MDPs are a classical formalization of sequential decision making. MDPs are a mathmatically idealized form of the reinforcement learning problem for which precise theoretical statements can be made. As in all of artificial intelligence, there is a tension between breadth of applicability and mathematical tractability.
1. The Agent-Environment Interface
The learner and decision maker is called the agent.
The thing it interacts with, comprising everything outside the agent, is called the environment.
(We uses the terms agent, environment, and action instead of the engineers’ terms controller, controlled system(or plant), and control signal because they are meaningful to a wider audience.)
In particular, the boundary between agent and environment is typically not the same as the physical boudary of robot’s or animal body. The general rule we follow is that anything that cannot be changed arbitrarily by the agent is considered to be outside of it and thus part of its environment.
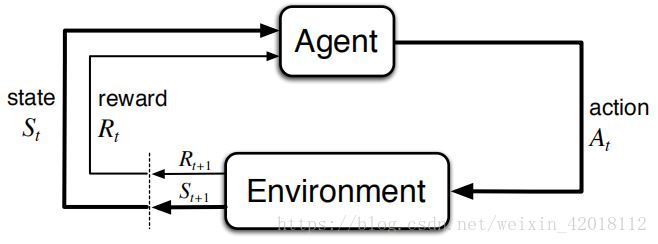
Figure 1: The agent-environment interaction in a Markov decision process.
The probabilities given by the four-argument function
completely characterize the dynamics of a finite MDP:
From it, we can compute anything else one might want to know about the environment.
For example:
- the state-transition probabilities
- the expected rewards for state-action pairs
- the expected rewards for state-action-next-state triples
The MDP framework is a considerable abstraction of the problem of goal-directed learning from interaction. Any problem of learning goal-directed behevior can be reduced to three signals passing back and forth between an agent and its environment: one signal to represent the choices made by the agent (the actions), one signal to represent the basis on which choices are made (the states), and one signal to defineteh agent’s goal (the rewards).
2. Goals and Rewards
That all of what we mean by goals and purposes can be well thought of as the maximization of othe expected value of the cumulative sum of a receive scalar signal (called reward).
It is thus critical that the rewards we set up truly indicate what we want accomplished. In paricular, the reward signal is not the place to impart to the agent prior knowledge about how to achieve what we want it to do.
3. Returns and Episodes
In general, we seek to maximize the expected return, where the return, denoted
, is defined as some specific function of the reward sequence.
The discount rate determines the present value of future rewards: a reward received k time steps in the future is worth only times what it would be worth if it were reveived immediately.
If , the infibite sum above have a finite value as long as the reward sequence bounded.
If , the agent is “myopic” in being concerned only with maximizing immediate rewards.
Returns at successive time steps are related to each other in a way that is important for the theory and algorithms of reinforcement learning:
5. Policies and Value Functions
Almost all reinforcement learning algorithms invlove estimating value functions—functions of states (or of state-action pairs) that esimate how good it is for the agent to be in a given state (or how good it is to perform a given action in a given state).
Formally, a policy is a mapping from states to probabilities of selecting each possible action.
The value of a state
under a policy
, denoted
, is the expected return when starting in
and following
thereafter.
state-value function for policy
:
Similarly, we difine the value of taking action
in state
under a policy
, denoted
, as the expected return starting from
, taking the action
, and thereafter following policy
.
action-value function for policy
:
For any policy
and any state
, the following consistency condition holds between the value of
and the value of its possible successor states:
Equation above is the Bellman equation for . It expresses a relationship between the value of a state and the values of its successor states.
A fundamental property of value function used throughout RL is that they satisfy recursive relationships similar to that which we have already established for the return.