论文名称:Deep Learning for Person Re-IDentification: A Survey and Outlook
论文下载:https://arxiv.org/abs/2001.04193
论文年份:TPAMI 2021
论文被引:448(2022/05/17)Re-ID 数据集:https://github.com/NEU-Gou/awesome-reid-dataset
Abstract
Person Re-IDentification (Re-ID) aims at retrieving a person of interest across multiple non-overlapping cameras. With the advancement of deep neural networks and increasing demand of intelligent video surveillance, it has gained significantly increased interest in the computer vision community. By dissecting the involved components in developing a Person Re-ID system, we categorize it into the closed-world and open-world settings. The widely studied closed-world setting is usually applied under various research-oriented assumptions, and has achieved inspiring success using deep learning techniques on a number of datasets. We first conduct a comprehensive overview with in-depth analysis for closed-world Person Re-ID from three different perspectives, including deep feature representation learning, deep metric learning and ranking optimization. With the performance saturation under closed-world setting, the research focus for Person Re-ID has recently shifted to the open-world setting, facing more challenging issues. This setting is closer to practical applications under specific scenarios. We summarize the open-world Re-ID in terms of five different aspects. By analyzing the advantages of existing methods, we design a powerful AGW baseline, achieving state-of-the-art or at least comparable performance on twelve datasets for FOUR different Re-ID tasks. Meanwhile, we introduce a new evaluation metric (mINP) for Person Re-ID, indicating the cost for finding all the correct matches, which provides an additional criteria to evaluate the Re-ID system for real applications. Finally, some important yet under-investigated open issues are discussed.
行人重新识别 (Re-ID) 旨在通过多个不重叠的摄像头检索感兴趣的人。随着深度神经网络的进步和智能视频监控需求的增加,它在计算机视觉社区中获得了显着增加的兴趣。通过剖析开发行人 Re-ID 系统所涉及的组件,我们将其分为封闭世界和开放世界设置。广泛研究的封闭世界环境通常应用于各种以研究为导向的假设,并在许多数据集上使用深度学习技术取得了令人鼓舞的成功。我们首先从深度特征表示学习、深度度量学习和排名优化三个不同的角度对封闭世界的行人 Re-ID 进行了全面的概述和深入分析。随着封闭世界设置下的性能饱和,行人 Re-ID 的研究重点最近转移到了开放世界设置,面临着更具挑战性的问题。该设置更接近特定场景下的实际应用。我们从五个不同方面总结了开放世界的 Re-ID。通过分析现有方法的优势,我们设计了一个强大的 AGW 基线,在四个不同的 Re-ID 任务的十二个数据集上实现了最先进或至少可比的性能。同时,我们为行人重识别引入了一个新的评估指标(mINP),表示找到所有正确匹配的成本,这为评估重识别系统的实际应用提供了额外的标准。最后,讨论了一些重要但未被充分调查的开放性问题。
1 INTRODUCTION
行人重新识别 (Re-ID) 已被广泛研究为跨非重叠相机 [1], [2] 的特定行人检索问题。给定一个查询感兴趣的人,Re-ID 的目标是确定此人是否在不同的相机拍摄的不同时间出现在另一个地方,或者甚至是同一相机在不同的瞬间 [3]。查询人可以用图像[4], [5], [6]、视频序列[7], [8],甚至是文本描述[9], [10]来表示。由于公共安全的迫切需求和越来越多的监控摄像头,行人 Re-ID 在智能监控系统中势在必行,具有重大的研究影响和现实意义。
- 由于存在不同的视角 [11], [12]、不同的低图像分辨率 [13], [14]、光照变化 [15]、不受约束的姿势 [16], [17], [18],遮挡 (occlusions) [19],[20],异质模态 (heterogeneous modalities) [10],[21],复杂的相机环境,背景杂波 (background clutter) [22],不可靠的边界框生成等,Re-ID 是一项具有挑战性的任务。这些导致不同的变化和不确定性。
- 此外,对于实际模型部署,动态更新的相机网络 [23], [24]、具有高效检索的大规模图库 [25]、组不确定性 (group uncertainty) [26]、显着的域偏移 (significant domain shift) [27]、看不见的测试场景 (unseen testing scenarios) [28] ,增量模型更新 (incremental model updating) [29] 和更换衣服 (changing cloths) [30] 也大大增加了难度。这些挑战导致 Re-ID 仍然是未解决的问题。
早期的研究工作主要集中在具有身体结构的手工特征构建 [31], [32], [33], [34], [35] 或距离度量学习 [36], [37], [38], [39 ], [40], [41]。随着深度学习的进步,行人 Re-ID 在广泛使用的基准测试 [5], [42], [43], [44] 上取得了令人鼓舞的表现。然而,以研究为导向的场景与实际应用之间仍有很大差距 [45]。这促使我们进行全面调查,为不同的 Re-ID 任务开发强大的基线,并讨论几个未来的方向。
尽管一些调查也总结了深度学习技术 [2], [46], [47],但我们的调查有三个主要区别:
-
1)我们通过讨论现有深度学习方法的优势和限制,分析最先进的技术。这为未来的算法设计和新主题探索提供了见解。
-
2)我们为未来的发展设计了一个新的强大基线(AGW:Attention Generalized mean pooling with Weighted triplet loss)和一个新的评估指标(mINP:mean Inverse Negative Penalty)。 AGW 在 12 个数据集上针对四种不同的 Re-ID 任务实现了最先进的性能。 mINP 为现有的 CMC/mAP 提供了一个补充指标,指示找到所有正确匹配项的成本。
-
3)我们尝试讨论几个重要的研究方向和未充分研究的开放问题,以缩小封闭世界和开放世界应用之间的差距,向现实世界的 Re-ID 系统设计迈出一步。
除非另有说明,本次调查中的行人 Re-ID 是指从计算机视觉角度跨多个监控摄像头的行人检索问题。一般来说,针对特定场景构建行人 Re-ID系统需要五个主要步骤(如图 1 所示):
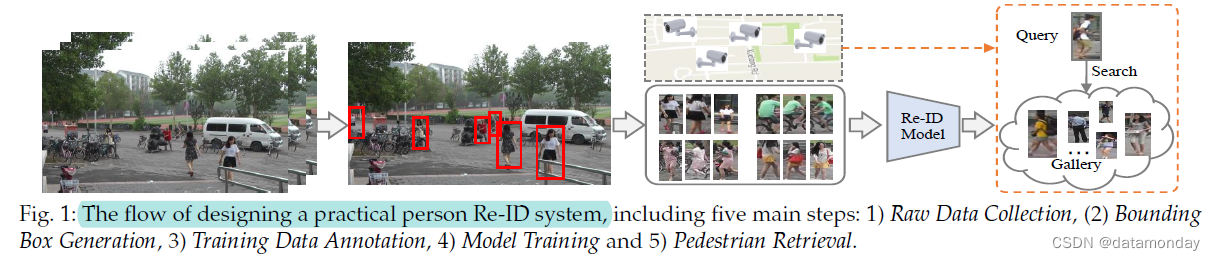

-
步骤 1:原始数据收集:从监控摄像头获取原始视频数据是实际视频调查的首要要求。这些摄像机通常位于不同环境下的不同地方[48]。最有可能的是,这些原始数据包含大量复杂且嘈杂的背景杂波 (noisy background clutter)。
-
步骤 2:边界框生成 (Bounding Box Generation):从原始视频数据中提取包含行人图像的边界框。通常,在大规模应用中不可能手动裁剪所有行人图像。边界框通常通过人检测 [49], [50] 或跟踪算法 [51], [52] 获得。
-
