1.Markov decision processes formally describe an environment for reinforcement learning
-
Where the environment is fully observable
-
The current state completely characterises the process
-
Almost all RL problems can be formalised as MDPs
e.g. Optimal(最佳的) control primarily deals with continuous MDPs;Partially observable problems can be converted into MDPs;Bandits are MDPs with one state
2.Markov property(属性):
“The future is independent of the past given the present”
Definition:
A state ![]() is Markov if and only if
is Markov if and only if ![]()
-
The state captures all relevant information fronm the history.
-
Once the state is known,the history may be thrown away.
-
The state is a sufficient statistic of the future.
3.State Transition Matrix(状态转换矩阵):
For a Markov state s and successor state s', the state transition probability is defined by ![]() (s转移到s'的概率,状态转移概率)
(s转移到s'的概率,状态转移概率)
我们当前所处的state特征化了接下来会发生的一切,这样就告诉我们有一些良好定义的转移概率会告诉我如果我处于现在的状态,就会有对应的一些概率值指出,在那种状态下我将以一定的概率值转移到一定的后继状态。
State transition matrix P defines transition probabilities from all states s to all successor states s',

where each row of the matrix sums to 1.
(我们可以遵循这个转移的步骤,重复很多次,从这个转移概率中不断取样,可以得到一个MDP的大概过程)
4.A Markov process is a memoryless random process, i.e. a sequence of random states S1,S2,... with the Markov property.
Definition:
A Markov Process (or Markov Chain) is a tuple( 元组)<S,P>(定义了系统的动态变化过程,不需要actions和rewards来定义)
-
S is a (finite) set of states
-
P is a state transition probability matrix,
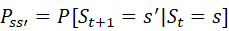
Example:Student Markov Chain

Sample episodes for Student Markov Chain starting from S1 = C1
S1,S2,...,ST
5.Markov Reward Process(引入reward逐渐过度到加强学习上)
A Markov reward process is a Markov chain with values
Definition:
A Markov Reward Process is a tuple <S,P,R,γ>
-
S is a finite set of states 状态空间
-
P is a state transition probability matrix, 转移概率
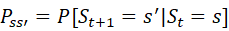
-
R is a reward function, Rs = E[Rt+1 | St = s] 奖励函数
-
γ is a discount factor, γ ∈ [0,1] 折扣因子
Return
Definition:
The return Gt is the total discounted reward from time-step t.
![]() (从当前时间往前算)
(从当前时间往前算)
-
The discount γ ∈ [0,1] is the present value of future rewards(0代表最短视,1代表最长视)
-
The value of receiving reward R after k +1 time-steps is
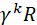
-
This values immediate reward above delayed reward.
-
γ close to 0 leads to ”myopic” evaluation
-
γ close to 1 leads to ”far-sighted” evaluation
Value Function(state value function)
The value function v(s) gives the long-term value of state s
Definition:
The state value function v(s) of an MRP is the expected return starting from state s ![]() (从当前到终点时的reward和的期望,来判断选择给我们更多的总的reward的states)
(从当前到终点时的reward和的期望,来判断选择给我们更多的总的reward的states)
-
从这个state可以找到多个samples,samples的returns是随机的,但是value function函数不是随机的,是这些随机变量的期望
6.Bellman Equation(方程)for MRPs (在动态规划中有很大的应用)
基本思想是对Value Function进行递归分解
The value function can be decomposed into two parts:
-
immediate reward Rt+1
-
discounted value of successor state γv(St+1)

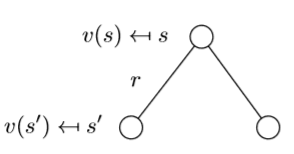
可以看成向前一步的搜索过程
Rt+1即为t时刻状态下的状态所换得的奖励R(s),因此期望可以直接省去;后半部分是可以利用状态转移矩阵对状态值函数求期望,故
![]()
用矩阵和向量来更精准地表示bellman equation的公式:
The Bellman equation can be expressed concisely using matrices:
![]()
where v is a column vector with one entry per state

-
The Bellman equation is a linear equation
-
It can be solved directly:

-
Computational complexity is O(n3) for n states
-
Direct solution only possible for small MRPs
-
There are many iterative(迭代的)methods for large MRPs
7.Markov Decision Process
A Markov decision process (MDP) is a Markov reward process with decisions. It is an environment in which all states are Markov.
引入action
Definition:
Definition A Markov Decision Process is a tuple <S, A, P, R, γ>
-
S is a finite set of states
-
A is a finite set of actions
-
P is a state transition probability matrix,
![]()
-
R is a reward function,

