论文地址: https://ieeexplore.ieee.org/document/8945246.
这篇论文主要讲述了局部语义对齐操作,个人觉得挺总要的,近些年的行人重识别,局部特征的利用大大提高了识别精度。而这篇又是很关键的局部对齐操作,以前的PCB+RPP其中的rpp 也有对齐操作,但是这篇论文的效果比PCB+RPP效果好。
零 ABSTRACT
部分级表征是鲁棒性人再识别的关键。然而,在行人检测过程中出现的常见错误往往会导致人体部件严重的错位问题,从而降低了部件表征的质量针对这一问题,提出了一种新的卷积可变形部件模型(CDPM)。CDPM将复杂的部件对齐过程解耦为两个更简单的步骤:首先,一个垂直对齐步骤在多任务学习模型的帮助下检测垂直方向上的每个身体部件;其次,基于注意力的水平细化步骤会抑制每个检测到的身体部位周围的背景信息。由于这两个步骤是按顺序和正交进行的,因此大大降低了零件对准的难度。在测试阶段,CDPM可以不需要任何外部信息就可以精确地对齐灵活的身体部件。大量的实验结果证明了提出的CDPM对零件对准的有效性。最令人印象深刻的是,CDPM在三个大型数据集上实现了最先进的性能:Market-1501、DukeMTMC-ReID和CUHK03。
壹 INTRODUCTION
一个具有鲁棒性的行人重识别系统依赖于行人特征表征的质量。许多方法【2-3】抽取整个图片的全部特征,但是这些方法容易过拟合【4】,最近,部分表征被证明高区分度和达到最好的表现行列【5-9】,但是如果语义没有对齐,是没法直接比较的,如下图所示。(两个图片语义没有对齐)

凭借着直觉,解决这个对齐方式的方法利用额外的工具:**姿态评估算法的关键点【13】,在训练和测试阶段都用,**但是,这些工具产生的结果不一定值得信赖,另一个流行的策略是通过注意力模型检测身体部位,这些模型无缝地集成到ReID架构中【6,14-16】 然而,这些注意模型仅使用ReID任务进行优化;因此,他们不能提供明确的指导部分对齐。
据此,本文提出了一种新的零件对齐框架。通过为训练阶段提供一个最小的额外注释(行人的上边界和下边界)来自动检测,我们能够将复杂的零件对齐问题分解为两个更简单和连续的步骤,即如图1(b)所示,一个垂直对齐步骤在垂直方向上检测人体部件,一个水平细化步骤在水平方向上抑制每个被检测部件周围的背景信息。 如 下图所示

