确的目标的,所有的 agents 都能感知自己的环境,并根据目标来指导自己的行为,因此 RL 的另一个特点是它将 agents 和与其交互的不确定的环境视为是一个完整的问题。在 RL 问题中,有四个非常重要的概念:
(1)规则(policy)
Policy 定义了 agents 在特定的时间特定的环境下的行为方式,可以视为是从环境状态到行为的映射,常用
π
\pi
π
确定性的 policy(Deterministic policy):
a
=
π
(
s
)
a=\pi(s)
a = π ( s )
π
(
a
∣
s
)
=
P
[
A
t
=
a
∣
S
t
=
t
]
\pi(a|s)=P[A_t=a|S_t=t]
π ( a ∣ s ) = P [ A t = a ∣ S t = t ]
其中,
t
t
t
t
=
0
,
1
,
2
,
3
,
…
…
t=0,1,2,3,……
t = 0 , 1 , 2 , 3 , … …
S
t
∈
S
S_t\in{\mathcal{S}}
S t ∈ S
S
{\mathcal{S}}
S
S
t
S_t
S t
t
t
t
s
s
s
A
t
∈
A
(
S
t
)
A_t\in{\mathcal{A}}(S_t)
A t ∈ A ( S t )
A
(
S
t
)
{\mathcal{A}}(S_t)
A ( S t )
S
t
S_t
S t
A
t
A_t
A t
t
t
t
a
a
a
(2)奖励信号(a reward signal)
Reward 就是一个标量值,是每个 time step 中环境根据 agent 的行为返回给 agent 的信号,reward 定义了在该情景下执行该行为的好坏,agent 可以根据 reward 来调整自己的 policy。常用
R
R
R
(3)值函数(value function)
Reward 定义的是立即的收益,而 value function 定义的是长期的收益,它可以看作是累计的 reward,常用
v
v
v
(4)环境模型(a model of the environment)
整个Agent和Environment交互的过程可以用下图来表示:
其中,
t
t
t
t
=
0
,
1
,
2
,
3
,
…
…
t=0,1,2,3,……
t = 0 , 1 , 2 , 3 , … …
S
t
∈
S
S_t\in{\mathcal{S}}
S t ∈ S
S
{\mathcal{S}}
S
A
t
∈
A
(
S
t
)
A_t\in{\mathcal{A}}(S_t)
A t ∈ A ( S t )
A
(
S
t
)
{\mathcal{A}}(S_t)
A ( S t )
S
t
S_t
S t
R
t
∈
R
∈
R
R_t\in{\mathcal{R}}\in{\Bbb R}
R t ∈ R ∈ R
在每个时间步骤中,agent 都会实现一个从 states 到每个可能的 actions 的 probabilities 的映射,这个映射函数就称作是这个 agent 的
p
o
l
i
c
y
policy
p o l i c y
π
t
\pi_t
π t
π
t
(
a
∣
s
)
\pi_t(a|s)
π t ( a ∣ s )
S
t
=
s
S_t=s
S t = s
A
t
=
a
A_t=a
A t = a
其实概括的来说,不同的 RL 方法的主要不同就是利用 experience 来改变自己的
π
t
\pi_t
π t
在RL中,goals和rewards是两个重要的概念,在每个时间步骤中,环境返回给 Agent 的 reward 就是一个简单的数值,而 Agent 的 goal 就是最大化它接受到的所有的 reward signal 的和,也就是说,它的目的不是最大化当前步骤的立即获得的 reward ,而是一个长远的目标,并且需要注意的是,这个 reward 是由 environment 定义的而非 Agent。
刚刚提到,Agent 的 goal 就是最大化它接受到的所有的 reward signal 的和,那么就需要将这个目标值用函数的形式来表达出来,这里令时间
t
t
t
R
t
+
1
,
R
t
+
2
,
R
t
+
3
,
…
R_{t+1}, R_{t+2}, R_{t+3}, \ldots
R t + 1 , R t + 2 , R t + 3 , …
G
t
G_t
G t
G
t
≐
R
t
+
1
+
R
t
+
2
+
R
t
+
3
+
…
+
R
T
(
1
)