-
γ is a discount factor γ ∈ [0, 1].
8.Policy
Definition:
A policy π is a distribution over actions given states,(根据states的actions的概率分布)
π(a|s) = P [At= a | St= s]
-
A policy fully defines the behaviour of an agent
-
MDP policies depend on the current state (not the history)
-
i.e. Policies are stationary (静态的)(time-independent), At∼ π(·|St), ∀t > 0(独立于时间步,只取决于当下的状态
9.
-
Given an MDP M = <S, A, P, R, γ> and a policy π
-
The state sequence S1, S2, ... is a Markov process <S,
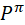 >
> -
The state and reward sequence S1, R2, S2, ... is a Markov reward process <S,
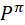 ,
,  , γ>
, γ> -
where
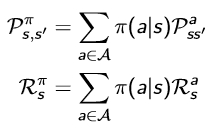
10.Value Function in MDP
Definition 1:The state-value function vπ(s) of an MDP is the expected return starting from state s, and then following policy π
![]() (在policy π下)
(在policy π下)
Definition 2:The action-value function qπ(s,a) is the expected return starting from state s, taking action a, and then following policy π
![]() (在policy π下到action a)
(在policy π下到action a)
11.Bellman Expectation Equation
The state-value function can again be decomposed into immediate reward plus discounted value of successor state,
![]()
The action-value function can similarly be decomposed,
![]()


(v告诉我们采取一个特定的state是有多好,而q告诉我们采取一个特定的action会有多好)
 或者表示为
或者表示为

Example:
 表示的是第一个公式,0.5代表转移的策略,这个等式是为了验证方程的正确性,7.4是给好了的。
表示的是第一个公式,0.5代表转移的策略,这个等式是为了验证方程的正确性,7.4是给好了的。
Bellman Expectation Equation(Matrix Form)(矩阵形式)
可以让你将任何的MDP还原成Markov Reward Process(63:04)
The Bellman expectation equation can be expressed concisely using the induced MRP,
![]()
with direct solution
![]() (可以通过一个线性方程来得到value function)
(可以通过一个线性方程来得到value function)
(视频弹幕解释:
几个概念是可以相互转换的。最基础的是马尔科夫链,它定义了从一个状态到另一个状态的概率;在马尔可夫链的基础上,如果加入了从一个状态到另一个状态的奖励,那就变成了MRP;MRP的转移概率是固定的,也就是说累计奖励只和当前状态有关;如果MRP中的状态转移概率不是固定的,而是由一个policy决定干预,那就变成了MDP,这个policy就是所谓的decision.action和环境共同决定了接下来的state.
12.Optimal(最优的)Value Function
Definition:
The optimal state-value function v∗(s) is the maximum value function over all policies
![]()
The optimal action-value function q∗(s,a) is the maximum action-value function over all policies
![]()
-
The optimal value function specifies the best possible performance in the MDP.
-
An MDP is “solved” when we know the optimal value fn.
(没有告诉我们最佳的policy,但是告诉我们了最大的reward.)
(选择最大,不考虑概率转移)
Optimal Policy(真正关心的)
policy如同随机映射,将state映射到到我们所要采取的action
Define a partial ordering over policies
![]() (任意一个MDP中都存在着一个最佳的policy)
(任意一个MDP中都存在着一个最佳的policy)
Theorem
For any Markov Decision Process
-
There exists an optimal policy π∗ that is better than or equal to all other policies, π∗ ≥ π,∀π
-
All optimal policies achieve the optimal value function,
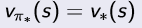
-
All optimal policies achieve the optimal action-value function,
![]()
An optimal policy can be found by maximising over q∗(s,a),
![]()
-
There is always a deterministic optimal policy for any MDP
-
If we know q∗(s,a), we immediately have the optimal policy
Bellman Optimality Equation for v∗
The optimal value functions are recursively related by the Bellman optimality equations:
 (1)(求出action的value的最大值)
(1)(求出action的value的最大值)
Bellman Optimality Equation for Q∗
 (2)(action的immediate value加上接下来states的values的均值/期望)
(2)(action的immediate value加上接下来states的values的均值/期望)
Bellman Optimality Equation for V∗ (2)
 (3)(上述两者的结合,转换为
(3)(上述两者的结合,转换为![]() 的迭代公式)
的迭代公式)
Bellman Optimality Equation for Q∗ (2)
 (4)(转换为
(4)(转换为![]() 的迭代公式)89
的迭代公式)89
e.g.:
 利用公式(1)得到6
利用公式(1)得到6
Solving the Bellman Optimality Equation
-
Bellman Optimality Equation is non-linear
-
No closed form solution (in general)
-
Many iterative(迭代) solution methods
-
Value Iteration
-
Policy Iteration
-
Q-learning
-
Sarsa
-