因此,根据以上的观点,我们引入了新奇的对端对的模型,Convolutional Deformable Part Models(CDPM),CDPM是建立在一个流行的卷积神经网络(convolutional neural network, CNN)为主干的基础上,进一步构建了三个新的模块,即其中,特征学习模块提取部件级特征,垂直对齐模块通过多任务学习检测垂直方向的人体部位,基于注意机制的水平细化模块。
不同的CNN通道描述了不同的视觉模式[4],[17]-[19],即,不同的身体部位。换句话说,信道响应指示每个部分的位置提示。综上所述,CDPM基于相同主干模型的输出,简洁地集成了这三个模块。在推理阶段,垂直对齐模块和水平细化模块依次进行零件对齐,然后从对齐的零件中提取高质量的特征(部件特征提取)。
这篇论文的主要贡献:
我们提出了将身体-零件对准问题解耦为两个正交和连续的步骤的新思想,即,一个垂直检测步骤和一个水平细化步骤。这两个步骤为高质量的部分级表示的学习建立了一个新的框架。据我们所知,这是首次尝试通过分解成正交方向来解决失配问题。
在分治模式下,我们提出了一个简洁的CDPM架构,通过共享相同的主干模型,将表征学习和部分对齐集成在一起。特别是垂直对齐模块是通过一个精心设计的多任务学习结构来实现的。
通过大量的消融实验验证了CDPM的每个部分的有效性。
贰 RELATED WORK
A 、person re-id
介绍了没有深度之前,传统的方法,特征提取和度量学习等。然后介绍了好多论文的引用。然后,因为整体图像抽取特征容易过拟合,介绍了局部特征的提取,但是容易导致对不齐的原因,目前的局部方法分了三类:
1 基于预定义部件位置的方法:这些方法从预定义位置的patch[46]或水平条纹[5]、[8]、[47]中提取部件级特征。
例如,Cheng等人【47】将行人图像均匀地划分为四条水平条纹,并从中提取部分水平特征。
Wang等人【5】也将一幅图像分割成水平条纹。通过提取多粒度的零件级特征,减轻了零件的配准问题。
但是,由于上述方法通常假定失配问题是中等的;因此,在处理严重失调的情况时,他们可能会遇到困难。
2 基于外部信息的方法:这些方法通过利用外部信息,如人工解析工具[48]-[50]生成的掩码,或位姿估计算法[12]、[13]、[51]检测到的关键点来对人体部位进行对齐。
在这些方法中,通常在训练和测试阶段[12]、[13]、[50]都需要外部信息。
这些方法的缺点是,第一,有额外的计算成本,第二,零件定位的准确性取决于外部工具的性能,
3 == 基于注意力模型的方法==:这些方法不需要任何额外的监督[6]、[14]、[16]、[17],直接从ReID网络生成的映射图中预测人体部位的边界框或软掩码
例如,
Li【6】等人设计了一个硬区域注意力模型,能够预测每个身体部位的边界框。相比之下,
Zhao【16】等人提出预测一组软掩模。一个软掩模和每个特征映射通道之间的元素级乘法用于生成部分级特征。
然而,缺乏对零件对准的明确监督可能会给这些注意模型的优化带来困难。
提出的CDPM方法通过在训练阶段引入最小限度的额外监督来提高零件对准的准确性,通过该方法可以将复杂的零件对准问题分解为两个单独的、更简单的步骤。因此,与基于注意的方法相比,与零件对齐相关的优化难度明显降低。与第二类方法相比,所使用的注释更加鲁棒。此外,CDPM在测试阶段不需要任何外部信息;因此,它在实践中更容易使用。
B、基于局部的物体检测
在深度学习作为一种普遍现象出现之前,可变形部件模型(Deformable Part Model, DPM)是最流行的对象检测方法之一。在DPM[52] 及其深度版本[53]- [55]中,部分检测都作为辅助任务来执行,以提高检测精度。在过去的几年里,基于区域提议的方法[56],[57]变得越来越流行。与DPM方法不同,基于区域提议的方法通常直接检测整个对象,而不是进行显式的局部检测。
相比之下,由于已经知道了整个身体的粗糙位置,因此本文提出的方法只针对灵活部分。从这个角度来看,我们的方法与DPM更相似,而不是基于区域提议的方法。由于我们提出的方法是基于CNN的,因此我们将其命名为Convolutional Deformable parts Models (CDPM)。
叁 CONVOLUTIONAL DEFORMABLE PART MODELS
A、problem formulation
就像图一那样,把复杂的局部对齐任务分解为两个部分,垂直对齐步骤主要用来定位身体部位在垂直方向上。水平优化用来抑制每个局部的背景信息垂直对齐步骤具有较大的挑战性。第一,整个图片用来搜寻每一个身体部位,第二 相邻的局部之间没有明确的分界线。我们利用最小化的标注来辅助监督在训练的时候。来解决这个问题
利用 Macro-Micro Adversarial Network (MMAN) [58].来主动检测行人的上下边界。这些边界遵循以下原则确定。第一,MMAN得到的七个类别合并为三个类,头部(包括头发和脸),上半身(包括上半身的衣服和手臂),下半身(包括下半身的衣服、腿和鞋子)。其次,将行人的上边界设置为头部的上边界,将行人的下边界定义为身体下部的下边界。(上下边界的确定)