G_t \doteq R_{t+1}+R_{t+2}+R_{t+3}+\ldots +R_T \ \ \ \ \ \ \ \ \ (1)
G t ≐ R t + 1 + R t + 2 + R t + 3 + … + R T ( 1 )
其中,
T
T
T
这时就需要再引入一个新的概念
e
p
i
s
o
d
e
s
episodes
e p i s o d e s
t
e
r
m
i
n
a
l
s
t
a
t
e
terminal\ state
t e r m i n a l s t a t e
e
p
i
s
o
d
i
c
t
a
s
k
s
episodic\ tasks
e p i s o d i c t a s k s
S
{\mathcal{S}}
S
S
+
{\mathcal{S}}^+
S +
与 episode task 相对应的另外一种是
c
o
n
t
i
n
u
i
n
g
t
a
s
k
s
continuing\ tasks
c o n t i n u i n g t a s k s
T
=
∞
T=\infty
T = ∞
还有一个比较重要的概念是
d
i
s
c
o
u
n
t
i
n
g
discounting
d i s c o u n t i n g
A
t
A_t
A t
d
i
s
c
o
u
n
t
e
d
r
e
t
u
r
n
discounted\ return
d i s c o u n t e d r e t u r n
G
t
≐
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
…
=
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
G_t \doteq R_{t+1}+{\gamma}R_{t+2}+{\gamma}^2R_{t+3}+\ldots =\sum_{k=0}^{\infty}{\gamma_kR_{t+k+1}}
G t ≐ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … = k = 0 ∑ ∞ γ k R t + k + 1
其中
0
≤
γ
≤
1
0\leq\gamma\leq1
0 ≤ γ ≤ 1
d
i
s
c
o
u
n
t
r
a
t
e
discount\ rate
d i s c o u n t r a t e
k
k
k
γ
k
−
1
\gamma^{k-1}
γ k − 1
γ
<
1
\gamma<1
γ < 1
{
R
k
}
\{R_k\}
{ R k }
G
t
G_t
G t
γ
=
0
\gamma=0
γ = 0
A
t
A_t
A t
R
t
+
1
R_{t+1}
R t + 1
γ
\gamma
γ
1
1
1
增强学习任务大致可以分为两类:一类是 agent-environment 交互过程可以自然结束的 episodes 或者称为是 episodic tasks,另外一类是不能自然结束的 continuing tasks, 其中第一种任务的数学表达较为简单,因为每一个 action 只会影响有限数量的 rewards。
下面先介绍 episode 的数学表达形式,假设这里考虑的是一系列具有有限时间步骤的 episodes,每个 episode 的时间步骤都是从
0
0
0
S
t
,
i
S_{t,i}
S t , i
i
i
i
t
t
t
A
t
,
i
,
R
t
,
i
,
π
t
,
i
,
T
i
A_{t,i}, R_{t,i}, \pi_{t,i}, T_{i}
A t , i , R t , i , π t , i , T i
i
i
i
其实 episodic 和 continuing tasks 是可以表达成统一的形式的,比如考虑下图这种转换形式,它的特殊在于具有一个特殊的
a
b
s
o
r
b
i
n
g
s
t
a
t
e
absorbing\ state
a b s o r b i n g s t a t e
S
0
S_0
S 0
+
1
,
+
1
,
+
1
,
0
,
0
,
0
,
…
+1,+1,+1,0,0,0, \ldots
+ 1 , + 1 , + 1 , 0 , 0 , 0 , …
T
T
T
T
=
3
T=3
T = 3
因此,可以将这两种情况统一表达成:
G
t
≐
∑
k
=
0
T
−
t
−
1
γ
k
R
t
+
k
+
1
G_t \doteq \sum_{k=0}^{T-t-1}{\gamma_kR_{t+k+1}}
G t ≐ k = 0 ∑ T − t − 1 γ k R t + k + 1
