本次总结中的 1-4 小节主要介绍了增强学习中的一些重要的概念,如:Goals、Rewards、Returns、Episode 等,第 5 小节介绍了 Markov Property,第 6 小节介绍了 Markov Decision Processes,第 7、8 小节介绍了 RL 中的 Value Function。可以说这次总结也是为之后介绍 RL 相关算法做了铺垫。
1 增强学习中的一般模型
在强化学习(Reinforcement Learning, RL)初步介绍中曾经介绍了 RL 问题的一般模型,下面再简单回顾一下:
在 RL 中,agents 是具有明确的目标的,所有的 agents 都能感知自己的环境,并根据目标来指导自己的行为,因此 RL 的另一个特点是它将 agents 和与其交互的不确定的环境视为是一个完整的问题。在 RL 问题中,有四个非常重要的概念:
(1)规则(policy)
Policy 定义了 agents 在特定的时间特定的环境下的行为方式,可以视为是从环境状态到行为的映射,常用
π
π来表示。policy 可以分为两类:
确定性的 policy(Deterministic policy):
a=π(s)
a=π(s)
随机性的 policy(Stochastic policy):
π(a|s)=P[At=a|St=t]
π(a|s)=P[At=a|St=t]
其中,
t
t是时间点,
t=0,1,2,3,……
t=0,1,2,3,……
St∈S
St∈S,
S
S是环境状态的集合,
St
St代表时刻
t
t 的状态,
s
s 代表其中某个特定的状态;
At∈A(St)
At∈A(St),
A(St)
A(St) 是在状态
St
St 下的 actions 的集合,
At
At 代表时刻
t
t 的行为,
a
a 代表其中某个特定的行为。
(2)奖励信号(a reward signal)
Reward 就是一个标量值,是每个 time step 中环境根据 agent 的行为返回给 agent 的信号,reward 定义了在该情景下执行该行为的好坏,agent 可以根据 reward 来调整自己的 policy。常用
R
R 来表示。
(3)值函数(value function)
Reward 定义的是立即的收益,而 value function 定义的是长期的收益,它可以看作是累计的 reward,常用
v
v 来表示。
(4)环境模型(a model of the environment)
整个Agent和Environment交互的过程可以用下图来表示:
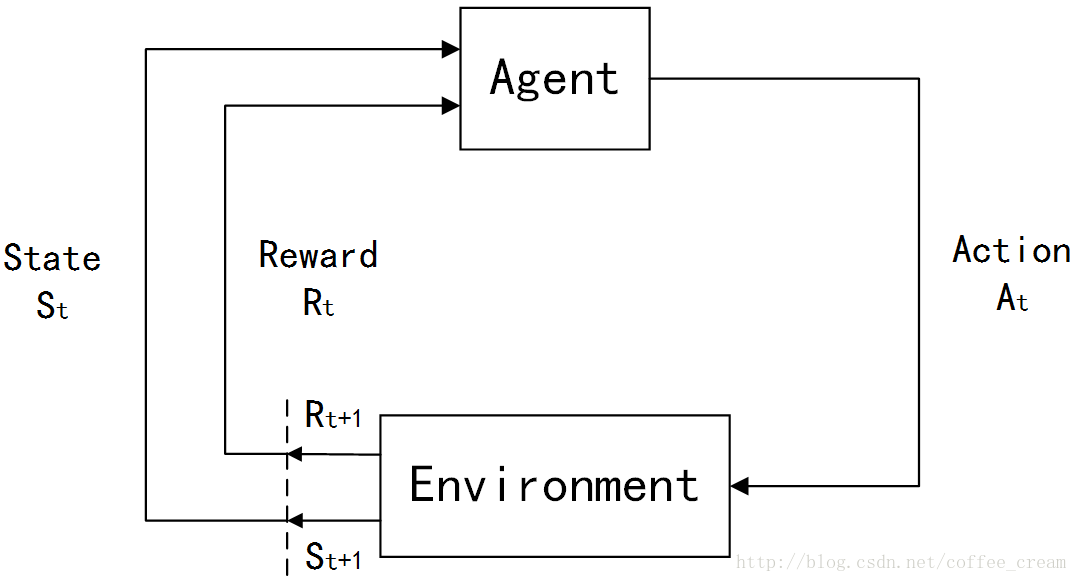
其中,
t
t 是时间点,
t=0,1,2,3,……
t=0,1,2,3,……
St∈S
St∈S,
S
S 是环境状态的集合;
At∈A(St)
At∈A(St),
A(St)
A(St) 是在状态
St
St 下的 actions 的集合;
Rt∈R∈R
Rt∈R∈R 是数值型的 reward。
在每个时间步骤中,agent 都会实现一个从 states 到每个可能的 actions 的 probabilities 的映射,这个映射函数就称作是这个 agent 的
policy
policy,常用符号
πt
πt 来表示,
πt(a|s)
πt(a|s) 指的就是在状态
St=s
St=s 下选择执行
At=a
At=a 的概率。
其实概括的来说,不同的 RL 方法的主要不同就是利用 experience 来改变自己的
πt
πt 的方法,毕竟RL就是从 experience 中进行学习的一系列方法。
2 Goals 和 Rewards
在RL中,goals和rewards是两个重要的概念,在每个时间步骤中,环境返回给 Agent 的 reward 就是一个简单的数值,而 Agent 的 goal 就是最大化它接受到的所有的 reward signal 的和,也就是说,它的目的不是最大化当前步骤的立即获得的 reward ,而是一个长远的目标,并且需要注意的是,这个 reward 是由 environment 定义的而非 Agent。
3 Returns