此外,如图所示图2(b)通过对头部和身体下半部的像素数分别进行计数,发现严重的缺失部分问题。如果其中一个的大小小于预先设置的阈值(例如,在我们的实现中是1280像素),我们认为这幅图像存在严重的部件丢失问题。由于MMAN可能无法得到可靠的结果(图2©),因此直接利用MMAN返回的身体部件位置不是最优的。(是否为严重缺失判断)
通过上下边界的均匀分割产生在垂直方向每个部分的局部区域。
基于上述思想,我们提出了一种新的联合局部特征学习和局部对齐的CDPM模型。如图3所示,CDPM建立在ResNet-50骨干网模型[60]上。与[7]类似,我们删除了ResNet-50中的最后一个空间下采样操作,以增加输出特征图的大小。基于这些输出特征映射,我们继续构建三个新的模块,基于局部层次特征提取的特征学习模块,基于多任务学习的垂直对齐模块,基于注意的水平细化模块。这三个模块协同工作以对齐主体部分并进一步学习高质量的部件级表示
B、Feature Learning Module
(先划分,然后学习)
局部特征学习作者用了PCB(part-based convolutional baseline),特征学习模块包含K个部件级特征学习分支,每个分支学习部件特定的特征。这K个分支都有相同的结构。,一个全球平均池(GAP)层,一个1*1个卷积层,一个分类层。
在训练阶段,每个部分的位置可以通过提供的统一划分上下行人边界的注释来推断(图2(a))。如果没有提供上边界或下边界,例如由于缺失部分而看不到上边界(图2(b)),则我们将整个图像沿垂直方向均匀分割。在测试阶段,通过提出的零件定位方法来确定每个零件的位置。
(这部分介绍了如果学习局部的特征,首先划分k个部分,第一,正常的图片。 均匀划分上下界,如果严重缺失,也可能遮挡导致,直接整个图片均匀划分,然后通过后边的局部定位方法确定每个位置,确定了位置之后通过PCB来学习局部特征)
每个K部分级的特征被优化为一个多类分类任务使用软最大损失函数。第k部分的损失函数表达式如下:

C、Vertical Alignment Module
(定位身体的局部位置,把每张图片的头,肩膀,躯干,腿,脚等信息定位,这样才能保证每个图片语义对齐,才能比较)
特征映射的不同通道表征着不同的身体局部【4 18】,这就表明了通道表征可以暗示身体的局部位置。因此设计了一个垂直方向上的身体局部检测模块。基于backbone的输出。得到的feature map 是 24* 8* 2048,设计R个滑块窗口,每个滑块大小为4* 8* 2048,因此 我们得到21个滑块窗口。(这点按照卷积操作计算即可),效果如图4(b) 所示
(我们得到21个滑块窗口,现在需要判断K个部分所对应的滑块窗口,如何从21挑选合适的窗口作为K个部分,在下边的介绍)

此外,受更快的R-CNN[57]的启发,我们通过多任务学习的方式来处理滑动窗口,即,对所有滑动窗口进行粗分类,并对滑动窗口进行精细回归,使其回归到各自的地面真值位置。这两个任务只共享一个GAP。值得注意的是,我们只使用图像的上边界和下边界都是可见的在这个模块的训练
(对于严重缺失,不进行此操作,经过多任务学习方式,就能确定21个滑块中选择合适的滑块窗口作为K个部分窗口)
(1)Coarse Classification of Sliding Windows:
这部分任务就是把21个滑块窗口分类到他们相对应的部分或者背景类别。(因为21个包含了背景部分的滑块),包含了一个1* 1的卷积层,和一个全连接层(FC), FC输出的是K+1维度,因为K个部分和一个背景类别。因为窗口存在重叠,真是标签也是软的,所以用交叉熵损失函数,Lc=

(根据上面这个公式,还不知道yir(k) 的值,第r个滑块窗口属于第K部分的真值标签,下面来解决这个问题)
Ground-truth Label of Sliding Windows:具体的操作思想是,1 、通过上下边界均匀划分得到K个部分的真实标签位置,2 、计算yr(k) 的向量(元素是每个部分的对应概率)

(经过以上两步操作,得到21个滑块的K+1的分类以上是粗分类的步骤)
(2)Refined Regression of Sliding Windows:
(滑块的精细回归,挑选K部分对应的滑块通过加入通道注意力模块)
通过部分特定的回归任务,进一步提高了垂直对准模块的精度。如图2所示,构造K个回归任务,使它们具有相同的结构。但是,这些任务不共享任何参数,并且每个任务都经过了优化,以检测某个特定的部分(K个回归任务,检测特定的部分)
每一个回归任务包含一个通道注意力模块,一个1* 1的卷积层,一个全连接层(FC)一个tanh层,如下图所示,