其中,包含了
T
=
∞
T=\infty
T = ∞
γ
=
1
\gamma=1
γ = 1
在 RL 框架中,agent是依据环境的状态来做决定,那么这个环境的 state signal 能说明什么?不能说明什么呢?在 RL 中比较关心的一种情况是环境具有 Markov property 的情景。
通常,将能够成功保留所有相关信息的状态信号就称为是
M
a
r
k
o
v
Markov
M a r k o v
M
a
r
k
o
v
p
r
o
p
e
r
t
y
Markov\ property
M a r k o v p r o p e r t y
P
r
{
S
t
+
1
=
s
′
,
R
t
+
1
=
r
∣
S
0
,
A
0
,
R
1
,
…
,
S
t
−
1
,
A
t
−
1
,
R
t
,
S
t
,
A
t
}
Pr\{S_{t+1}=s\prime,R_{t+1}=r|S_0,A_0,R_1,\ldots,S_{t-1},A_{t-1},R_t,S_t,A_t\}
P r { S t + 1 = s ′ , R t + 1 = r ∣ S 0 , A 0 , R 1 , … , S t − 1 , A t − 1 , R t , S t , A t }
如果这个状态信号具有 $ Markov\ property$,那么环境的动态性完全由上一个状态和行为来决定,即:
p
(
s
′
,
r
∣
s
,
a
)
≐
P
r
{
S
t
+
1
=
s
′
,
R
t
+
1
=
r
∣
S
t
=
s
,
A
t
=
a
}
p(s\prime,r|s,a)\doteq Pr\{S_{t+1}=s\prime, R_{t+1}=r| S_t=s, A_t=a\}
p ( s ′ , r ∣ s , a ) ≐ P r { S t + 1 = s ′ , R t + 1 = r ∣ S t = s , A t = a }
如果满足这个属性,那么预测下一个 states 和期望的 reward 只需利用当前的状态和 action 即可,而不需要历史信息。
满足 Markov property 的 RL 任务就称作是
M
a
r
k
o
v
d
e
c
i
s
i
o
n
p
r
o
c
e
s
s
Markov\ decision\ process
M a r k o v d e c i s i o n p r o c e s s
M
D
P
MDP
M D P
f
i
n
i
t
e
M
a
r
k
o
v
d
e
c
i
s
i
o
n
p
r
o
c
e
s
s
finite\ Markov\ decision\ process
f i n i t e M a r k o v d e c i s i o n p r o c e s s
f
i
n
i
t
e
M
D
P
finite\ MDP
f i n i t e M D P
对一个 Markon 的状态
s
s
s
s
′
s\prime
s ′
s
t
a
t
e
t
r
a
n
s
i
t
i
o
n
p
r
o
b
a
b
i
l
i
t
y
state transition\ probability
s t a t e t r a n s i t i o n p r o b a b i l i t y
P
s
s
′
=
P
[
S
t
+
1
=
s
′
∣
S
t
=
s
]
{\mathcal{P}}_{ss\prime }=P[S_{t+1}=s\prime|S_t=s]
P s s ′ = P [ S t + 1 = s ′ ∣ S t = s ]
状态转移矩阵(
S
t
a
t
e
t
r
a
n
s
i
t
i
o
n
m
a
t
r
i
x
State\ \ transition\ matrix
S t a t e t r a n s i t i o n m a t r i x
P
{\mathcal{P}}
P
s
s
s
s
′
s\prime
s ′
显然矩阵的每一行的和为1。
对于一个特定的 finite MDP,它是由状态行为集合和环境的 one-step dynamics 定义的,给定状态
s
s
s
a
a
a
r
r
r
p
(
s
′
,
r
∣
s
,
a
)
≐
P
r
{
S
t
+
1
=
s
′
,
R
t
+
1
=
r
∣
S
t
=
s
,
A
t
=
a
}
(
2
)
p(s\prime,r|s,a)\doteq Pr\{S_{t+1}=s\prime, R_{t+1}=r| S_t=s, A_t=a\}\ \ \ \ \ \ \ \ (2)
