从马尔科夫决策过程到强化学习(From Markov Decision Process to Reinforcement Learning)
作者:Bluemapleman([email protected])
Github:https://github.com/bluemapleman (欢迎star和fork你喜欢的项目)
知识无价,写作辛苦,欢迎转载,但请注明出处,谢谢!
前言:强化学习本身的设定其实和马尔科夫决策过程(Markov Decision Process,简称MDP)很像,可以说,就是条件简化版的马尔科夫决策过程。因此,学习MDP模型,会很有助于我们理解强化学习的动机与意义。
文章目录
提前规划:马尔科夫决策过程
马尔科夫决策过程,是这样一类问题——它由以下几个集合或者函数定义——:
- 状态集合(Set of states):s S
- 行动集合(Set of Actions):a A
- 状态转换函数(Transition function) T(s,a,s’)
- 回报函数(Reward function) R(s,a,s’)
- 初始状态(Start state)
- 终点状态(Terminal state) (可有可无/optional)
用一个形象的机器人迷宫例子来说明以上这些概念的含义:
机器人迷宫
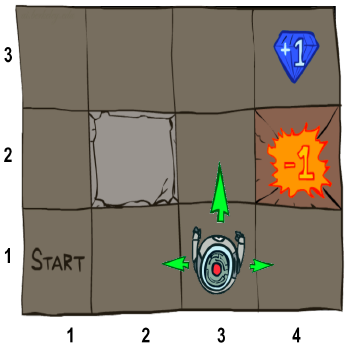
图来自Berkeley CS188教案
假设有如上这么一个网格游戏,主角是一个机器人,它从Start字样的方格开始出发,可以任意以1个方格为单位四处走动。而机器人走到有宝石的地方(4,3)会获得加分,并结束游戏;走到有陷阱的地方(4,2)会减分,并结束游戏。(2,2)位置是一个障碍,无法通过。
那么在以上场景里:
- 状态集合
机器人所可处的所有网格的集合:S={(1,1),(1,2),(1,3),(2,1)…}
- 行动集合
机器人可以采取的行动集合: A={上,下,左,右}
- 状态转换函数:
在这里我们有一个重要设定:当机器人采取某个行动,它并不一定达到该行动预期应当到达的状态,而是有一定可能到达其它状态。
举例来说,如果机器人当前在如上图所示的(3,1)位置,当它采取行动{上},它不会百分之百到达(3,2)位置,而是还有一定概率到达邻近的其它位置(比如(2,1),(4,1))。
停词,状态转换函数T(s,a,s’)描述了:机器人在状态s下采取行动a时,它到达不同后继状态的概率分布。
例如:
| s | a | s’ | T(s,a,s’)/Probability(s’) |
|---|---|---|---|
| (3,1) | 上 | (2,1) | 0.2 |
| (3,1) | 上 | (3,2) | 0.7 |
| (3,1) | 上 | (4,1) | 0.1 |
| … | … | … | … |
这个设定的意义在于,它在原本确定的搜索问题里引入了随机因素(不确定性)。如果这个问题的目标是找到一个行动策略序列,使得机器人的分值可以最大化,并且问题是确定的(即每个状态下的行动有确定的结果/后继状态),那么这个问题其实就是一个简单的搜索问题,我们可以依据给定的信息的程度,决策用非智能搜索(uninformed search)算法如BFS/DFS/Uniform Cost Search,或者用智能搜索(informed search)算法如A* Search来解决问题。(以上搜索算法详情请参考CS188教案)。
然而,因为有了这个设定,这个问题有了不确定性,这也是我们为什么专门设立了MDP这个新概念来描述这一类问题的动机所在。(而我们要费力气把问题搞得复杂,也正是为了让问题越来越贴近现实情况,强化学习也是把不确定问题近一步抽象化,使得更贴近实际情况,当然这是后话)
- 回报函数
当机器人在状态s下采取了行动a,到达后继状态s’后,会获得一个回报值,该值由R(s,a,s’)定义。
更一般的情况下,R(s,a,s’)可能只由s’决定,因此R(s,a,s’)=R(s’)。
比如在上图中,R((4,3))=1, R((4,2))=-1, R(other states)=0。
如何解决机器人迷宫的最优化问题
定义MDP搜索树
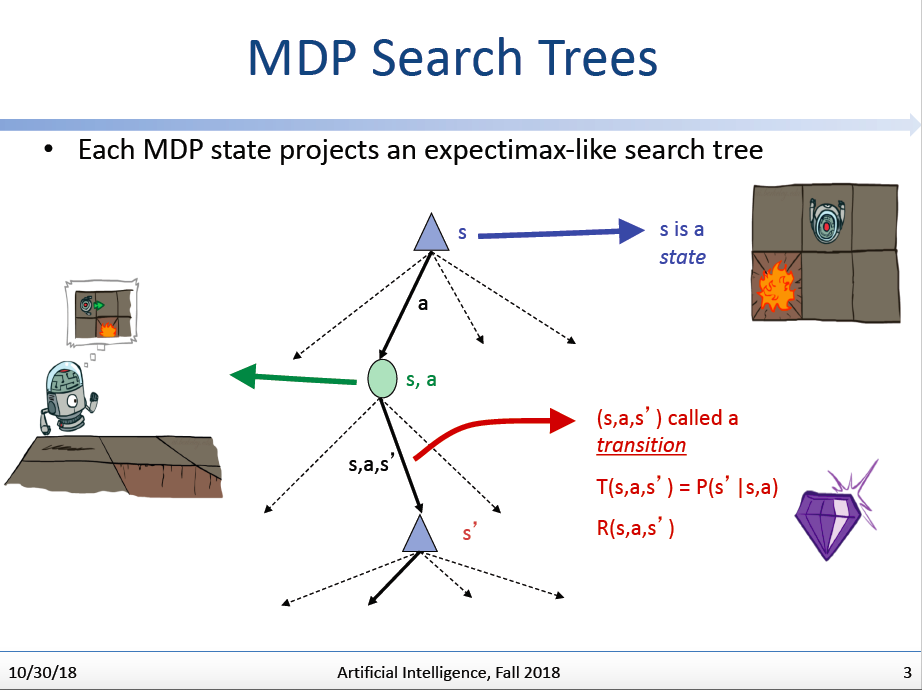
我们尝试把MDP问题贴近到确定性问题的搜索问题:可以定义如上这么一个MDP搜索树,每个三脚结点代表一个状态(根三角结点代表初始状态)。而每个椭圆结点代表一个“状态-行动”结点,它表示在状态s下采取行动a后,机器人可能处于的各种后继状态的总集,这个总集按照T(s,a,s’)的分布,分支出子结点。
而我们的目标就是:找到最优的叶子状态结点,它具有最高的reward值。
策略(Policy)
我们需要定义一个新概念:策略(Policy)。
如其字面意义,我们需要有一个参考,这个参考告诉机器人:当机器人处在状态s时,应当采取哪一个行动。
它可以表示为
所以策略本质上也是一个函数 。而一个**最优策略(optimal policy)**是一个只要机器人遵从,就会获得最大期望效益/得分的策略。