通道注意力模块用来强调具体局部(部分)的信息,输出的是通道注意力,然后乘以输入特征向量,最后,我们得到了每一个滑块(21个)的权重特征向量。
在训练过程中,将所有滑动窗口的2048维特征输入到K个回归分支中。相应地,我们得到了tanh归一化后的K组预测偏移量。每个回归任务都涉及到均方误差(MSE)损失的优化:

在测试过程中,将所有滑动窗口的2048维特征同时输入到分类任务和K回归任务中。得到了R滑动窗的分类分数和预测偏移量。我们根据以下规则为每个部分选择最优的滑动窗口:首先,如果多个滑动窗口的分类得分高于预先定义的阈值T,我们选择偏移量最小的滑动窗口(绝对值);其次,如果只有一个或没有一个滑动窗口/s,分类分数在T以上,我们就选择分类分数最大的那个。
D、 Horizontal Refinement Module
(消除K个每个局部的背景信息)
值得注意的是,以上的所有操作仅仅是得到了身体的局部位置,因此我们通过额外的水平细化操作来抑制背景信息,(这一步在特征提取之前进行)

这里的水平细化模型应用在每一个部分特征提取里边,(共有K个),利用的是时空注意力模型(SCA) 【6】,结构如下图所示

E. Person Re-ID via CDPM
在训练阶段,综合考虑CDPM的三个模块,CDPM的总体目标函数为:
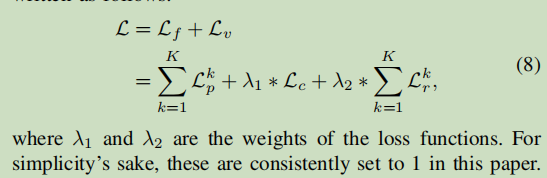
在测试阶段,
1、每张图像通过主干模型得到尺寸为24×8×2048的特征图。为了提取零件级特征,
2、将24×8×2048幅特征图分成R个滑动窗口大小固定到4×8×2048,
3、垂直对准模块为每个部件选择一个最优滑动窗口;然后,
4、选取的第k个零件的滑动窗口经过第k个水平细化模块(K个)和零件级特征学习分支(K个)【都是一 一对应的 K个】,得到512维部件级特征向量zk
5、将上述K个特征向量串联起来,得到图像的最终表示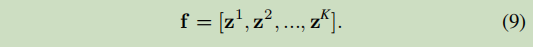
我们始终使用余弦距离来计算两个图像表示之间的相似性。
F. Multi-granularity Feature
最近的一些工作【5、8】 采用了多粒度特征来加强re-id的表征。与单级零件特性相比,MGF提供了更丰富的多尺度信息,因此更强大。所提出的CDPM框架是灵活的,可以自然地扩展到提取MGF,包括整体层次特征和多层次的部件特征。
(1) 、Holistic-leavel feature

如上图所示,整体特征提取分支,包含了GAP和FC层,与部件级特征学习模块一样,这个分支也附加到主干模型的输出上。
根据【5】,整体特征用triplet loss 来优化,硬间隔三元组损失。
(2) Multi-level part featrues:
我们进一步增加了其他粒度的部分级特征学习分支。更详细地,我们将K分别设为2、3、4;因此,还有9个额外的部分级特征学习分支。如图7所示,新分支的结构和损失函数与原分支在CDPM中的结构和损失函数完全相同。
这里值得注意的是,额外的分支只添加在特性学习模块中。CDPM的垂直对准模块保持不变。如图所示8、在测试阶段,根据CDPM中原有垂直找正模块的预测结果,可以推断出新的粒度各部分的位置。

为了构建测试阶段的MGF,我们提取了上述所有颗粒的部分级特征,以及holisticleveland特征。将上述所有特征串联起来,形成一个行人图像的最终表示(不太确定作者是否使用多粒度)