p ( s ′ , r ∣ s , a ) ≐ P r { S t + 1 = s ′ , R t + 1 = r ∣ S t = s , A t = a } ( 2 )
这个等式完全定义了一个 finite MDP 的动态性,之后的理论基本都是建立在假设环境是 finite MDP 的基础上的。
有了等式(2),就可以计算我希望知道的很多量,如:
r
(
s
,
a
)
≐
E
[
R
t
+
1
∣
S
t
=
s
,
A
t
=
a
]
=
∑
r
∈
R
r
∑
s
′
∈
S
p
(
s
′
,
r
∣
s
,
a
)
r(s,a)\doteq E[R_{t+1}| S_t=s, A_t=a] =\sum_{r\in {\mathcal{R}}}r\sum_{s\prime \in{\mathcal{S}}}{p(s\prime,r|s,a)}
r ( s , a ) ≐ E [ R t + 1 ∣ S t = s , A t = a ] = r ∈ R ∑ r s ′ ∈ S ∑ p ( s ′ , r ∣ s , a )
s
t
a
t
e
−
t
r
a
n
s
i
t
i
o
n
p
r
o
b
a
b
i
l
i
t
i
e
s
state-transition probabilities
s t a t e − t r a n s i t i o n p r o b a b i l i t i e s
p
(
s
′
∣
s
,
a
)
≐
P
r
{
S
t
+
1
=
s
′
∣
S
t
=
s
,
A
t
=
a
}
=
∑
r
∈
R
p
(
s
′
,
r
∣
s
,
a
)
p(s\prime|s,a) \doteq Pr\{S_{t+1}=s\prime | S_t=s, A_t=a\}=\sum_{r\in {\mathcal{R}}}{p(s\prime,r|s,a)}
p ( s ′ ∣ s , a ) ≐ P r { S t + 1 = s ′ ∣ S t = s , A t = a } = r ∈ R ∑ p ( s ′ , r ∣ s , a )
r
(
s
,
a
,
s
′
)
≐
E
[
S
t
=
s
∣
S
t
=
s
,
A
t
=
a
,
S
t
+
1
=
s
′
]
=
∑
r
∈
R
r
p
(
s
′
,
r
∣
s
,
a
)
p
(
s
′
∣
s
,
a
)
r(s,a,s\prime) \doteq E[S_t=s | S_t=s, A_t=a, S_{t+1}=s\prime] = \frac{\sum_{r\in {\mathcal{R}}}{rp(s\prime,r|s,a)}}{ p(s\prime|s,a)}
r ( s , a , s ′ ) ≐ E [ S t = s ∣ S t = s , A t = a , S t + 1 = s ′ ] = p ( s ′ ∣ s , a ) ∑ r ∈ R r p ( s ′ , r ∣ s , a )
对 finite MDP 来说,
t
r
a
n
s
i
t
i
o
n
g
r
a
p
h
transition\ graph
t r a n s i t i o n g r a p h
s
t
a
t
e
n
o
d
e
s
state\ nodes
s t a t e n o d e s
a
c
t
i
o
n
n
o
d
e
s
action\ nodes
a c t i o n n o d e s
s
s
s
a
a
a
s
′
s\prime
s ′
p
(
s
′
∣
s
,
a
)
p(s\prime|s,a)
p ( s ′ ∣ s , a )
r
(
s
,
a
,
s
′
)
r(s,a,s\prime)
r ( s , a , s ′ )
在RL问题中,
v
a
l
u
e
f
u
n
c
t
i
o
n
value\ function
v a l u e f u n c t i o n
这里还按照之前的符号定义,令
π
\pi
π
s
s
s
a
a
a
π
(
a
∣
s
)
\pi(a|s)
π ( a ∣ s )
s
s
s
a
a
a
π
\pi
π
s
s
s
v
a
l
u
e
value
v a l u e
v
π
(
s
)
v_{\pi}(s)
v π ( s )
s
s
s
π
\pi
π
v
π
(
s
)
≐
E
π
[
G
t
∣
S
t
=
s
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
]