- 策略效用折现(Discounting)

我们每次往MDP搜索树的下一层进发时,我们都需要对下一层的效用进行一次折现。因为直觉来说,我们对于数量相同的效用,它出现在未来和出现在现在的价值可能完全是不一样的,(考虑给你两个选择,现在给你100块,和10年后给你105块,你选哪一个?肯定是前者对不对?毕竟有通货膨胀,而且指不定10年后我还给不给你这笔钱。)
而从问题解决来说,对后续的回报进行折现,也是有利于我们的算法尽快收敛到最优解上的。
解决方案:Value Iteration
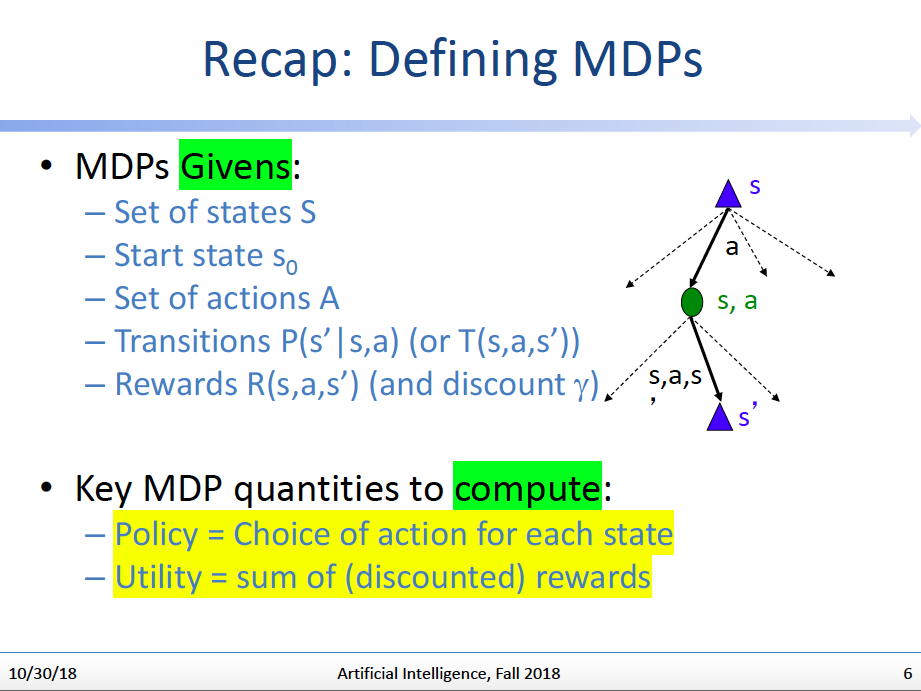
总结一下,我们现在面对的MDP问题的设定是如上图这样的。
而我们接下来将给出的第一个解决MDP问题的方法是Value Iteration。在了解这个方法的具体做法之前,我们还需要定义几个新的重要函数:

- 状态s的效用:
=从状态s开始,并保证每一步行动最优的情况下的期望效用。
- q状态(s,a)的效用:
=从状态s开始,采取行动a,这之后的后续每一步行动都是最优的情况下的期望效用。
- 最优策略
=在状态s应该采取的最优行动。
结合上图右边的搜索树帮助理解:给定任意一个状态s,我们可以选择采取行动a,而(s,a)就构成一个q-state,这个q-state会有(s,a,s’)的概率转移到后续状态s’上。
核心:贝尔曼方程(Bellman Equation)

如上图,Richard Bellman给出了我们新定义的函数之间的转换关系,这个转换关系由递归的形式给出,我们称这个转换关系为贝尔曼方程:
而:
(1)+(2)式导出:
我们来理解一下这个贝尔曼方程的含义:
方程左边:从状态s开始,保证每一步行动最优的情况下的期望效用。
方程右边:选取最好的action,使得q-state(s,a)的期望效用(【从s开始,通过action转移到各个后续状态s’的概率(T(s,a,s’))】与【对应后续状态下的回报+折现率*后续状态s’开始,保证每一步行动最优的情况下的期望效用】的和)取到最大时的那个值。
听起来有点拗口,其实凭感觉来理解的话,意思很明白:我们如何评估一个状态s,在最优情况下会给我们带来的效用是多少呢?Easy,只要我们把这个状态下所有的可以采取的行动试一遍,然后看哪个行动会给我们带来最大的效用,而这个最大的效用也就是该状态s的最大评估效用 。而计算每个可能行动带来的最大的效用的方式是:将该行动可能引发的各种后续状态的期望效用,这个期望效用内含折现过的后续状态s’的最大评估效用 。(这里需要对概率论与数理统计中的期望的概念有一定了解)