步骤 3:训练数据标注:标注交叉相机 (cross camera) 标签。由于较大的跨相机变化,训练数据标注通常对于判别性 Re-ID 模型学习是必不可少的。在存在大域偏移 (large domain shift) [53] 的情况下,我们经常需要在每个新场景中对训练数据进行标注。
-
步骤 4:模型训练:用之前带标注的行人图像/视频训练一个有判别力和鲁棒性的 Re-ID 模型。这一步是开发 Re-ID 系统的核心,也是文献中研究最广泛的范例。已经开发了广泛的模型来处理各种挑战,主要集中在特征表示学习 (feature representation learning) [54], [55]、距离度量学习 (distance metric learning) [56], [57] 或它们的组合。
-
步骤 5:行人检索 (Pedestrian Retrieval):测试阶段进行行人检索。给定一个感兴趣的人(查询 (query))和一个图库集 (gallery set),使用在前一阶段学习的 Re-ID 模型提取特征表示。通过对计算的查询到图库的相似度进行排序,获得检索到的排名列表。一些方法还研究了排名优化以提高检索性能[58], [59]。
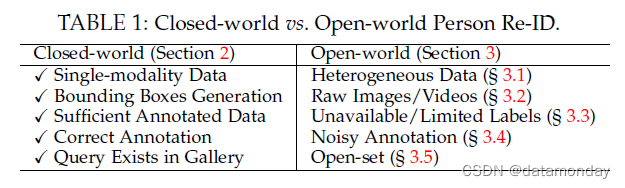
根据上述五个步骤,我们将现有的 Re-ID 方法分为两大趋势:封闭世界和开放世界设置,如表 1 所示。逐步比较以下五个方面: -
1)单模态与异构数据 (Single-modality vs. Heterogeneous Data):对于步骤 1 中的原始数据收集,所有的人都由封闭世界设置中的单模态可见相机捕获的图像/视频表示 [5], [8], [ 31], [42], [43], [44]。然而,在实际的开放世界应用中,我们可能还需要处理异构数据,例如红外图像 [21], [60]、草图 (sketches) [61]、深度图像 [62],甚至是文本描述 [63]。这激发了第 3.1 节中的异构 Re-ID。
-
2)Bounding Box Generation vs. Raw Images/Videos:对于步骤 2 中的bounding box生成,封闭世界行人 Re-ID通常基于生成的bounding box进行训练和测试,其中bounding box主要包含person外观信息。相比之下,一些实际的开放世界应用程序需要从原始图像或视频中进行端到端的行人搜索 [55], [64]。这导致了另一个开放世界主题,即第 3.2 节中的端到端行人搜索。
-
3)足够的带标注的数据与不可用/有限的标签:对于步骤 3 中的训练数据标注,封闭世界的行人 Re-ID 通常假设我们有足够的带标注的训练数据来进行有监督的 Re-ID 模型训练。然而,在每个新环境中为每个相机对进行标签标注既费时又费力,成本也很高。在开放世界场景中,我们可能没有足够的标注数据(即有限的标签)[65],甚至没有任何标签信息[66]。这激发了第 3.3 节中对无监督和半监督 Re-ID 的讨论。
-
4)正确标注与错误标注 (Correct Annotation vs. Noisy Annotation):对于第 4 步,现有的封闭世界的行行人 Re-ID 系统通常假设所有标注都是正确的,并带有干净的标签。然而,由于标注错误(即标签噪声)或不完美的检测/跟踪结果(即样本噪声、部分 Re-ID [67]),标注噪声通常是不可避免的。这导致了第 3.4 节中在不同噪声类型下对噪声鲁棒性行人 Re-ID 的分析。
-
5)Query Exists in Gallery vs. Open-set:在行人检索阶段(步骤 5),大多数现有的封闭世界行人 Re-ID 研究通过计算 CMC [68] 和 mAP[5]。然而,在许多情况下,被查询行人可能不会出现在图库集 [69], [70] 中,或者我们需要执行验证而不是检索 (verification rather than retrieval) [26]。这将我们带到了第 3.5 节中的开放集行人 Re-ID。
该调查首先在第 2 节中介绍了在封闭世界设置下广泛研究的行人重识别。第 2.4 节对数据集和最新技术进行了详细审查。然后在第 3 节中介绍开放世界的行人 Re-ID。第 4 节介绍了对未来 Re-ID 的展望,包括一个新的评估指标(第 4.1 节)、一个新的强大的 AGW 基线(第 4.2 节)。我们讨论了几个未充分调查的未解决问题以供未来研究(第 4.3 节)。结论将在第 5 节中得出。结构概述见补充。
2 CLOSED-WORLD Person Re-IDENTIFICATION
本节概述了封闭世界的行人 Re-ID。如第 1 节所述,此设置通常具有以下假设:
1)人的外表 (person appearances) 由单模态可见相机捕获,通过图像或视频;
2)人由bounding box表示,其中大部分bounding box区域属于同一个身份;
3)训练有足够的带标注的训练数据用于有监督的判别式 Re-ID 模型学习;
4)标注一般是正确的;
5)查询人必须出现在图库集中。
通常,一个标准的封闭世界 Re-ID 系统包含三个主要组件:
-
特征表示学习(第 2.1 节),专注于开发特征构建策略;
-
深度度量学习(第 2.2),旨在设计具有不同损失函数或采样策略的训练目标;
-
排名优化(第 2.3 节),专注于优化检索到的排名列表。
第 2.4.2 节提供了数据集和状态的概述以及深入分析。
2.1 Feature Representation Learning
我们首先讨论了封闭世界的行人 Re-ID 中的特征学习策略。有四个主要类别(如图 2 所示):
- a)全局特征(§ 2.1.1),它为每个人的图像提取全局特征表示向量,而无需额外的标注线索 [55];
- b)局部特征(§ 2.1.2),它聚合部分级局部特征以制定每个人图像的组合表示 [75], [76], [77];
- c)辅助特征(§ 2.1.3),它使用辅助信息改进特征表示学习,例如属性 [71], [72], [78]、GAN 生成的图像 [42] 等。
- d)视频特征(§ 2.1.4),它使用多个图像帧和时间信息 [73], [74] 学习基于视频的 Re-ID [7] 的视频表示。我们还回顾了第 2.1.5 节中行人重识别的几个特定架构设计。
2.1.1 Global Feature Representation Learning
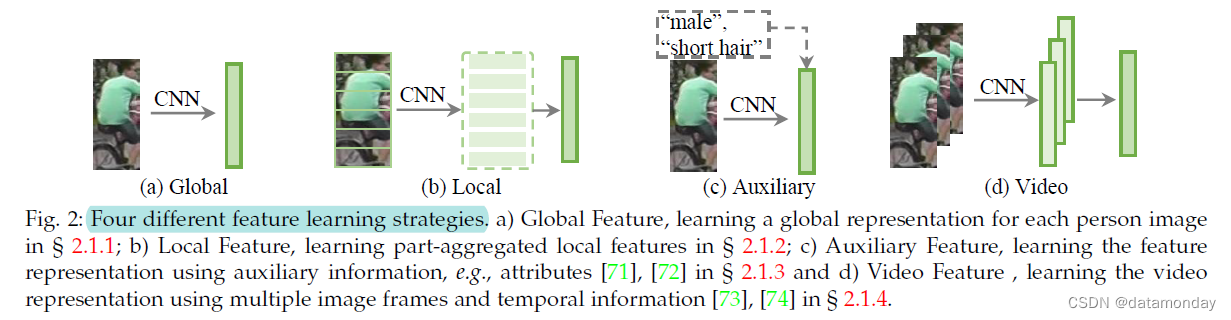
全局特征表示学习为每个人的图像提取一个全局特征向量,如图 2(a) 所示。
- 由于深度神经网络最初应用于图像分类[79], [80],因此早期将先进的深度学习技术集成到行人 Re-ID领域时,全局特征学习是首选。
- 为了捕捉全局特征学习中的细粒度线索,在 [81] 中开发了一个由单图像表示 (SIR) 和跨图像表示 (CIR) 组成的联合学习框架,使用特定的子网络进行三重损失训练。
- 广泛使用的 ID 判别嵌入 (IDE) 模型 [55] 通过将每个身份视为不同的类,将训练过程构建为多类分类问题。它现在广泛用于 Re-ID 社区 [42], [58], [77], [82], [83]。
- [84] 开发了一种多尺度深度表示学习模型来捕捉不同尺度的判别线索。
注意力信息 (Attention Information)。注意力方案已在文献中得到广泛研究,以增强表示学习[85]。
- 1)第一组:行人图像内的注意力。典型的策略包括
- **像素级注意力 [86] **
- 通道特征响应重新加权 [86], [87], [88], [89]
- 背景抑制 [22]
- 空间信息集成 [90]。
- 2)第 2 组:关注多个行人图像。
- [91] 中提出了一种上下文感知的注意力特征学习方法,它结合了序列内和序列间的注意力,用于成对的特征对齐和细化 (alignment and refinement)。
- 在 [92], [93] 中添加了注意力一致性属性。
- 组相似性 [94], [95] 是另一种利用跨图像注意力的流行方法,它涉及用于局部和全局相似性建模的多个图像。第一组主要增强对错位/不完美检测的鲁棒性,第二组通过挖掘多个图像之间的关系来改进特征学习。
2.1.2 Local Feature Representation Learning
它学习部分/区域聚合特征,使其能够抵抗错位 (misalignment) [77], [96]。身体部位要么通过人体解析/姿势估计自动生成(第 1 组),要么通过大致水平划分(第 2 组)自动生成。
通过自动身体部位检测,流行的解决方案是结合全身表示和局部特征[97], [98]。具体来说,
- 多通道聚合[99]、多尺度上下文感知卷积[100]、多级特征分解[17]和双线性池化[97]旨在改善局部特征学习。
- 在[98]中还研究了部分级相似性组合 (part-level similarity combination),而不是特征级融合。
- 另一种流行的解决方案是增强对背景杂波的鲁棒性,使用姿势驱动匹配[101]、姿势引导部分注意模块[102]、语义部分对齐[103], [104]。
对于水平划分的区域特征,在基于部分的卷积基线 (PCB) [77] 中学习了多个部分级分类器,它现在作为当前最先进的 [28], [ 105], [106] 中强大的部分特征学习基线。为了捕捉多个身体部位之间的关系,Siamese Long Short-Term Memory (LSTM) 架构 [96]、二阶非局部注意力 [107]、交互和聚合 (IA) [108] 旨在加强特征学习。
第一组使用人类解析技术来获得语义上有意义的身体部位,这提供了很好的部分特征。然而,它们需要一个额外的姿态检测器,并且容易出现噪声姿态检测 [77]。第二组采用均匀划分得到横条纹部分,比较灵活,但对重度遮挡和大背景杂波比较敏感。