v_{\pi}(s) \doteq {\Bbb E}_{\pi}[G_t|S_t=s]= {\Bbb E}_{\pi}[\sum_{k=0}^{\infty}{\gamma_kR_{t+k+1}}|S_t=s]
v π ( s ) ≐ E π [ G t ∣ S t = s ] = E π [ k = 0 ∑ ∞ γ k R t + k + 1 ∣ S t = s ]
其中,
E
π
[
⋅
]
{\Bbb E}_{\pi}[\cdot]
E π [ ⋅ ]
π
\pi
π
t
t
t
v
π
v_\pi
v π
s
t
a
t
e
−
v
a
l
u
e
f
u
n
c
t
i
o
n
f
o
r
p
o
l
i
c
y
π
state-value\ function\ for\ policy\ \pi
s t a t e − v a l u e f u n c t i o n f o r p o l i c y π
相似的就可以定义在规则
π
\pi
π
s
s
s
a
a
a
q
π
(
s
,
a
)
q_\pi(s,a)
q π ( s , a )
s
s
s
π
\pi
π
s
s
s
a
a
a
q
π
(
s
,
a
)
≐
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
,
A
t
=
a
]
q_{\pi}(s,a) \doteq {\Bbb E}_{\pi}[G_t|S_t=s, A_t=a] = {\Bbb E}_{\pi} [\sum_{k=0}^{\infty}{\gamma_kR_{t+k+1}}|S_t=s, A_t=a]
q π ( s , a ) ≐ E π [ G t ∣ S t = s , A t = a ] = E π [ k = 0 ∑ ∞ γ k R t + k + 1 ∣ S t = s , A t = a ]
通常将函数
q
π
q_\pi
q π
a
c
t
i
o
n
−
v
a
l
u
e
f
u
n
c
t
i
o
n
f
o
r
p
o
l
i
c
y
π
action-value\ function\ for\ policy\ \pi
a c t i o n − v a l u e f u n c t i o n f o r p o l i c y π
通常函数
v
π
v_\pi
v π
q
π
q_\pi
q π
s
s
s
s
s
s
a
a
a
v
π
(
s
)
v_\pi(s)
v π ( s )
q
π
(
s
,
a
)
q_\pi(s,a)
q π ( s , a )
M
o
n
t
e
C
a
r
l
o
m
e
t
h
o
d
s
Monte\ Carlo\ methods
M o n t e C a r l o m e t h o d s
在RL和动态编程(dynamic programming)中使用的 value function 具有一个重要的属性,即它们满足一种递归关系。对于规则
π
\pi
π
s
s
s
s
s
s
其中最后一个等式为:
v
π
(
s
)
≐
∑
a
π
(
a
∣
s
)
∑
s
′
,
r
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
v
π
(
s
′
)
]
,
∀
s
∈
S
(
3
)
v_{\pi}(s) \doteq \sum_a\pi(a|s)\sum_{s\prime,r}{p(s\prime,r|s,a)[r+\gamma v_{\pi}(s\prime)]},\ \ \forall s\in {\mathcal{S}}\ \ \ \ \ \ \ \ (3)
v π ( s ) ≐ a ∑ π ( a ∣ s ) s ′ , r ∑ p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] , ∀ s ∈ S ( 3 )
其中
a
∈
A
(
s
)
a\in{\mathcal{A}}(s)
a ∈ A ( s )
s
′
∈
S
s\prime \in{\mathcal{S}}
s ′ ∈ S
v
π
v_{\pi}
v π
B
e
l
l
m
a
n
e
q
u
a
t
i
o
n
Bellman\ equation
B e l l m a n e q u a t i o n
b
a
c
k
u
p
d
i
a
g
r
a
m
s
backup\ diagrams
b a c k u p d i a g r a m s
s
s
s
(
s
,
a
)
(s,a)
( s , a )
s
′
