引言
这篇文章是李宏毅机器学习视频的笔记。这是我见过最简单的机器学习入门视频,没有之一。
本文主要介绍线性回归。
回归分析
它的输出是一个标量(数值),叫做回归(Regression)
机器学习的三步走
以宝可梦为例。
找到一个函数,输入一个宝可梦(神奇宝贝)的属性(特征),输出它进化后的战斗力(Combat Power,CP值)。

是进化前的CP值, 是它所属的种类, 表示它的血量, 表示它的重量, 表示它的高度。
设计模型
设计模型,也就是确定一组函数。
假设进化后的CP值与进化前的CP有很大关系,我们可以将这个函数组写成: 的形式。
其中b和w称为(模型的)参数。
对于不同的b和w,就能得到不同的函数。
上面这个模型称为线性模型:
其中 可换成不同的属性,比如 。
要知道该放入哪些属性,需要一些领域知识。比如进化前的CP肯定和进化后的CP值有关。
上面多次说到的属性在机器学习中叫做特征(feature), 称之为权重, 称之为偏移量(bias)。
x是一个特征(feature)向量
判断函数的好坏
得到了一组函数后,我们需要判断函数的好坏,从而从中选择最好的函数来进行预测进化后的CP值。
那么如何判断呢?我们需要收集训练的资料,这个训练的资料必须包含输入数据(宝可梦的特征)和输出数据(这里是标量,CP值)之间的关系。
也就是同时包含原CP值和进化后CP值的数据。
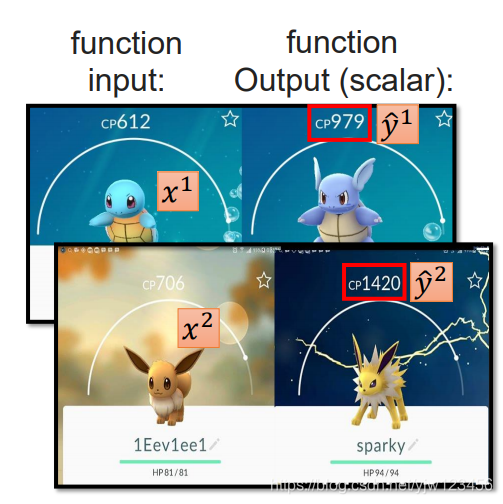
如上图,我们有一只小乌龟,并且知道它进化后的数据。
其中
来表示第一份资料(数据),还记得上面用下标
来表示它的特征吗,
结合起来,
表示第一个神奇宝贝的CP值。
表示它相应的观测到的输出值(进化后的CP值)。
假设我们抓10只宝可梦,同时知道CP值和进化后的CP值。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c1hFMwWh-1573375434150)(_v_images/20191107223835440_1436.png)]](https://img-blog.csdnimg.cn/20191110164809199.png)
下图是原CP值(X轴)与进化后的CP值图示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PhL1Oacz-1573375434150)(_v_images/20191110143939638_27082.png)]](https://img-blog.csdnimg.cn/20191110164829396.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
画图代码如下:
import matplotlib.pyplot as plt
def draw():
cp = [338., 333., 328., 207., 226., 25., 179., 70., 208., 606.]
y = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
plt.annotate("$(x_{cp}^n,\hat{y}^n)$", xy = (cp[4], y[4]), xytext = (250, 150), arrowprops = dict(facecolor = 'black', shrink = 0.1))
plt.xlabel("Original CP")
plt.ylabel("CP after evoluation")
plt.plot(cp,y,'bo')
plt.show()
if __name__ == '__main__':
draw()
有了这些数据以后,我们就可以衡量一个函数的好坏程度。
要衡量一个函数的好坏,我们需要另一个函数——损失函数。
它的输入是函数,输出是该函数有多差。损失函数可以定义如下:
我们有10只神奇宝贝,我们都知道它们进化后的CP值。把进化前的CP值输入到我们的函数中,看该函数输出的进化后的CP值与实际进化后的CP值相差有多大(相差越大说明越不准确,所以说损失函数的输出时函数有多差)。
是我们函数预测出来的结果, 是真正的结果,n为第n个数据
因为 是由 决定的,因此上面的损失函数可以转换为
下面画出这个损失函数的图形:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tC7WGPaN-1573375434151)(_v_images/20191110143208643_19921.png)]](https://img-blog.csdnimg.cn/20191110164842814.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
上图中的每个点都代表一个函数,颜色代表损失值,红色表示非常大,蓝色代表较小。
橙色X点表示损失值最小的函数的点。画图代码如下:
import matplotlib.pyplot as plt
import numpy as np
def calculate():
# data = np.loadtxt("pokemon.csv", delimiter=",", skiprows=1) #跳过第一行
# x_data = data[:,0]
# y_data = data[:,1]
x_data = [338, 333, 328, 207, 226, 25, 179, 60, 208, 606]
y_data = [640, 633, 619, 393, 428, 27, 193, 66, 226, 1591]
# y_data = b + w * x_data
# 通过穷举法
x = np.arange(-200,-100,1) # bias 100个数 -200到-100(不包括)的数组,步长为1,就是-200,-199,...,-101
y = np.arange(-5,5,0.1) #weight 100个数
Z = np.zeros((len(x),len(y))) #len(x)行 len(y)列的零矩阵
minx,miny = 0,0
minLoss = 100000000 # 初始设个较大的值
for i in range(len(x)):
for j in range(len(y)):
b,w = x[i],y[j]
Z[j][i] = 0
for n in range(len(x_data)): #对len(x_data)个数据计算损失值
Z[j][i] = Z[j][i] + (y_data[n] - b - w*x_data[n])**2 #(实际的y - 预测的y)^2
Z[j][i] = Z[j][i]/len(x_data) #共有len(x_data)个,求个均值
if Z[j][i] < minLoss:
minLoss = Z[j][i]
minx, miny = i, j
plt.contourf(x,y,Z,50,alpha=0.5,cmap=plt.get_cmap('jet'))#画三维等高线,并对区域进行填充