刚刚提到,Agent 的 goal 就是最大化它接受到的所有的 reward signal 的和,那么就需要将这个目标值用函数的形式来表达出来,这里令时间
t
t 获得的 reward 为
Rt+1,Rt+2,Rt+3,…
Rt+1,Rt+2,Rt+3,… ,令
Gt
Gt 代表期望的 return,那么最简单的 return 的形式为:
Gt≐Rt+1+Rt+2+Rt+3+…+RT (1)
Gt≐Rt+1+Rt+2+Rt+3+…+RT (1)
其中,
T
T
代表最后一个的时间步骤。
这时就需要再引入一个新的概念
episodes
episodes
,翻译成中文的话就是“片段、插曲”的意思,这里指的是一个可以自然结束的 agent-environment 交互的过程,每个 episode 都会在一个特殊的状态下结束,这个状态就称作是
terminal state
terminal state
,因此每个 episode 的相同点是它们都以 terminal state 来结束,不同就是每个 episode 获得的 reward 不同,采用 episodes 形式的 tasks 就称为是
episodic tasks
episodic tasks
,在episodic tasks 中,常常将所有非终止的状态的集合记为是
S
S
,而把包含终止状态的所有状态的集合记为是
S+
S+
。
与 episode task 相对应的另外一种是
continuing tasks
continuing tasks
,它们指的是那些不会自然结束,会一直持续进行的 task,这时return公式(1)中的
T=∞
T=∞
。
还有一个比较重要的概念是
discounting
discounting
,它是对未来不同时刻的 reward 赋予不同的权重,距离现在较近的 reward 的权重较高,而时间越远的权重越低,这时选择行为
At
At
的准则就是最大化期望的
discounted return
discounted return
:
Gt≐Rt+1+γRt+2+γ2Rt+3+…=∑k=0∞γkRt+k+1
Gt≐Rt+1+γRt+2+γ2Rt+3+…=∑k=0∞γkRt+k+1
其中
0≤γ≤1
0≤γ≤1
称为是
discount rate
discount rate
,它代表未来第
k
k
步的 reward 的价值只是当前立即获得的 reward 的
γk−1
γk−1
倍,若
γ<1
γ<1
,则当序列
{Rk}
{Rk}
有界的时候
Gt
Gt
可以得到一个有限的值,若
γ=0
γ=0
,则认为这个 agent 是“myopic”(目光短浅的),它只关心当前的 rewards,选择下一个
At
At
的准则就是最大化
Rt+1
Rt+1
。
γ
γ
越趋近于
1
1
,则这个 agent 越是具有“远见的”。
4 Episodic 和 Continuing Tasks 的统一表达形式
增强学习任务大致可以分为两类:一类是 agent-environment 交互过程可以自然结束的 episodes 或者称为是 episodic tasks,另外一类是不能自然结束的 continuing tasks, 其中第一种任务的数学表达较为简单,因为每一个 action 只会影响有限数量的 rewards。
下面先介绍 episode 的数学表达形式,假设这里考虑的是一系列具有有限时间步骤的 episodes,每个 episode 的时间步骤都是从
0
0 开始标记的,这里用
St,i
St,i 来代表第
i
i 个 episode 在第
t
t 时刻的状态,这种表达方式同样可以扩展到
At,i,Rt,i,πt,i,Ti
At,i,Rt,i,πt,i,Ti 等,之后的介绍中如果没有特别的标定
i
i,代表这个符号针对的是一个任意的 episode,它可以推广到所有的 episodes。
其实 episodic 和 continuing tasks 是可以表达成统一的形式的,比如考虑下图这种转换形式,它的特殊在于具有一个特殊的
absorbing state
absorbing state,即图中用黑色阴影标识的状态,它的特点是这个状态只能转换到自己本身,而不能转换成其他的状态,从初始状态
S0