s\prime
s ′
r
r
r
结合
b
a
c
k
u
p
d
i
a
g
r
a
m
s
backup\ diagrams
b a c k u p d i a g r a m s
B
e
l
l
m
a
n
e
q
u
a
t
i
o
n
Bellman\ equation
B e l l m a n e q u a t i o n
b
a
c
k
u
p
d
i
a
g
r
a
m
s
backup\ diagrams
b a c k u p d i a g r a m s
b
a
c
k
u
p
backup
b a c k u p
b
a
c
k
back
b a c k
解决RL任务,就是找到一种 policy 来获得最大的长远 reward,对于有限的MDPs,可以精确地定义一种优化的规则,上面介绍的 value function 定义了 policies 之间的一种偏序关系,因此可以利用它来定义
o
p
t
i
m
a
l
p
o
l
i
c
y
optimal\ policy
o p t i m a l p o l i c y
定义规则
π
\pi
π
π
′
\pi\prime
π ′
π
\pi
π
π
′
\pi\prime
π ′
π
≥
π
′
⇔
v
π
(
s
)
≥
v
π
′
(
s
)
∀
s
∈
S
\pi \geq \pi\prime \Leftrightarrow v_\pi(s) \geq v_\pi\prime (s)\ \ \ \forall s\in{\mathcal{S}}
π ≥ π ′ ⇔ v π ( s ) ≥ v π ′ ( s ) ∀ s ∈ S
则
o
p
t
i
m
a
l
p
o
l
i
c
y
optimal\ policy
o p t i m a l p o l i c y
π
∗
\pi_{\ast}
π ∗
同样地,也可以定义
o
p
t
i
m
a
l
s
t
a
t
e
−
v
a
l
u
e
f
u
n
c
t
i
o
n
optimal\ state-value\ function
o p t i m a l s t a t e − v a l u e f u n c t i o n
v
∗
v_{\ast}
v ∗
v
∗
≐
m
a
x
π
v
π
(
s
)
∀
s
∈
S
v_{\ast} \doteq max_\pi{v_\pi(s)}\ \ \ \ \forall s\in{\mathcal{S}}
v ∗ ≐ m a x π v π ( s ) ∀ s ∈ S
优化的 policies 也具有相同的
o
p
t
i
m
a
l
a
c
t
i
o
n
−
v
a
l
u
e
f
u
n
c
t
i
o
n
optimal\ action-value\ function
o p t i m a l a c t i o n − v a l u e f u n c t i o n
q
∗
q_{\ast}
q ∗
q
∗
(
s
,
a
)
≐
m
a
x
π
q
π
(
s
,
a
)
∀
s
∈
S
,
∀
a
∈
A
(
s
)
q_{\ast}(s,a) \doteq max_\pi{q_\pi(s,a)}\ \ \ \ \forall s\in{\mathcal{S}},\forall a\in{\mathcal{A}}(s)
q ∗ ( s , a ) ≐ m a x π q π ( s , a ) ∀ s ∈ S , ∀ a ∈ A ( s )
对于 state-action 对
(
s
,
a
)
(s,a)
( s , a )
s
s
s
a
a
a
q
∗
q_{\ast}
q ∗
v
∗
v_{\ast}
v ∗
q
∗
(
s
,
a
)
≐
E
[
R
t
+
1
+
γ
v
∗
(
S
t
+
1
)
∣
S
t
=
s
,
A
t
=
a
]
q_{\ast}(s,a) \doteq {\Bbb E}[R_{t+1}+\gamma v_{\ast}(S_{t+1})|S_t=s,A_t=a]
q ∗ ( s , a ) ≐ E [ R t + 1 + γ v ∗ ( S t + 1 ) ∣ S t = s , A t = a ]
上一小节介绍了优化的 value function和优化的 policies,但在真实情况中,即使拥有了环境动态性完整的精确的模型,也很难简单地求解 Bellman优化方程计算出优化的 policy。并且,当状态和行为集合很大时,也会需要非常大的内存,因此可用的内存也是直接求解的一个限制因素。解决这个的问题的办法就是采用近似的求解方法。
参考文献