2.1.3 Auxiliary Feature Representation Learning
辅助特征表示学习通常需要额外的标注信息(例如语义属性[71])或生成/增强的训练样本来加强特征表示[19], [42]。
语义属性 (Semantic Attributes)。
- [72] 中引入了联合身份和属性学习基线。
- [71] 提出了一种深度属性学习框架,通过结合预测的语义属性信息,以半监督学习的方式增强特征表示的泛化性和鲁棒性。
- 语义属性和注意力方案都被结合起来以改进部分特征学习 [109]。
- [110] 中还采用语义属性进行视频 Re-ID 特征表示学习。
- 它们还被用作无监督学习中的辅助监督信息 [111]。
视点信息 (Viewpoint Information)。视点信息也被用来增强特征表示学习[112],[113]。
- 多级分解网络(MLFN)[112] 还尝试在多个语义级别上学习身份判别和视图不变的特征表示。
- [113] 提取通用视图 (view-generic) 和特定视图 (view-specific) 学习的组合。
- 在视点感知特征学习 [114] 中,结合了角度正则化。
域信息 (Domain Information)。
- 域引导丢弃 (Domain Guided Dropout, DGD) 算法 [54] 旨在自适应地挖掘域可共享和域特定的神经元,用于多域深度特征表示学习。
- [115] 将每个相机视为一个不同的域。提出了一种多相机一致匹配约束,以在深度学习框架中获得全局最优表示。
- 类似地,相机视图信息或检测到的相机位置也被应用在[18]中,以通过相机特定的信息建模来改进特征表示。
GAN 生成 (GAN Generation)。本节讨论使用 GAN 生成的图像作为辅助信息。
- [42] 开始首次尝试将 GAN 技术应用于 行人 Re-ID。它使用生成的行人图像改进了有监督的特征表示学习。
- 姿势约束被纳入 [116] 以提高生成的行人图像的质量,生成具有新姿势变体的行人图像。
- [117] 设计了一种姿势归一化图像生成方法,它增强了对姿势变化的鲁棒性。
- 相机样式信息 [118] 也集成在图像生成过程中,以解决跨相机的变化。
- 一个联合判别和生成学习模型 [119] 分别学习外观和结构代码以提高图像生成质量。
- 使用 GAN 生成的图像也是无监督域自适应 Re-ID [120], [121] 中广泛使用的方法,近似于目标分布。
数据增强 (Data Augmentation)。对于 Re-ID,自定义操作是随机调整大小、裁剪和水平翻转 [122]。
- 生成对抗性遮挡样本 [19] 以增加训练数据的变化。
- [123] 中提出了一种类似的随机擦除策略,向输入图像添加随机噪声。
- 批量 DropBlock [124] 在特征图中随机丢弃一个区域块,以加强注意力集中的特征学习。
- [125] 生成在不同光照条件下渲染的虚拟人。这些方法通过增强样本丰富了监督,提高了测试集的泛化性。
2.1.4 Video Feature Representation Learning
基于视频的 Re-ID 是另一个热门话题 [126],其中每个人都由具有多个帧的视频序列表示。由于丰富的外观和时间信息,它在 ReID 社区中获得了越来越多的兴趣。这也给使用多张图像的视频特征表示学习带来了额外的挑战。
主要挑战是准确捕获时间信息。
- 为基于视频的行人 Re-ID [127] 设计了一种循环神经网络架构,它联合优化了时间信息传播的最终循环层和时间池化层。
- 在 [128] 中开发了一种用于空间和时间流的加权方案。
- [129] 提出了一个渐进/顺序融合框架来聚合帧级人类区域表示。
- 在 [110] 中,语义属性也被用于具有特征分离和帧重新加权的视频 Re-ID。
- 联合聚合帧级特征和时空外观信息对于视频表示学习 [130], [131], [132] 至关重要。
另一个主要挑战是视频中不可避免的异常跟踪帧。
- 在联合空间和时间注意池网络(ASTPN)[131] 中选择信息帧,并将上下文信息集成 [130]。
- 受共同分割启发的注意力模型 [132] 通过相互一致的估计来检测多个视频帧中的显着特征。
- 采用多样性正则化 [133] 来挖掘每个视频序列中的多个有区别的身体部位。
- 采用仿射壳 (affine hull) 来处理视频序列中的异常帧[83]。
- 一项有趣的工作 [20] 利用多个视频帧来自动完成遮挡区域。这些工作表明,处理噪声帧可以极大地改善视频表示学习。
处理不同长度的视频序列也具有挑战性。
- [134] 将长视频序列分成多个短片段,聚合排名靠前的片段以学习紧凑的嵌入。
- 剪辑级学习策略 [135] 利用空间和时间维度的注意线索来产生强大的剪辑级表示。
- 短期和长期关系 [136] 都集成在一个自我注意方案中。
2.1.5 Architecture Design
将行人 Re-ID 作为一个特定的行人检索问题,现有的大多数工作都采用为图像分类而设计的网络架构 [79], [80] 作为主干。一些工作试图修改主干架构以实现更好的 Re-ID 功能。对于广泛使用的 ResNet50 主干 [80],重要的修改包括将最后一个卷积条带/大小更改为 1 [77],在最后一个池化层 [77] 中采用自适应平均池化,并在池化后添加具有批量归一化的瓶颈层[82]。
准确性是特定 Re-ID 网络架构设计以提高准确性的主要关注点。
- [43]通过设计一个滤波器配对神经网络(FPNN)开始了第一次尝试,该网络与部分判别信息挖掘共同处理错位和遮挡。
- [89] 提出了一个带有专门设计的 WConv 层和 Channel Scaling 层的 BraidNet。 WConv 层提取两个图像的差异信息以增强对未对齐的鲁棒性,通道缩放层优化每个输入通道的缩放因子。
- 多级因子分解网络(MLFN)[112] 包含多个堆叠块以对特定级别的各种潜在因子进行建模,并且动态选择因子以制定最终表示。
- [137] 开发了一种具有卷积相似度模块的高效全卷积孪生网络,以优化多级相似度测量。
通过使用深度卷积可以有效地捕获和优化相似度。效率是 Re-ID 架构设计的另一个重要因素。一个高效的小规模网络,即 OmniScale 网络(OSNet)[138],是通过结合点卷积和深度卷积来设计的。为了实现多尺度特征学习,引入了由多个卷积流组成的残差块。
随着对自动机器学习的兴趣日益增加,提出了 Auto-ReID [139] 模型。 Auto-ReID 基于一组基本架构组件提供高效且有效的自动化神经架构设计,使用部分感知模块来捕获具有判别性的局部 ReID 特征。这为探索强大的特定领域架构提供了潜在的研究方向。
2.2 Deep Metric Learning
在深度学习时代之前,度量学习已经通过学习马氏距离函数 [36], [37] 或投影矩阵 [40] 得到了广泛的研究。度量学习的作用已被损失函数设计所取代,以指导特征表示学习。我们将首先回顾第 2.2.1 节中广泛使用的损失函数,然后在第 2.2.2 节总结具有特定抽样设计的训练策略。
2.2.1 Loss Function Design
本次调查仅关注为深度学习设计的损失函数 [56]。为手工系统设计的距离度量学习的概述可以在 [2], [143] 中找到。在行人 Re-ID 的文献中,有三种广泛研究的损失函数及其变体,包括
-
身份损失
-
验证损失
-
三元组损失
图 3 显示了三个损失函数的图示。
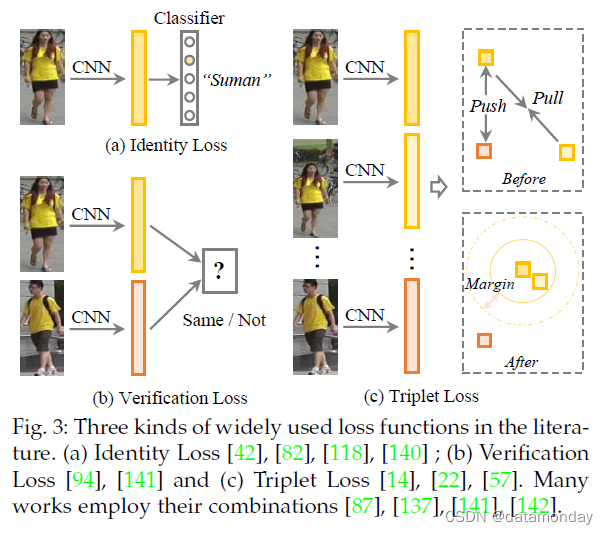
身份损失 (Identity Loss)。它将行人 Re-ID 的训练过程视为图像分类问题[55],即每个身份都是一个不同的类。在测试阶段,采用池化层或嵌入层的输出作为特征提取器。给定带有标签 yi 的输入图像 xi,xi 被识别为类别 yi 的预测概率用 softmax 函数编码,由 p(yi|xi) 表示。然后通过交叉熵计算身份损失
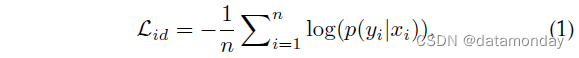
其中 n 表示每批中的训练样本数。身份损失已广泛用于现有方法 [19], [42], [82], [92], [95], [106], [118], [120], [140], [144]。一般来说,在训练过程中很容易训练和自动挖掘困难样本,如[145]所示。一些工作还研究了softmax变体[146],例如[147]中的球体损失和[95]中的AM softmax。另一种简单而有效的策略,即标签平滑 [42], [122],通常集成到标准的 softmax 交叉熵损失中。其基本思想是避免模型拟合过度自信的标注标签,提高泛化性[148]。
验证损失。它使用对比损失 [96], [120] 或二元验证损失 [43], [141] 优化成对关系。对比损失改进了相对成对距离比较,公式为
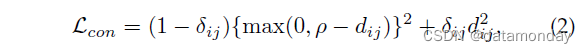
其中 dij 表示两个输入样本 xi 和 xj 的嵌入特征之间的欧几里得距离。 δij 是一个二元标签指示符(当 xi 和 xj 属于同一身份时,δij = 1,否则 δij = 0)。ρ 是边际参数。有几种变体,例如,与 [81] 中的排序 SVM 的成对比较。
二进制验证 [43], [141] 区分输入图像对的正负。通常,差分特征 fij 由 fij = (fj - fj)2 [141] 获得,其中 fi 和 fj 是两个样本 xi 和 xj 的嵌入特征。验证网络将差分特征分为正或负。使用 p(δij|fij) 来表示输入对(xi 和 xj)被识别为 δij(0 或 1)的概率。具有交叉熵的验证损失为