S0 开始,它获得的 reward 序列为
+1,+1,+1,0,0,0,…
+1,+1,+1,0,0,0,…,则对这个序列求和得到的值与对前
T
T (这里
T=3
T=3)个 reward 求和得到的结果相同。
因此,可以将这两种情况统一表达成:
Gt≐∑k=0T−t−1γkRt+k+1
Gt≐∑k=0T−t−1γkRt+k+1
其中,包含了
T=∞
T=∞
和
γ=1
γ=1
的情况(但是这俩不能同时满足)。
5 马尔可夫性质
在 RL 框架中,agent是依据环境的状态来做决定,那么这个环境的 state signal 能说明什么?不能说明什么呢?在 RL 中比较关心的一种情况是环境具有 Markov property 的情景。
通常,将能够成功保留所有相关信息的状态信号就称为是
Markov
Markov,或者称是具有
Markov property
Markov property。这种性质怎样用数学表达式来表示呢?我们知道,一般环境的下一个状态是由之前所有的状态来决定的,这种动态性可以表示成一个联合概率分布:
Pr{St+1=s′,Rt+1=r|S0,A0,R1,…,St−1,At−1,Rt,St,At}
Pr{St+1=s′,Rt+1=r|S0,A0,R1,…,St−1,At−1,Rt,St,At}
如果这个状态信号具有
Markov property
Markov property
,那么环境的动态性完全由上一个状态和行为来决定,即:
p(s′,r|s,a)≐Pr{St+1=s′,Rt+1=r|St=s,At=a}
p(s′,r|s,a)≐Pr{St+1=s′,Rt+1=r|St=s,At=a}
如果满足这个属性,那么预测下一个 states 和期望的 reward 只需利用当前的状态和 action 即可,而不需要历史信息。
6 Markov Decision Processes
满足 Markov property 的 RL 任务就称作是
Markov decision process
Markov decision process,简称为
MDP
MDP,如果状态和行为空间都是有限的,那么就称为是
finite Markov decision process
finite Markov decision process,简称为
finite MDP
finite MDP。Finite MDPs 在 RL 理论中是非常重要的。
对一个 Markon 的状态
s
s 和下一个状态
s′
s′,状态转移概率(
statetransition probability
statetransition probability)定义为:
Pss′=P[St+1=s′|St=s]
Pss′=P[St+1=s′|St=s]
状态转移矩阵(
State transition matrix
State transition matrix
)
P
P
定义了从所有状态
s
s
到所有可能的下一个状态
s′
s′
的转移概率,可以写作为:
显然矩阵的每一行的和为1。
对于一个特定的 finite MDP,它是由状态行为集合和环境的 one-step dynamics 定义的,给定状态
s
s 和行为
a
a,下一个可能的状态
s′
s′ 和奖励
r
r 对的概率为:
p(s′,r|s,a)≐Pr{St+1=s′,Rt+1=r|St=s,At=a} (2)
p(s′,r|s,a)≐Pr{St+1=s′,Rt+1=r|St=s,At=a} (2)
这个等式完全定义了一个 finite MDP 的动态性,之后的理论基本都是建立在假设环境是 finite MDP 的基础上的。
有了等式(2),就可以计算我希望知道的很多量,如:
state-action 对的期望 rewards 为:
r(s,a)≐E[Rt+1|St=s,At=a]=∑r∈Rr∑s′∈Sp(s′,r|s,a)
r(s,a)≐E[Rt+1|St=s,At=a]=∑r∈Rr∑s′∈Sp(s′,r|s,a)
状态转换概率(
state−transitionprobabilities
state−transitionprobabilities
)为:
p(s′|s,a)≐Pr{St+1=s′|St=s,At=a}=∑r∈Rp(s′,r|s,a)