对贝尔曼方程大概有一个感觉后,我们来看:我们求解每个状态的最大评估值 时,其计算都依赖于可能的后续状态的最大评估值 ,而这也就是贝尔曼方程的递归特性的体现处。
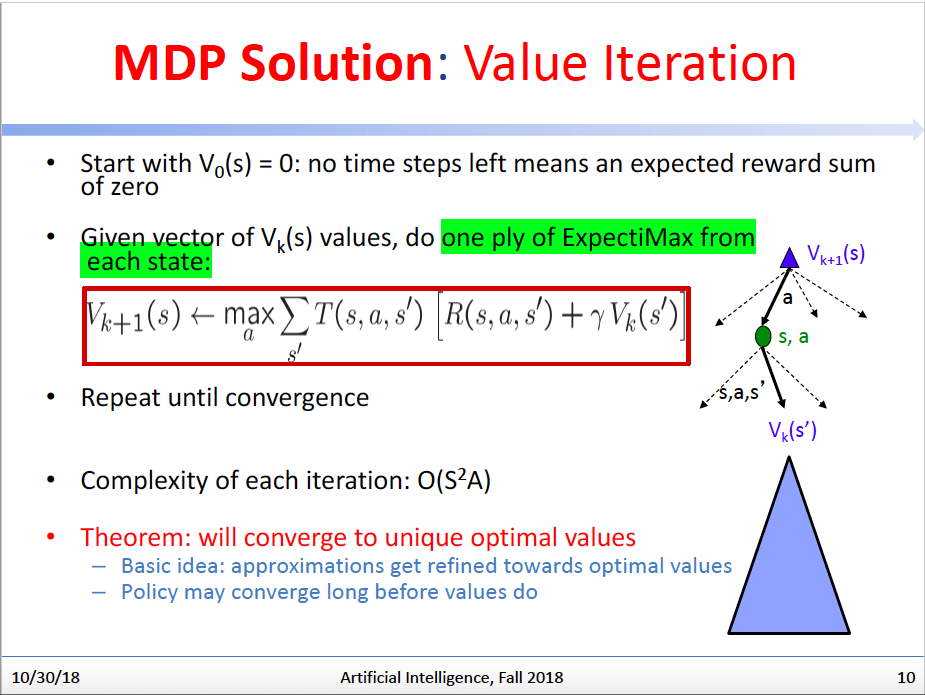
因此,要计算 ,我们肯定是需要有一个初始状态,并且所有状态的最大评估值是要有一个初始化值的,我们将利用贝尔曼方程的递归,逐渐让所有状态的最大评估值收敛,以获得我们所需要的问题解决方案。
为了解决这个递归问题,更易操作的实现方式其实是反向迭代,即我们定义 ,V的下标t表示我们迭代更新到了第几轮,我们会设置第一轮的所有 初始值为0。而我们每一轮更新 会用到上一轮更新得到的 值。我们重复这个迭代更新过程,直到值收敛。这个过程就是Value Iteration。
Value Iteraion的伪代码与python代码如下:


导出策略
现在我们有评估每个状态的效用的方法了,但是我们依然不知道机器人该如何行动,因为我们还不知道如何根据状态的效用来导出最优策略。
因此,与其算状态效用,我们不如直接算q-state效用,因为q-state效用是包含最优效用对应的action的!
于是,以q-state的效用为计算核心的Q-Value Iteration算法如下:


几乎与Value Iteration一样,使用Q-Value Iteration达到收敛后,我们就获得了所有q-state的最大效用评估值。那么当我们处于任何状态s下时,我们只要比较该状态的所有action延伸出来的q-state对应的Q值,选择最大值对应的action去执行就可以了。

边试边学:强化学习
我们的Q-Value Iteration看起来是个很好的算法,能够帮助我们解决机器人如何在迷宫里最优化行动的问题,但是发现了吗,这个算法是要求我们拥有T(s,a,s’)和R(s,a,s’)这两个函数的具体知识的,即如果我们不知道这两个函数的具体值域/形式,我们是不可能使用这个算法的。
于是,我们就在想:既然不知道这两个函数,那么能不能这样,我们不提前做Iteration了,直接让机器人上!我们让机器人在随机探索迷宫的过程中,根据迷宫给它的反馈来学习和这个迷宫有关的特性,并且慢慢找到最优策略。(题外话,是不是觉得这种思路更接近于人类学习的方式,我们预先是不可能对这个世界有任何先天知识的,我们只能靠随机的探索慢慢了解这个世界的规律,并逐渐形成做人处事的策略。这也就是强化学习设定的魅力!)