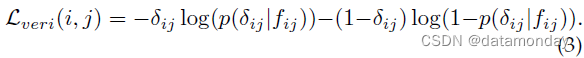
验证通常与身份损失相结合,以提高性能 [94], [96], [120], [141]。
三元组损失。它将 Re-ID 模型训练过程视为检索排序问题。基本思想是正对之间的距离应该比负对小一个预定义的边距[57]。通常,一个三元组包含一个锚样本 xi、一个具有相同身份的正样本 xj 和一个来自不同身份的负样本 xk。带边距参数的三元组损失表示为
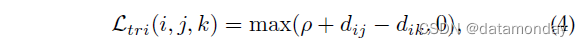
其中 d(·) 测量两个样本之间的欧几里得距离。如果直接优化上述损失函数,那么大部分容易三元组将主导训练过程,导致可辨别性有限。为了缓解这个问题,已经设计了各种信息丰富的三元组挖掘方法[14], [22], [57], [97]。基本思想是选择信息丰富的三元组[57], [149]。具体来说,
-
在[149]中引入了具有权重约束的适度正挖掘,直接优化了特征差异。
-
[57] 证明每个训练批次中最难的正负挖掘有利于判别式 Re-ID 模型学习。
-
一些方法还研究了用于信息三元组挖掘的点设置相似性策略[150],[151]。这通过软硬挖掘方案增强了对异常值样本的鲁棒性。
为了进一步丰富三元组监督,在[152]中开发了一个四元组 (quadruplet) 深度网络,其中每个四元组包含一个锚样本、一个正样本和两个挖掘的负样本。四元组是用基于边际的在线硬负挖掘来制定的。优化四元组关系会导致更小的类内变化和更大的类间变化。
Triplet loss 和 identity loss 的结合是深度Re-ID模型学习最流行的解决方案之一[28], [87], [90], [93], [103], [104], [116], [137], [142], [153], [154]。这两个组件对于判别特征表示学习是互惠互利的。
OIM 损失。除了上述三种损失函数外,还设计了一种在线实例匹配(OIM)损失[64],并采用了内存库方案。一个记忆库 {vk, k = 1, 2, · · · , c} 包含存储的实例特征,其中 c 表示类号。然后OIM损失由下式表示
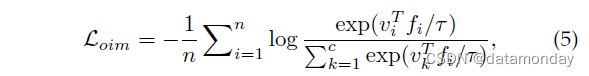
其中 vi 表示 yi 类的相应存储记忆特征,τ 是控制相似空间的温度参数 [145]。 vTi fi 衡量在线实例匹配分数。进一步包括与未标记身份的记忆特征集的比较,以计算分母 [64],处理大量非目标身份的实例。这种记忆方案也被用于无监督域适应 Re-ID [106]。
2.2.2 Training strategy
批量采样策略在判别式 Re-ID 模型学习中起着重要作用。这是具有挑战性的,因为每个身份的标注训练图像的数量变化很大[5]。同时,严重不平衡的正负样本对增加了训练策略设计的额外难度[40]。
处理不平衡问题最常用的训练策略是身份抽样 [57], [122]。对于每个训练批次,随机选择一定数量的身份,然后从每个选定的身份中抽取几张图像。这种批量采样策略保证了信息丰富的正负挖掘。
- 为了处理正负之间的不平衡问题,自适应采样是调整正负样本贡献的流行方法,例如采样率学习(SRL)[89]、类别采样[87]。
- 另一种方法是样本重新加权,使用样本分布[87]或相似性差异[52]来调整样本权重。[155] 中设计了一个有效的参考约束,将成对/三元组相似度转换为样本到参考相似度,解决不平衡问题并增强可辨别性,这对异常值也很稳健。
为了自适应地组合多个损失函数,多重损失动态训练策略 [156] 自适应地重新加权身份损失和三元组损失,提取它们之间共享的适当分量。这种多损失训练策略可以带来一致的性能提升。
2.3 Ranking Optimization
排序优化对于提高测试阶段的检索性能起着至关重要的作用。给定一个初始排名列表,它通过自动图库到图库相似性挖掘 [58], [157] 或人类交互 [158], [159] 优化排名顺序。Rank/Metric fusion [160], [161] 是另一种流行的方法,用于通过多个排名列表输入来提高排名性能。
2.3.1 Re-ranking
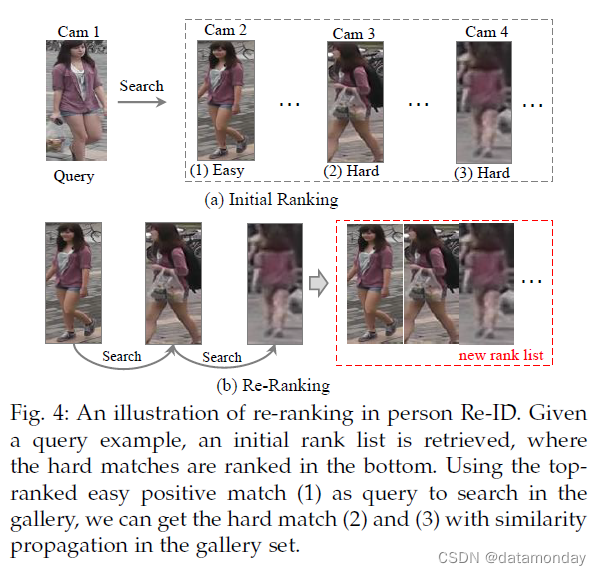
重新排序的基本思想是利用图库间 (gallery-togallery) 的相似度来优化初始排名列表,如图 4 所示。
- [157] 中提出了排名靠前的相似性拉动和排名靠后的不相似性推送。
- 广泛使用的 k-reciprocal reranking [58] 挖掘上下文信息。
- [25] 中应用了类似的上下文信息建模思想。
- [162] 利用底层流形的几何结构。
- 通过整合跨邻域距离,引入了一种扩展的跨邻域重排序方法 [18]。
- 局部模糊重新排序 [95] 采用聚类结构来改进邻域相似度测量。
查询自适应 (Query Adaptive)。考虑到查询的差异,一些方法设计了查询自适应检索策略来代替统一的搜索引擎来提高性能[163], [164]。
- [163] 提出了一种使用局部保持投影的查询自适应重新排序方法。
- [164] 中提出了一种有效的在线局部度量自适应方法,该方法通过为每个探针挖掘负样本来学习严格的局部度量。
人工交互 (Human Interaction)。它涉及使用人工反馈来优化排名列表 [158]。这在重新排序过程中提供了可靠的监督。[159] 中提出了一种混合人机增量学习模型,该模型从人的反馈中累积学习,提高了实时的 Re-ID 排名性能。
2.3.2 Rank Fusion
排名融合利用通过不同方法获得的多个排名列表来提高检索性能 [59]。
- [165] 在“L”形观察之上提出了一种查询自适应后期融合方法来融合方法。
- [59] 开发了一种利用相似性和相异性的秩聚合方法。
- 行人 Re-ID 中的等级融合过程被表述为使用图论 [166] 的基于共识的决策问题,将多个算法获得的相似度得分映射到带有路径搜索的图中。
- 最近为度量融合设计了统一集成扩散 (Unified Ensemble Diffusion, UED) [161]。 UED 保留了三种现有融合算法的优势,并通过新的目标函数和推导进行了优化。
- [160] 也研究了度量集成学习。
2.4 Datasets and Evaluation
2.4.1 Datasets and Evaluation Metrics
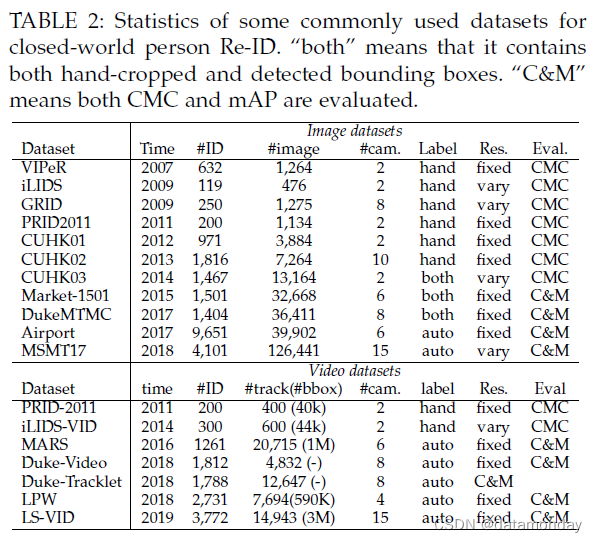
数据集。我们首先回顾了封闭世界环境中广泛使用的数据集,包括 11 个图像数据集(VIPeR [31]、iLIDS [167]、GRID [168]、PRID2011 [126]、CUHK0103 [43]、Market-1501 [5] , DukeMTMC [42], Airport [169] 和 MSMT17 [44]) 和 7 个视频数据集 (PRID-2011 [126], iLIDS-VID [7], MARS [8], Duke-Video [144], Duke-Tracklet [170]、LPW [171] 和 LS-VID [136])。这些数据集的统计数据如表 2 所示。本次调查仅关注深度学习方法的一般大规模数据集。可以在 [169] 及其 网站 1 中找到对 Re-ID 数据集的全面总结。就近年来的数据集收集而言,可以提出几点意见:
- 1)数据集规模(#image和#ID)迅速增加。一般来说,深度学习方法可以受益于更多的训练样本。这也增加了封闭世界的行行人 Re-ID 所需的标注难度。
- 2)摄像头数量也大幅增加,以逼近实际场景中的大规模摄像头网络。这也为动态更新网络中的模型泛化性带来了额外的挑战。
- 3)边界框的生成通常是自动检测/跟踪,而不是手动裁剪。这模拟了具有跟踪/检测错误的真实场景。
评估指标 (Evaluation Metrics)。为了评估 Re-ID 系统,累积匹配特性 (Cumulative Matching Characteristics, CMC) [68] 和平均平均精度 (mean Average Precision, mAP) [5] 是两个广泛使用的测量方法。
-
CMC-k(又名 Rank-k 匹配精度)[68] 表示正确匹配出现在排名前 k 的检索结果中的概率。当每个查询只存在一个真实标签时,CMC 是准确的,因为它只考虑评估过程中的第一个匹配项。但是,图库集通常包含大型相机网络中的多个真实标签,CMC不能完全反映模型跨多个相机的可辨别性。
-
另一个指标,即平均平均精度 (mAP) [5],衡量了多个真实标签的平均检索性能。它最初广泛用于图像检索。对于 Re-ID 评估,它可以解决两个系统在搜索第一个真实标签时表现相同的问题(可能很容易匹配,如图 4 所示),但对于其他硬匹配具有不同的检索能力。
考虑到训练 Re-ID 模型的效率和复杂性,最近的一些工作 [138], [139] 还报告了每秒浮点操作数(FLOPs)和网络参数大小作为评估指标。当训练/测试设备的计算资源有限时,这两个指标至关重要。
2.4.2 In-depth Analysis on State-of-The-Arts
我们从基于图像和基于视频的角度回顾了最先进的技术。我们包括过去三年在顶级 CV 场所 (venues) 发表的方法。