p(s′|s,a)≐Pr{St+1=s′|St=s,At=a}=∑r∈Rp(s′,r|s,a)
state-action-next-state这个三元组合对应的期望 rewards 为:
r(s,a,s′)≐E[St=s|St=s,At=a,St+1=s′]=∑r∈Rrp(s′,r|s,a)p(s′|s,a)
r(s,a,s′)≐E[St=s|St=s,At=a,St+1=s′]=∑r∈Rrp(s′,r|s,a)p(s′|s,a)
对 finite MDP 来说,
transition graph
transition graph 是一种总结其动态性的有效方式,比如下图所示,其中大的空心圆圈代表的是状态节点(
state nodes
state nodes ),圈圈中字是状态的名称,而小的实心的圆圈代表的是行为节点(
action nodes
action nodes ),小圆圈旁边的字代表的是执行的行为,每条带箭头的线代表的是在状态
s
s 下选择行为
a
a 后转换到下一个状态
s′
s′ 的概率
p(s′|s,a)
p(s′|s,a) 和相应的回报值
r(s,a,s′)
r(s,a,s′)。
7 Value Functions
在RL问题中,
value function
value function 是一个重要的概念,几乎所有的 RL 算法都需要计算它,value function 是对 agent 的状态的评价,或者是对 state-action 对的评价,考虑到 agent 的 goal,不难想到这种评价一定是基于对未来期望的 rewards 的评价,当然,这种对未来期望的 rewards 依赖于 agent 选择的行为以及依据的 policy。
这里还按照之前的符号定义,令
π
π 代表 policy,即它是从每个状态
s
s 向每个行为
a
a 的映射,
π(a|s)
π(a|s) 代表在状态
s
s 下执行行为
a
a 的概率,则在规则
π
π 下状态
s
s 的
value
value 就用
vπ(s)
vπ(s) 来表示,它表示从状态
s
s 开始一直遵从规则
π
π 的期望 return,对于MDPs,可以得到:
vπ(s)≐Eπ[Gt|St=s]=Eπ[∑k=0∞γkRt+k+1|St=s]
vπ(s)≐Eπ[Gt|St=s]=Eπ[∑k=0∞γkRt+k+1|St=s]
其中,
Eπ[⋅]
Eπ[⋅]
指的是给定规则
π
π
下随机变量的期望值,并且时间
t
t
是个任意值,通常将函数
vπ
vπ
称为是
state−value function for policy π
state−value function for policy π
。
相似的就可以定义在规则
π
π 和状态
s
s 下选择行为
a
a 的 value 值,用符号
qπ(s,a)
qπ(s,a) 来表示,它表示的而是从状态
s
s 开始一直遵从规则
π
π,在状态
s
s 下选择行为
a
a 的期望 return,因此有:
qπ(s,a)≐Eπ[Gt|St=s,At=a]=Eπ[∑k=0∞γkRt+k+1|St=s,At=a]
qπ(s,a)≐Eπ[Gt|St=s,At=a]=Eπ[∑k=0∞γkRt+k+1|St=s,At=a]
通常将函数
qπ
qπ
称为是
action−value function for policy π
action−value function for policy π
。
通常函数
vπ
vπ 和
qπ
qπ 是从经验中估计得到的,常用的是取平均的方法,当处于状态
s
s 的次数或者在状态
s
s 下执行行为
a
a 的次数趋于无穷时,平均值就可以收敛到
vπ(s)
vπ(s) 或者
qπ(s,a)
qπ(s,a),因为这种方法是对真实返回值的许多次随机样本进行平均,因此称这种方法为
Monte Carlo methods
Monte Carlo methods,这种方法之后也会再详细介绍。
在RL和动态编程(dynamic programming)中使用的 value function 具有一个重要的属性,即它们满足一种递归关系。对于规则
π
π 和状态
s
s,状态
s
s 的 value 和他之后的状态的 value 满足下面的等式关系:
其中最后一个等式为:
vπ(s)≐∑aπ(a|s)∑s′,rp(s′,r|s,a)[r+γvπ(s′)], ∀s∈S (3)
vπ(s)≐∑aπ(a|s)∑s′,rp(s′,r|s,a)[r+γvπ(s′)], ∀s∈S (3)
其中
a∈A(s)
a∈A(s)
,
s′∈S
s′∈S
,公式(3) 称作是
vπ
vπ
的
Bellman equation
Bellman equation
,还有一个重要的概念是
backup diagrams
backup diagrams
,如下图的(a)所示,其中每个空心圆代表一个状态,每个实心圆代表一个 state-action 对,最初的状态即 root node 位于最上面,在每个状态
s
s
下,agent 可以从多个 action 中选择,每对
(s,a)
(s,a)
都会以一定的概率转化到状态
s′
s′
并伴随有回报值
r
r
。
结合
backup diagrams
backup diagrams,就可以更好的理解
Bellman equation
Bellman equation,从公式(3)可以看出,它对所有的可能情况进行了平均,并且每个部分的权重为它发生的概率。这种图之所以称作是
backup diagrams
backup diagrams,是因为它表达出了 RL 方法中 update 和
backup
backup 操作的基础,这些操作将 value 信息从下一个状态(或下一个 state-action 对)
back
back 到了当前的状态(或state-action 对)。
8 Optimal Value Functions
解决RL任务,就是找到一种 policy 来获得最大的长远 reward,对于有限的MDPs,可以精确地定义一种优化的规则,上面介绍的 value function 定义了 policies 之间的一种偏序关系,因此可以利用它来定义
optimal policy
optimal policy:
定义规则
π
π 与 规则
π′
π′ 相比更好或者相当是指,对所有的状态规则
π
π 的期望 return 都比 规则
π′
π′ 的大或者相等。即:
π≥π′⇔vπ(s)≥vπ′(s) ∀s∈S
π≥π′⇔vπ(s)≥vπ′(s) ∀s∈S
则
optimal policy
optimal policy
指的就是比其他所有 policies 都好或者相当的规则,用符号
π∗
π∗
来表示。
同样地,也可以定义
optimal state−value function
optimal state−value function
,用符号
v∗
v∗
来表示,定义式为:
v∗≐maxπvπ(s) ∀s∈S
v∗≐maxπvπ(s) ∀s∈S
优化的 policies 也具有相同的
optimal action−value function
optimal action−value function
,用
q∗
q∗
来表示,定义式为:
q∗(s,a)≐maxπqπ(s,a) ∀s∈S,∀a∈A(s)
q∗(s,a)≐maxπqπ(s,a) ∀s∈S,∀a∈A(s)
对于 state-action 对
(s,a)
(s,a)
,该函数给出了在状态
s
s
下执行
a
a
的期望 return,因此可以将
q∗
q∗
用
v∗
v∗
来表示:
q∗(s,a)≐E[Rt+1+γv∗(St+1)|St=s,At=a]
q∗(s,a)≐E[Rt+1+γv∗(St+1)|St=s,At=a]
9 Optimality and Approximation
上一小节介绍了优化的 value function和优化的 policies,但在真实情况中,即使拥有了环境动态性完整的精确的模型,也很难简单地求解 Bellman优化方程计算出优化的 policy。并且,当状态和行为集合很大时,也会需要非常大的内存,因此可用的内存也是直接求解的一个限制因素。解决这个的问题的办法就是采用近似的求解方法。
参考文献
[1] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto
[2] UCL Course on RL