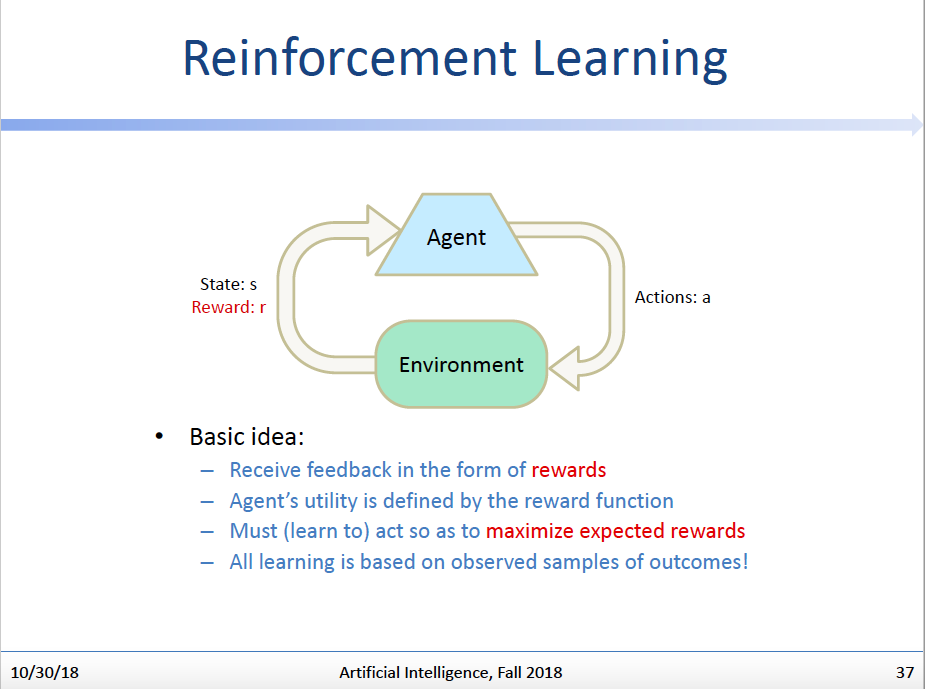
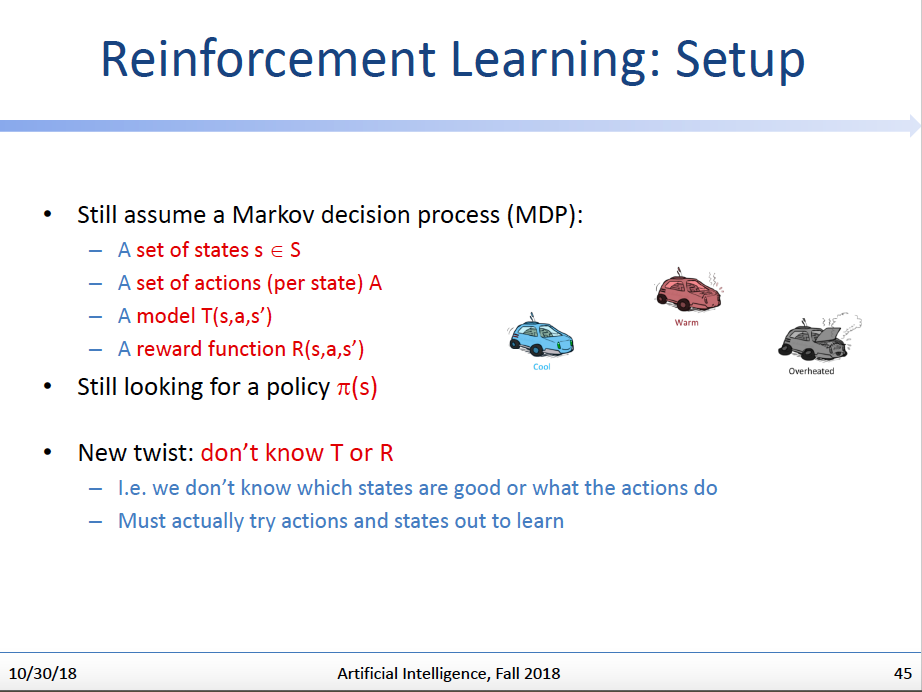
至于强化学习的具体算法,那就单独看我的相关文章了~。
参考:
[1] UC Berkeley CS188:Artificial Intelligence教案
[2] Artificial Intelligence: A Modern Approach (Third Edition)