基于图像的重新识别。基于图像的 Re-ID 已经发表了大量论文。我们主要回顾了 2019 年发表的作品以及 2018 年的一些代表性作品。具体包括 PCB [77]、MGN [172]、PyrNet [6]、Auto-ReID [139]、ABD-Net [173]、 BagTricks [122]、OSNet [138]、DGNet [119]、SCAL [90]、MHN [174]、P2Net [104]、BDB [124]、SONA [107]、SFT [95]、ConsAtt [93]、 DenseS [103]、Pyramid [156]、IANet [108]、VAL [114]。我们总结了四个数据集的结果(图 5)。该概述激发了五个主要见解,如下所述。
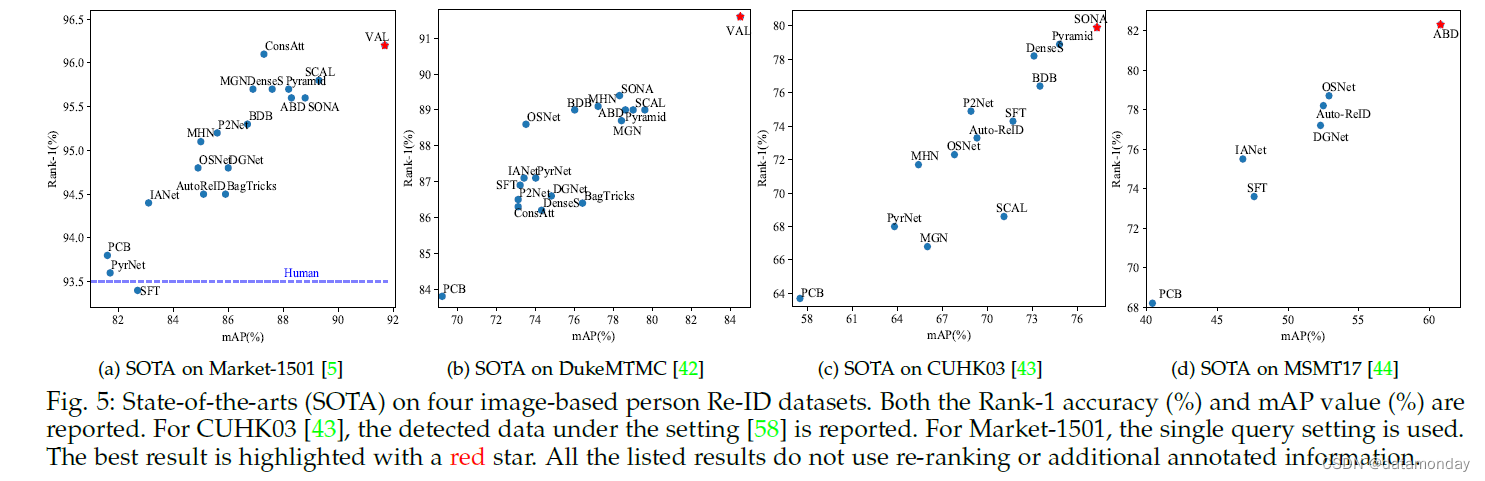
首先,随着深度学习的进步,大多数基于图像的 Re-ID 方法在广泛使用的 Market-1501 数据集上实现了比人类更高的 rank-1 准确率(93.5% [175])。特别是,VAL [114] 在 Market-1501 数据集上获得了 91.6% 的最佳 mAP 和 96.2% 的 Rank-1 准确度。 VAL 的主要优点是使用视点信息。使用重新排序或度量融合时可以进一步提高性能。在这些封闭世界数据集上深度学习的成功也促使人们将重点转移到更具挑战性的场景,即大数据量 [136] 或无监督学习 [176]。
其次,部分级特征学习有利于判别式 Re-ID 模型学习。全局特征学习直接学习整个图像的表示,没有部分约束[122]。当人检测/跟踪可以准确定位人体时,它是有区别的。当行人图像遭受大背景杂乱或严重遮挡时,部分级特征学习通常通过挖掘有区别的身体区域来获得更好的性能[67]。由于其在处理错位/遮挡方面的优势,我们观察到最近开发的大多数最先进的方法都采用了特征聚合范式,结合了部分级和全身特征[139], [156]。
第三,注意力有利于区分性的 Re-ID 模型学习。我们观察到在每个数据集上实现最佳性能的所有方法(ConsAtt [93]、SCAL [90]、SONA [107]、ABD-Net [173])都采用了注意力方案。注意力捕捉不同卷积通道、多个特征图、分层层、不同身体部位/区域甚至多个图像之间的关系。同时,结合了判别性[173]、多样化[133]、一致[93]和高阶[107]属性,以增强注意力特征学习。考虑到强大的注意力方案和 Re-ID 问题的特殊性,专注的深度学习系统很有可能继续主导 Re-ID 社区,并具有更多特定领域的属性。
第四,多损失训练可以改善 Re-ID 模型的学习。不同的损失函数从多视图的角度优化网络。结合多个损失函数可以提高性能,最先进的方法中的多重损失训练策略证明了这一点,包括 ConsAtt [93]、ABD-Net [173] 和 SONA [107]。此外,[156] 中设计了一种动态多损失训练策略,以自适应地集成两个损失函数。身份损失和三元组损失与硬挖掘相结合是首选。此外,由于不平衡问题,样本加权策略通常通过挖掘信息丰富的三元组来提高性能 [52], [89]。
最后,由于数据集规模不断扩大、环境复杂、训练样本有限,还有很大的改进空间。例如,新发布的MSMT17数据集[44]上的Rank-1准确率(82.3%)和mAP(60.8%)远低于Market-1501(Rank1:96.2%和mAP 91.7%)和DukeMTMC(Rank -1:91.6% 和 mAP 84.5%)。在其他一些训练样本有限的具有挑战性的数据集上(例如,GRID [168] 和 VIPeR [31]),性能仍然非常低。此外,Re-ID 模型通常在跨数据集评估 [28], [54] 中受到严重影响,并且在对抗性攻击下性能急剧下降 [177]。我们乐观地认为,行人 Re-ID 将会有重要的突破,具有越来越高的可辨别性、鲁棒性和普遍性。
基于视频的重新识别 (Video-based Re-ID)。与基于图像的 Re-ID 相比,基于视频的 Re-ID 受到的关注较少。我们回顾了深度学习的 Re-ID 模型,包括 CoSeg [132]、GLTR [136]、STA [135]、ADFD [110]、STC [20]、DRSA [133]、Snippet [134]、ETAP [144] 、DuATM [91]、SDM [178]、TwoS [128]、ASTPN [131]、RQEN [171]、Forest [130]、RNN [127] 和 IDEX [8]。我们还总结了四个视频 Re-ID 数据集的结果,如图 6 所示。从这些结果中,可以得出以下观察结果。
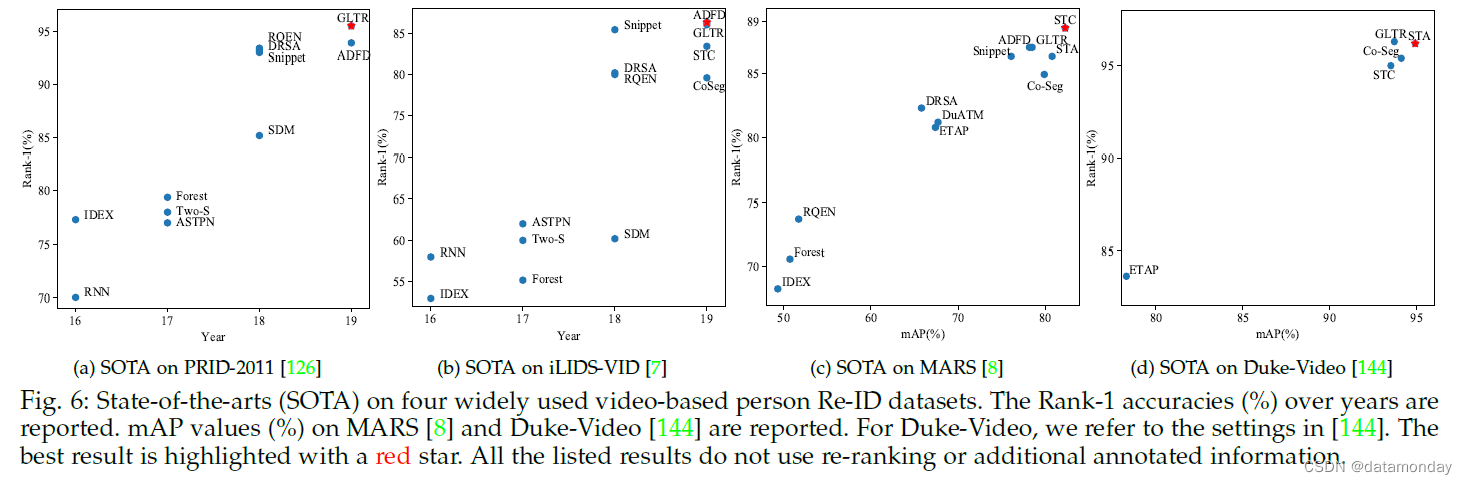
首先,随着深度学习技术的发展,多年来可以看到性能提高的明显趋势。具体来说,在 PRID-2011 数据集上,Rank-1 准确率从 70%(2016 年的 RNN [127])提高到 95.5%(2019 年的 GLTR [136]),从 58%(RNN [127])提高到 86.3%( ADFD [110])在 iLIDS-VID 数据集上。在大规模 MARS 数据集上,Rank-1 准确率/mAP 从 68.3%/49.3% (IDEX [8]) 提高到 88.5%/82.3% (STC [20])。在 Duke-Video 数据集 [144] 上,STA [135] 的 Rank-1 准确率也达到了 96.2%,mAP 为 94.9%。
其次,空间和时间建模对于判别式视频表示学习至关重要。我们观察到所有方法(STA [135]、STC [20]、GLTR [136])都设计了时空聚合策略来提高视频 Re-ID 性能。与基于图像的 ReID 类似,跨多帧 [110], [135] 的注意力方案也大大增强了可辨别性。 [20] 中另一个有趣的观察表明,利用视频序列中的多个帧可以填充被遮挡区域,这为将来处理具有挑战性的遮挡问题提供了可能的解决方案。
最后,这些数据集的性能已经达到饱和状态,这四个视频数据集的准确度增益通常不到 1%。但是,对于具有挑战性的案例,仍有很大的改进空间。例如,在新收集的视频数据集 LS-VID [136] 上,GLTR [136] 的 Rank1 accuracy/mAP 只有 63.1%/44.43%,而 GLTR [136] 可以达到 state-of-the-art 或至少在其他四个数据集上具有可比的性能。 LS-VID [136] 包含明显更多的身份和视频序列。这为基于视频的 Re-ID 的未来突破提供了具有挑战性的基准。
3 OPEN-WORLD PERSON RE-IDENTIFICATION
本节回顾第 1 节中讨论的开放世界的行人 Re-ID,包括
- 通过跨异构模式匹配行人图像的异构 Re-ID(第 3.1 节)
- 来自原始图像/视频的端到端 Re-ID(第 3.2 节)
- 带有有限/不可用标注标签的半/无监督学习(第 3.3 节)
- 具有噪声标注的鲁棒 Re-ID 模型学习(第 3.4 节)
- 在图库中未出现正确匹配时的开放集行人 Re-ID(第 3.5 节)
3.1 Heterogeneous Re-ID
本小节总结了四种主要的异构 Re-ID,包括
- 深度和 RGB 图像之间的 Re-ID(§ 3.1.1)
- 文本到图像的 Re-ID(§ 3.1.2)
- 可见到红外的 Re-ID(§ 3.1.3)
- 交叉分辨率 Re-ID(§ 3.1.4)
3.1.1 Depth-based Re-ID
深度图像捕捉身体形状和骨骼信息。这为在照明/换衣环境下进行 Re-ID 提供了可能性,这对于个性化的人类交互应用也很重要。 [179] 中提出了一种基于循环注意力的模型来解决基于深度的行人识别问题。
在强化学习框架中,他们结合卷积和循环神经网络来识别人体的小的、有区别的局部区域。
[180] 利用大型 RGB 数据集设计了一种拆分率 RGB 到深度的传输方法,该方法弥合了深度图像和 RGB 图像之间的差距。他们的模型进一步结合了时间关注来增强深度 Re-ID 的视频表示。
一些方法 [62], [181] 还研究了 RGB 和深度信息的组合以提高 Re-ID 性能,解决换衣服的挑战。
3.1.2 Text-to-Image Re-ID
Text-to-image Re-ID 解决了文本描述和 RGB 图像 [63] 之间的匹配问题。当无法获取查询人的视觉图像时,必须提供,只能提供文字描述。
具有循环神经网络的门控神经注意力模型 [63] 学习文本描述和行人图像之间的共享特征。这使得文本到图像行人检索的端到端训练成为可能。
- [182] 提出了一种全局判别图像-语言关联学习方法,在重建过程中捕获身份判别信息和局部重建图像-语言关联。
- 交叉投影学习方法 [183] 还通过图像到文本匹配来学习共享空间。
- 在 [184] 中设计了一个深度对抗图注意力卷积网络,其中包含图关系挖掘。
- 然而,文本描述和视觉图像之间的巨大语义差距仍然具有挑战性。同时,如何将文字与手绘素描图像结合起来也值得今后研究。
3.1.3 Visible-Infrared Re-ID
Visible-Infrared Re-ID 处理白天可见光和夜间红外图像之间的交叉模态匹配。这在低光照条件下很重要,在这种情况下,图像只能由红外摄像机 [21], [60], [185] 捕获。
- [21] 通过提出一个深度零填充框架 [21] 来自适应地学习模态可共享特征,开始了解决这个问题的第一次尝试。
- 在 [142], [186] 中引入了一个双流网络来对模态共享和特定信息进行建模,同时解决模态内和跨模态的变化。
- 除了交叉模态共享嵌入学习 [187],分类器级别的差异也在 [188] 中进行了研究。
- 最近的方法 [189], [190] 采用 GAN 技术生成跨模态行人图像,以减少图像和特征级别的跨模态差异。
- [191] 中对分层交叉模态解缠结因素进行了建模。
- [192] 中提出了一种双注意聚合学习方法来捕获多级关系。
3.1.4 Cross-Resolution Re-ID
Cross-Resolution Re-ID 在低分辨率和高分辨率图像之间进行匹配,解决大分辨率变化 [13], [14]。级联 SR-GAN [193] 以级联方式生成高分辨率行人图像,并结合身份信息。[194] 采用对抗学习技术来获得分辨率不变的图像表示。
3.2 End-to-End Re-ID
端到端的 Re-ID 减轻了对生成边界框的额外步骤的依赖。它涉及从原始图像或视频中重新识别行人,以及多摄像头跟踪。
原始图像/视频中的重识别 (Re-ID in Raw Images/Videos) 此任务要求模型在单个框架中联合执行行人检测和重识别 [55], [64]。由于两个主要组成部分的侧重点不同,因此具有挑战性。
- [55] 提出了一个两阶段框架,并系统地评估了后期行人 Re-ID 的行人检测的好处和局限性。
- [64] 使用单个卷积神经网络设计端到端行人搜索系统,用于联合行人检测和重新识别。
- [195] 开发了一种神经行人搜索机(NPSM),通过充分利用查询和检测到的候选区域之间的上下文信息来递归地细化搜索区域并定位目标人。
- 类似地,在图学习框架中学习上下文实例扩展模块 [196] 以改进端到端行人搜索。
- 使用 Siamese 挤压和激励网络开发了一个查询引导的端到端行人搜索系统 [197],以通过查询引导的区域提议生成来捕获全局上下文信息。
- [198] 中引入了一种具有判别性 Re-ID 特征学习的定位细化方案,以生成更可靠的边界框。
- 身份鉴别注意力强化学习(IDEAL)方法 [199] 为自动生成的边界框选择信息区域,从而提高 Re-ID 性能。
[200] 研究一个更具挑战性的问题,即从带有文本描述的原始视频中搜索人。提出了一种时空行人检测和多模态检索的多阶段方法。预计沿着这个方向进一步探索。
多摄像头跟踪 (Multi-camera Tracking) 端到端行人重识别也与多人、多摄像头跟踪密切相关[52]。
针对多人跟踪 [201],提出了一种基于图的公式来链接人的假设,其中将整个人体和身体姿势布局的整体特征组合为每个人的表示。[52] 通过硬身份挖掘和自适应加权三元组学习来学习多目标多摄像机跟踪和行人 Re-ID 之间的相关性。最近,提出了一种具有相机内和相机间关系建模的局部感知外观度量(LAAM)[202]。
3.3 Semi-supervised and Unsupervised Re-ID
3.3.1 Unsupervised Re-ID
早期的无监督 Re-ID 主要学习不变的组件,即字典 [203]、度量 [204] 或显着性 [66],这导致可辨别性或可扩展性有限。
对于深度无监督的方法,跨相机标签估计是一种流行的方法[176],[205]。动态图匹配(DGM)[206]将标签估计公式化为二分图匹配问题。为了进一步提高性能,利用全局相机网络约束[207]进行一致匹配。通过逐步度量提升[204]逐步挖掘标签。一种鲁棒的锚嵌入方法[83]迭代地将标签分配给未标记的轨迹,以扩大锚视频序列集。通过估计的标签,可以应用深度学习来学习 Re-ID 模型。
对于端到端无监督 Re-ID,在 [205] 中提出了一种迭代聚类和 Re-ID 模型学习。
-
类似地,样本之间的关系被用于层次聚类框架[208]。
-
软多标签学习 [209] 从参考集中挖掘软标签信息以进行无监督学习。
-
Tracklet Association 无监督深度学习 (TAUDL) 框架 [170] 共同进行相机内 tracklet 关联并模拟跨相机 tracklet 相关性。
-
类似地,一种无监督的相机感知相似性一致性挖掘方法[210]也在粗到细的一致性学习方案中提出。
-
相机内挖掘和相机间关联应用于图关联框架[211]。
-
可转移联合属性-身份深度学习(TJAIDL)框架[111]也采用了语义属性。然而,使用新到达的未标记数据进行模型更新仍然具有挑战性。
此外,一些方法还尝试基于观察到局部部分的标签信息比整个图像更容易挖掘标签信息来学习部分级表示。
- PatchNet [153] 旨在通过挖掘补丁级别相似性来学习有区别的补丁特征。
- 自相似性分组(SSG)方法[212]以自定进度的方式迭代地进行分组(利用全局身体和局部部位的相似性进行伪标记)和 Re-ID 模型训练。
半/弱监督 Re-ID (Semi-/Weakly supervised Re-ID)。在标签信息有限的情况下,[213] 中提出了一种一次性度量学习方法,该方法结合了深度纹理表示和颜色度量。 [144] 中提出了一种逐步单次学习方法(EUG),用于基于视频的 Re-ID,逐渐从未标记的 tracklet 中选择一些候选者来丰富标记的 tracklet 集。多实例注意力学习框架[214]使用视频级标签进行表示学习,减轻了对完整标注的依赖。
3.3.2 Unsupervised Domain Adaptation
无监督域适应(UDA)将标记的源数据集上的知识转移到未标记的目标数据集[53]。由于源数据集中的大域转移和强大的监督,它是另一种没有目标数据集标签的无监督 Re-ID 的流行方法。
目标图像生成。使用 GAN 生成将源域图像转换为目标域样式是 UDA Re-ID 的一种流行方法。使用生成的图像,这可以在未标记的目标域中进行有监督的 Re-ID 模型学习。
- [44] 提出了一种行人迁移生成对抗网络(PTGAN),将知识从一个标记的源数据集传输到未标记的目标数据集。
- 保留的自相似性和域相异性 [120] 使用保留相似性的生成对抗网络 (SPGAN) 进行训练。
- 异构学习(HHL)方法 [215] 同时考虑了同质学习的相机不变性和异构学习的域连通性。
- 自适应传输网络 [216] 将自适应过程分解为某些成像因素,包括光照、分辨率、相机视图等。这种策略提高了跨数据集的性能。
- [217] 尝试抑制背景偏移以最小化域偏移问题。
- [218] 设计了一种实例引导的上下文渲染方案,将人的身份从源域转移到目标域中的不同上下文中。
- 此外,还添加了一个姿势解纠缠方案来改进图像生成 [121]。
- [219] 还开发了一种相互平均教师学习方案 (A mutual mean-teacher learning scheme)。
- 然而,实际大规模变化环境的图像生成的可扩展性和稳定性仍然具有挑战性。
[125] 生成具有不同照明条件的合成数据集,以模拟真实的室内和室外照明。合成的数据集增加了学习模型的泛化性,并且可以很容易地适应新的数据集而无需额外的监督 [220]。
目标域监督挖掘。一些方法使用来自源数据集的训练有素的模型直接挖掘对未标记目标数据集的监督。
- 示例记忆学习方案 [106] 将三个不变线索视为监督,包括示例不变性、相机不变性和邻域不变性。
- 域不变映射网络(DIMN)[28]为域迁移任务制定了一个元学习管道,并在每个训练集对源域的一个子集进行采样以更新内存库,从而增强可扩展性和可辨别性。
- 摄像机视图信息也在[221]中用作监督信号以减少域间隙。
- 一种具有渐进增强的自我训练方法 [222] 联合捕获目标数据集上的局部结构和全局数据分布。
- 最近,一种具有混合记忆的自定进度对比学习框架 [223] 取得了巨大成功,它可以动态生成多级监督信号。
时空信息也被用作 TFusion [224] 中的监督。TFusion 使用贝叶斯融合模型将在源域中学习到的时空模式转移到目标域。同样,开发了 Query Adaptive Convolution (QAConv) [225] 以提高跨数据集的准确性。
3.3.3 State-of-The-Arts for Unsupervised Re-ID
近年来,无监督 Re-ID 获得了越来越多的关注,顶级场所的出版物数量不断增加就是明证。我们回顾了 SOTA 在两个广泛使用的基于图像的 Re-ID 数据集上的无监督深度学习方法。结果总结在表 3 中。从这些结果中,可以得出以下见解。
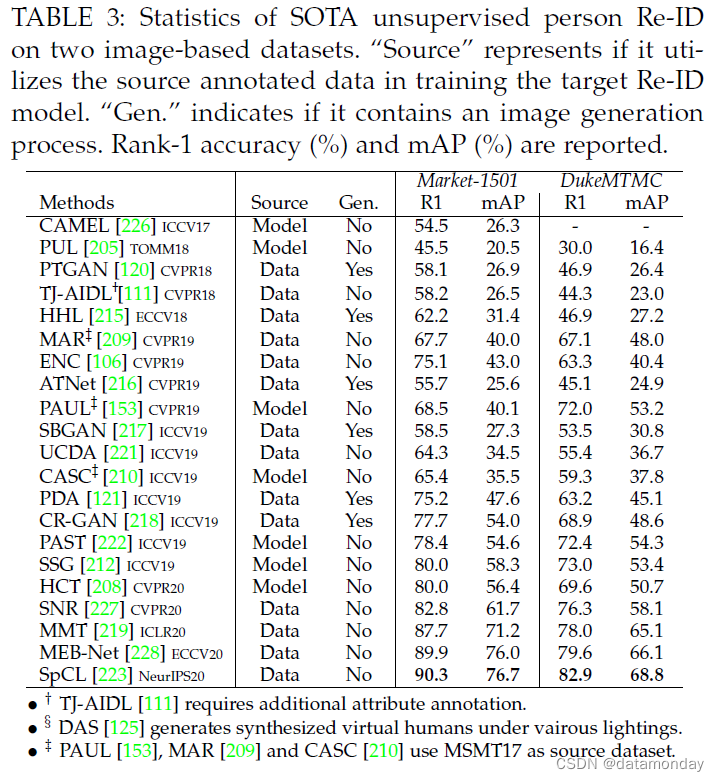
首先,无监督的 Re-ID 性能多年来显着提高。 Market-1501 数据集的 Rank-1 准确率/mAP 在三年内从 54.5%/26.3% (CAMEL [226]) 增加到 90.3%/76.7% (SpCL [223])。 DukeMTMC 数据集的性能从 30.0%/16.4% 提高到 82.9%/68.8%。监督上界和无监督学习之间的差距显着缩小。这证明了无监督 Re-ID 与深度学习的成功。
其次,目前的无监督 Re-ID 仍然不发达,可以在以下方面进一步改进:
- 1)监督 ReID 方法中强大的注意力方案很少应用于无监督 ReID。
- 2)目标域图像生成已在某些方法中被证明是有效的,但它们并未应用于两种最佳方法(PAST [222],SSG [212])。
- 3)在目标域的训练过程中使用带标注的源数据有利于跨数据集学习,但也不包括在上述两种方法中。这些观察结果为进一步改进提供了潜在基础。
第三,无监督和有监督的 Re-ID 之间仍然存在很大差距。例如,有监督的 ConsAtt [93] 在 Market1501 数据集上的 rank-1 准确率已达到 96.1%,而无监督 SpCL [223] 的最高准确率约为 90.3%。最近,[229] 已经证明,具有大规模未标记训练数据的无监督学习能够在各种任务上优于监督学习 [230]。我们预计未来无监督 Re-ID 会取得一些突破。
3.4 Noise-Robust Re-ID
由于数据收集和标注困难,Re-ID 通常会遇到不可避免的噪声。我们从三个方面回顾了噪声鲁棒性 Re-ID:
- 具有严重遮挡的部分 Re-ID
- 具有由检测或跟踪错误引起的样本噪声的 Re-ID
- 具有由标注错误引起的标签噪声的 Re-ID
部分重新识别 (Partial Re-ID)。这解决了重度遮挡的 Re-ID 问题,即只有人体的一部分是可见的 [231]。
- 采用全卷积网络[232]为不完整的行人图像生成固定大小的空间特征图。
- 深度空间特征重建 (DSR) 被进一步结合,以避免通过利用重建误差进行显式对齐。
- [67] 设计了一个可见性感知零件模型(VPM)来提取可共享的区域级特征,从而抑制不完整图像中的空间错位。
- 前景感知金字塔重建方案[233]也试图从未被遮挡的区域中学习。
- Pose-Guided Feature Alignment (PGFA) [234] 利用姿势界标从遮挡噪声中挖掘有区别的部分信息。然而,由于严重的部分错位、不可预测的可见区域和分散注意力的未共享身体区域,它仍然具有挑战性。同时,如何针对不同的查询自适应地调整匹配模型仍需进一步研究。
使用样本噪声重新识别 (Re-ID with Sample Noise)。这是指行人图像或视频序列包含边缘区域/帧的问题,这可能是由于检测不佳/跟踪结果不准确造成的。为了处理行人图像中的外围区域或背景杂乱,利用了姿势估计线索[17], [18]或注意力线索[22], [66], [199]。基本思想是抑制噪声区域在最终整体表示中的贡献。对于视频序列,集级特征学习[83]或帧级重新加权[134]是减少噪声帧影响的常用方法。侯等人。 [20] 还利用多个视频帧来自动完成遮挡区域。预计未来会有更多特定领域的样本噪声处理设计。
使用标签噪声重新识别 (Re-ID with Label Noise)。由于标注错误,标签噪声通常是不可避免的。郑等人。采用标签平滑技术来避免标签过度拟合问题[42]。 [235] 中提出了一种对特征不确定性进行建模的分布网络 (DNet),用于针对标签噪声进行稳健的 Re-ID 模型学习,从而减少具有高特征不确定性的样本的影响。与一般分类问题不同,鲁棒的 Re-ID 模型学习受到每个身份的训练样本有限 [236] 的影响。此外,未知的新身份增加了鲁棒 Re-ID 模型学习的额外难度。
3.5 Open-set Re-ID and Beyond
Open-set Re-ID 通常被表述为一个人验证问题,即区分两个人图像是否属于同一身份[69], [70]。验证通常需要学习条件 τ,即 sim(query, gallery) > τ。早期的研究设计了手工系统 [26], [69], [70]。对于深度学习方法,[237] 中提出了 Adversarial PersonNet (APN),它联合学习了 GAN 模块和 Re-ID 特征提取器。该 GAN 的基本思想是生成逼真的类似目标的图像(冒名顶替者)并强制特征提取器对生成的图像攻击具有鲁棒性。 [235] 中还研究了建模特征不确定性。然而,实现高真实目标识别并保持低错误目标识别率仍然相当具有挑战性[238]。
组重新识别 (Group Re-ID)。它旨在将人与群体而不是个人联系起来[167]。早期的研究主要集中在稀疏字典学习[239]或协方差描述符聚合[240]的组表示提取上。多粒度信息集成在[241]中,以充分捕捉群体的特征。最近,图卷积网络被应用在[242]中,将组表示为一个图。组相似性也应用于端到端行人搜索[196]和个体重新识别[197], [243],以提高准确性。然而,组 Re-ID 仍然具有挑战性,因为组变化比个体更复杂。
动态多摄像机网络 (Dynamic Multi-Camera Network)。动态更新的多相机网络是另一个具有挑战性的问题 [23], [24], [27], [29],它需要对新相机或探测器进行模型调整。 [24] 中引入了一种人工在环增量学习方法来更新 Re-ID 模型,使表示适应不同的探针库。早期研究还将主动学习 [27] 应用于多摄像头网络中的连续 Re-ID。 [23]中介绍了一种基于稀疏非冗余代表选择的连续自适应方法。传递推理算法 [244] 旨在利用基于测地线流内核的最佳源相机模型。密集人群和社会关系中的多个环境约束(例如,相机拓扑)被集成到一个开放世界的行人 Re-ID 系统 [245]。摄像机的模型适应和环境因素在实际的动态多摄像机网络中至关重要。此外,如何将深度学习技术应用于动态多摄像头网络的研究还较少。
4 AN OUTLOOK: RE-ID IN NEXT ERA
本节首先在第 4.1 节中介绍了一个新的评估指标,即行人 Re-ID 的强基线(在第 4.2 节中)。它为未来的Re-ID研究提供了重要的指导。最后,我们将在第 4.3 节中讨论一些研究不足的未解决问题。
4.1 mINP: A New Evaluation Metric for Re-ID

对于一个好的 Re-ID 系统,目标人应该被尽可能准确地检索到,即所有正确的匹配应该具有低排名值。考虑到目标行人在排名靠前的检索列表中不应被忽视,尤其是对于多摄像头网络,从而准确跟踪目标。当目标行人出现在多个时间戳集合中时,最难正确匹配的排名位置决定了检查员进一步调查的工作量。然而,目前广泛使用的 CMC 和 mAP 指标无法评估该属性,如图 7 所示。在相同的 CMC 下,rank list 1 比 rank list 2 获得更好的 AP,但需要更多的努力才能找到所有正确的匹配项.为了解决这个问题,我们设计了一种计算效率高的度量,即负惩罚(NP),它测量惩罚以找到最难的正确匹配
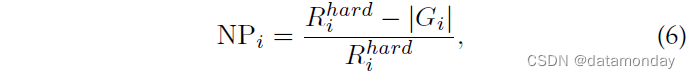
其中 Rhardi 表示最难匹配的排名位置,|Gi|表示查询 i 的正确匹配总数。自然,较小的 NP 代表更好的性能。为了与 CMC 和 mAP 保持一致,我们更喜欢使用逆负惩罚 (INP),它是 NP 的逆运算。总体而言,所有查询的平均 INP 表示为
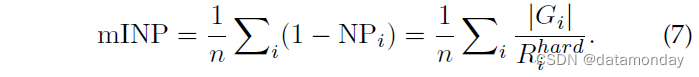
mINP 的计算非常高效,可以无缝集成到 CMC/mAP 计算过程中。 mINP 避免了 mAP/CMC 评估中容易匹配的支配。一个限制是与小型图库相比,大型图库的 mINP 值差异会小得多。但它仍然可以反映 Re-ID 模型的相对性能,为广泛使用的 CMC 和 mAP 指标提供补充。
4.2 A New Baseline for Single-/Cross-Modality Re-ID
根据第 2.4.2 节中的讨论,我们为 行人 Re-ID 设计了一个新的 AGW3 基线,它在单模态(图像和视频)和跨模态 Re-ID 任务上都取得了竞争性能。具体来说,我们的新基线是在 BagTricks [122] 之上设计的,AGW 包含以下三个主要改进组件:
1)非局部注意力(Att)块。如第 2.4.2 节所述,注意方案在判别式 Re-ID 模型学习中起着至关重要的作用。我们采用强大的非局部注意力块[246]来获得所有位置特征的加权和,表示为
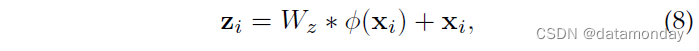
其中 Wz 是要学习的权重矩阵,φ(·) 表示非局部操作,+xi 制定残差学习策略。细节可以在[246]中找到。我们采用 [246] 中的默认设置来插入非局部注意力块。
2)广义平均 (GeM) 池化。作为细粒度的实例检索,广泛使用的最大池化或平均池化无法捕获特定领域的判别特征。我们采用了一个可学习的池化层,称为广义均值(GeM)池化 [247],其公式为
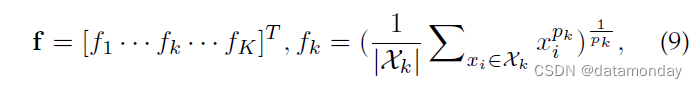
其中 fk 表示特征图,K 是最后一层中特征图的数量。 Xk 是特征图 k ∈ {1, 2, · · · , K} 的 W × H 激活集。 pk 是一个池化超参数,在反向传播过程中学习[247]。上述操作近似于 pk → ∞ 时的最大池化和 pk = 1 时的平均池化。
3)加权正则化三元组 (WRT) 损失。除了使用 softmax 交叉熵的基线身份损失之外,我们还集成了另一个加权正则化三元组损失,
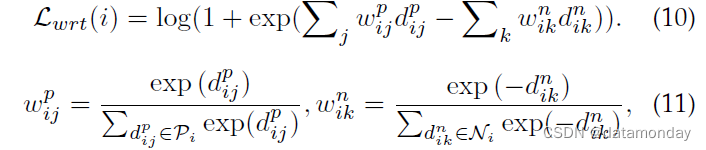
其中 (i, j, k) 表示每个训练批次中的硬三元组。对于anchor i,Pi是对应的正集,Ni是负集。 dp ij/dnik 表示正/负样本对的成对距离。上述加权正则化继承了正负对之间相对距离优化的优点,但它避免引入任何额外的边距参数。我们的加权策略类似于 [248],但我们的解决方案没有引入额外的超参数。
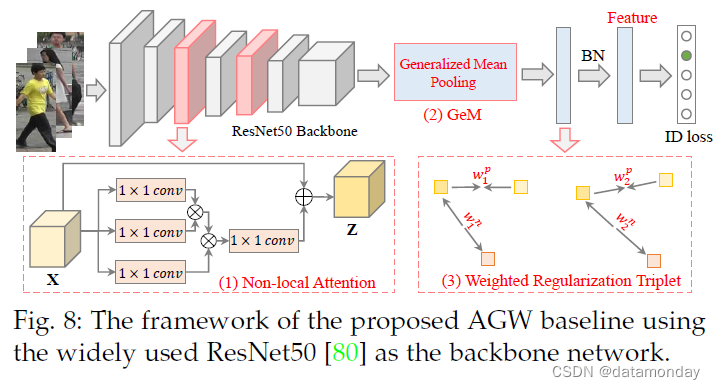
AGW 的总体框架如图8所示。其他组件与[122]完全相同。在测试阶段,采用BN层的输出作为Re-ID的特征表示。实施细节和更多实验结果在补充材料中。
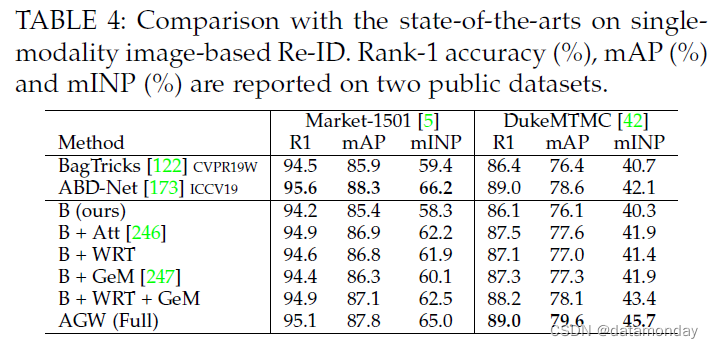
单模态图像重识别结果。我们首先在表 4 中的两个基于图像的数据集(Market1501 和 DukeMTMC)上评估每个组件。我们还列出了两种最先进的方法,BagTricks [122] 和 ABD-Net [173]。我们在表 5 中报告了 CUHK03 和 MSMT17 数据集的结果。
我们获得了以下两个观察结果:
1)所有组件始终有助于提高准确性,并且 AGW 在各种指标下的表现都比原始 BagTricks 好得多。 AGW 为未来的改进提供了强有力的基准。我们还尝试结合部分级特征学习 [77],但大量实验表明它并没有提高性能。如何将part-level的特征学习与AGW进行聚合,未来需要进一步研究。
2)与当前最先进的 ABD-Net [173] 相比,AGW 在大多数情况下表现良好。特别是,我们在 DukeMTMC 数据集上实现了更高的 mINP,分别为 45.7% 和 42.1%。这表明 AGW 找到所有正确匹配项所需的工作更少,验证了 mINP 的能力。
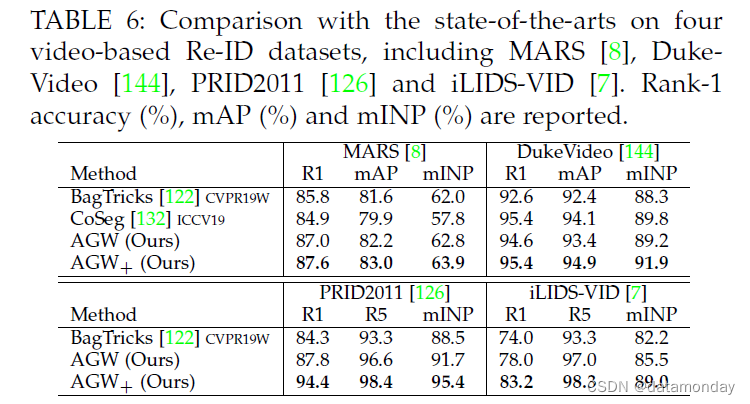
单模态视频重识别结果。我们还在四个广泛使用的基于单模态视频的数据集(MARS [8]、DukeVideo [144]、PRID2011 [126] 和 iLIDS-VID [7])上评估了提议的 AGW,如表 6 所示。我们还比较了两种状态最先进的方法,BagTricks [122] 和 Co-Seg [132]。对于视频数据,我们开发了一个变体 (AGW+) 来捕获时间信息,通过帧级平均池化来进行序列表示。同时,约束随机抽样策略[133] 用于训练。与 Co-Seg [132] 相比,我们的 AGW+ 在大多数情况下获得了更好的 Rank-1、mAP 和 mINP。
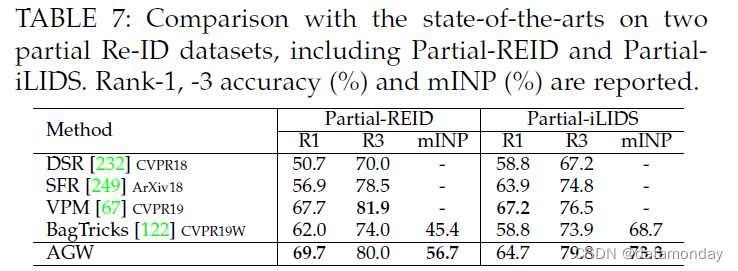
在 Partial Re-ID 上的结果。我们还在两个部分 Re-ID 上测试了 AGW 的性能-ID 数据集,如表 7 所示。实验设置来自 DSR [232]。我们还实现了与最先进的 VPM 方法 [67] 相当的性能。该实验进一步证明了 AGW 在open-world partial Re-ID task. 同时,mINP 也展示了这个 open-world Re-ID 问题的适用性。
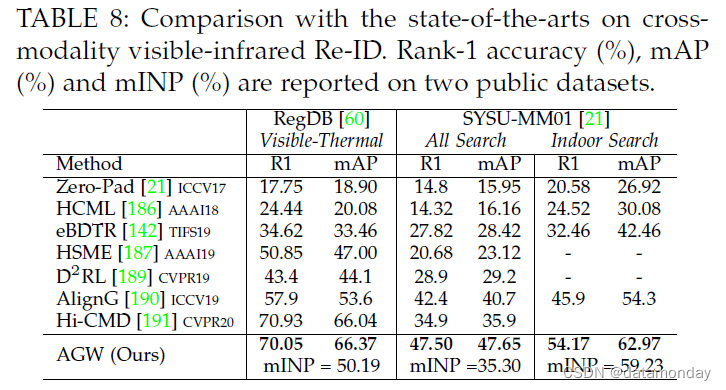
跨模态重识别的结果。我们还在跨模态可见红外 Re-ID 任务上使用双流架构测试了 AGW 的性能。在两个数据集上与当前最先进技术的比较如表 8 所示。我们按照 AlignG [190] 中的设置进行实验。结果表明,AGW 比现有的跨模态 Re-ID 模型实现了更高的准确度,验证了开放世界 Re-ID 任务的有效性。
4.3 Under-Investigated Open Issues
我们根据§1中的五个步骤从五个不同方面讨论开放问题,包括不可控的数据收集、人工标注最小化、特定领域/可概括的架构设计、动态模型更新和高效模型部署。
4.3.1 Uncontrollable Data Collection
大多数现有的 Re-ID 作品在定义明确的数据收集环境中评估他们的方法。然而,真实复杂环境中的数据采集是不可控的。数据可能是从不可预测的模态、模态组合,甚至是衣服有变化的数据中获取的 [30]。
多异构数据。在实际应用中,ReID 数据可能是从多种异构模态中捕获的,即行人图像的分辨率变化很大 [193],查询集和图库集可能包含不同的模态(可见、热 [21]、深度 [62] ] 或文字描述 [10])。这导致了具有挑战性的多个异类行人 Re-ID。一个好的人重识别系统将能够自动处理不断变化的分辨率、不同的模式、各种环境和多个领域。预计未来的工作具有广泛的普遍性,评估他们针对不同 Re-ID 任务的方法。
衣服改变数据 (Cloth-Changing Data)。在实际的监控系统中,很可能会包含大量正在换衣服的目标行人。服装变化感知网络(CCAN)[250]通过分别提取面部和身体上下文表示来解决这个问题,并且在[251]中应用了类似的想法。[30] 提出了一种空间极坐标变换 (SPT) 来学习跨衣服不变表示。但是,它们仍然严重依赖面部和身体外观,这在实际场景中可能不可用且不稳定。进一步探索其他判别线索(例如步态、形状)来解决换布问题的可能性会很有趣。
4.3.2 Human Annotation Minimization
除了无监督学习,主动学习或人机交互 [24], [27], [154], [159] 提供了另一种可能的解决方案来减轻对人工标注的依赖。
主动学习 (Active Learning)。结合人工交互,可以轻松地为新到达的数据提供标签,并且可以随后更新模型 [24], [27]。成对子集选择框架 [252] 通过首先构建一个边加权的完整 kpartite 图,然后将其作为无三角形子图最大化问题来解决,从而最大限度地减少人工标记工作。沿着这条线,深度强化主动学习方法 [154] 迭代地改进学习策略,并通过人工在环监督训练一个 Re-ID 网络。对于视频数据,设计了一种具有顺序决策的可解释强化学习方法[178]。主动学习在实际的 Re-ID 系统设计中至关重要,但在研究界却很少受到关注。此外,即使对人类来说,新出现的身份也极具挑战性。未来有望实现高效的人类在环主动学习。
学习虚拟数据 (Learning for Virtual Data)。这为最小化人工标注提供了替代方案。在 [220] 中收集了一个合成数据集进行训练,当在这个合成数据集上训练时,它们在真实世界的数据集上取得了有竞争力的表现。[125] 生成具有不同照明条件的新合成数据集,以模拟逼真的室内和室外照明。在 [105] 中收集了一个大规模的合成 PersonX 数据集,以系统地研究视点对行人 Re-ID 系统的影响。最近,[253] 还研究了 3D 行人图像,从 2D 图像生成 3D 身体结构。然而,如何弥合合成图像和真实世界数据集之间的差距仍然具有挑战性。
4.3.3 Domain-Specific/Generalizable Architecture Design
Re-ID 特定架构。现有的 Re-ID 方法通常采用为图像分类设计的架构作为主干。一些方法修改架构以实现更好的 Re-ID 功能 [82], [122]。最近,研究行人已经开始设计特定领域的架构,例如具有全方位特征学习的 OSNet [138]。它在一定尺度上检测小尺度的判别特征。 OSNet 是极其轻量级的并且实现了具有竞争力的性能。随着自动神经架构搜索(例如,Auto-ReID [139])的进步,更多特定领域的强大架构有望解决特定于任务的 Re-ID 挑战。 Re-ID 中有限的训练样本也增加了架构设计的难度。
域可泛化的 Re-ID。众所周知,不同数据集 [56], [225] 之间存在很大的域差距。大多数现有方法采用域适应进行跨数据集训练。一个更实用的解决方案是学习具有多个源数据集的域泛化模型,这样学习的模型可以推广到新的未见数据集,以进行有区别的 ReID,而无需额外的训练 [28]。[254] 通过引入部分级 CNN 框架研究了跨数据集的人 Re-ID。 Domain-Invariant Mapping Network (DIMN) [28] 设计了一个用于域可泛化 Re-ID 的元学习管道,学习行人图像与其身份分类器之间的映射。域泛化性对于在未知场景下部署学习到的 Re-ID 模型至关重要。
4.3.4 Dynamic Model Updating
固定模型不适用于实际的动态更新监控系统。为了缓解这个问题,动态模型更新势在必行,无论是针对新域/相机还是适应新收集的数据。
模型适应新领域/相机 (Model Adaptation to New Domain/Camera)。模型适应新领域已在文献中被广泛研究为领域适应问题[125],[216]。在实际的动态摄像机网络中,新的摄像机可能会临时插入到现有的监控系统中。模型适应对于多摄像头网络中的连续识别至关重要 [23], [29]。为了使学习模型适应新相机,传递推理算法 [244] 旨在利用基于测地线流内核的最佳源相机模型。但是,当新相机新收集的数据具有完全不同的分布时,仍然具有挑战性。此外,隐私和效率问题[255]也需要进一步考虑。
使用新到达的数据更新模型 (Model Updating with Newly Arriving Data)。使用新收集的数据,从头开始训练先前学习的模型是不切实际的 [24]。在 [24] 中设计了一种增量学习方法以及人类交互。对于深度学习的模型,将使用协方差损失 [256] 的加法集成到整体学习功能中。然而,由于深度模型训练需要大量的训练数据,这个问题没有得到很好的研究。此外,新到达的数据中未知的新身份难以识别用于模型更新。
4.3.5 Efficient Model Deployment
设计高效且自适应的模型以解决实际模型部署的可扩展性问题非常重要。
快速重新识别 (Fast Re-ID)。为了快速检索,散列已被广泛研究以提高搜索速度,近似于最近邻搜索[257]。跨相机语义二进制变换(CSBT)[258]将原始的高维特征表示转换为紧凑的低维身份保持二进制代码。在[259]中开发了一种粗到细(CtF)散列码搜索策略,互补地使用短码和长码。但是,特定领域的散列仍然需要进一步研究。
轻量级模型 (Lightweight Model)。解决可扩展性问题的另一个方向是设计一个轻量级的 Re-ID 模型。在 [86], [138], [139] 中研究了修改网络架构以实现轻量级模型。模型蒸馏是另一种方法,例如,在 [260] 中提出了一种多教师自适应相似性蒸馏框架,它从多个教师模型中学习用户指定的轻量级学生模型,而无需访问源域数据。
资源感知重识别 (Resource Aware Re-ID)。根据硬件配置自适应地调整模型也提供了处理可扩展性问题的解决方案。 Deep Anytime ReID (DaRe) [14] 采用简单的基于距离的路由策略来自适应地调整模型,以适应具有不同计算资源的硬件设备。
5 CONCLUDING REMARKS
本文从封闭世界和开放世界的角度进行了全面调查,并进行了深入分析。我们首先从特征表示学习、深度度量学习和排名优化三个方面介绍封闭世界设置下广泛研究的行人 Re-ID。借助强大的深度学习,封闭世界的行人 Re-ID 在多个数据集上实现了性能饱和。相应地,开放世界的设置最近受到越来越多的关注,努力应对各种实际挑战。我们还设计了一个新的 AGW 基线,它在各种指标下的四个 Re-ID 任务上实现了具有竞争力的性能。它为未来的改进提供了强有力的基准。该调查还引入了一个新的评估指标来衡量找到所有正确匹配项的成本。我们相信这项调查将为未来的 Re-ID 研究提供重要的指导。