plt.plot([x[minx]],[y[miny]],'x',ms=12,markeredgewidth=3,color='orange') #标记处损失函数值最小的参数位置
plt.xlim(-200,-100)
plt.ylim(-5,5)
plt.xlabel(r'$b$',fontsize=16)
plt.ylabel(r'$w$',fontsize=16)
plt.show()
if __name__ == '__main__':
calculate()
接着我们画出我们的预测函数:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cBVrXFMY-1573375434151)(_v_images/20191110150002103_4562.png)]](https://img-blog.csdnimg.cn/20191110164853209.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
画图代码:
import matplotlib.pyplot as plt
import numpy as np
def draw():
cp = [338, 333, 328, 207, 226, 25, 179, 60, 208, 606]
y = [640, 633, 619, 393, 428, 27, 193, 66, 226, 1591]
#plt.annotate("$(x_{cp}^n,\hat{y}^n)$", xy = (cp[4], y[4]), xytext = (250, 150), arrowprops = dict(facecolor = 'black', shrink = 0.1))
plt.xlabel("Original CP")
plt.ylabel("CP after evoluation")
plt.plot(cp,y,'bo')
pre_y = -196 + 2.699 * np.array(cp)
plt.plot(cp, pre_y, 'r-')
plt.show()
if __name__ == '__main__':
draw()
可以看到,还是比较好的画出了这个趋势。
因为这只有两个参数,所以我们可以穷举出来,并且可以看到效率不高,那么如何通过更加一般的方法找到最好的函数呢。继续往下看。
找到最好的函数
定义好了损失函数后,接下来就要通过这个损失函数来找到最好的预测函数。
我们要找一个函数f,使得损失函数的值最小。我们知道f由w,b决定,也就是找到
使得
也就是要解
如何解呢?通过**梯度下降(Gradient Descent)**算法。
梯度下降
考虑有一个参数 的损失函数 : ,找到最小的损失函数的 。
因为只有一个参数 ,我们把 与 的关系画出来:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8nPx7Kl0-1573375434151)(_v_images/20191109103020915_4124.png =704x)]](https://img-blog.csdnimg.cn/20191110164905736.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
我们可以看图知道 的最低点在哪。那梯度下降算法该怎么做呢?
梯度下降算法过程:
- 随机选一个初始值 ,如下图
- 计算
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kt3U1cFg-1573375434152)(_v_images/20190902225637579_22869.png)]](https://img-blog.csdnimg.cn/20191110164918707.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
即找曲线在 点处切线的斜率。若该点的斜率为负数,表示函数值在递减,因此需要向右(将参数 的值增加)找到更小的值;反之,若斜率为负数,需要减小 的值。
上述文字如果通过公式来描述如下所示:
初始是 ,把微分的结果乘上一个负数与常数 ,再与 相加就得到更新后的 。
如上所说,微分的结果如果是负的(应该往右),那么乘以负号刚好为正, 增加,反之亦然。
其中 是learning rate,可以理解为移动的步长。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5R9NhmXq-1573375434153)(_v_images/20190902230603758_914.png)]](https://img-blog.csdnimg.cn/20191110164928499.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
3. 再计算
处的微分
来决定往左移还是往右移,然后就得到了
:
不断的重复第3步,直到得到微分是0的 。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kj8hZ1du-1573375434153)(_v_images/20190902230828770_9959.png)]](https://img-blog.csdnimg.cn/20191110164937454.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
但是从上面的图就可以发现,很有可能停在极小值(局部最小值),而不是最小值点。梯度下降算法并不能保证能找到最小值点。
上面只分析了一个参数,那如果有两个参数呢?
其实步骤也差不多:
- 随机选初始值
- 分别计算对 和 的偏微分:
同理得到
,
上面的公式写起来有点复杂,我们可以把 和 对 的偏微分写成一个矩阵,记为 :
接下来通过图示来分析下梯度下降的过程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0yzSefUk-1573375434153)(_v_images/20190903223357464_10911.png)]](https://img-blog.csdnimg.cn/20191110164953143.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
颜色代表损失函数的数值,以左下角的红点为初始值,在该位置计算
和
对
的偏微分,然后再乘上
,得到一个向量
。
该向量指向的方向就是等高线的法线方向(损失函数值减少的方向)。
再多次计算偏微分,更新参数 。上面只是介绍了两个参数的情况,如果有多个参数方法也是一样的。
现在有个问题,我们用 表示参数的集合
每次我们更新参数,都会得到一个新的
使得
的值更小?也就是下式一定成立?
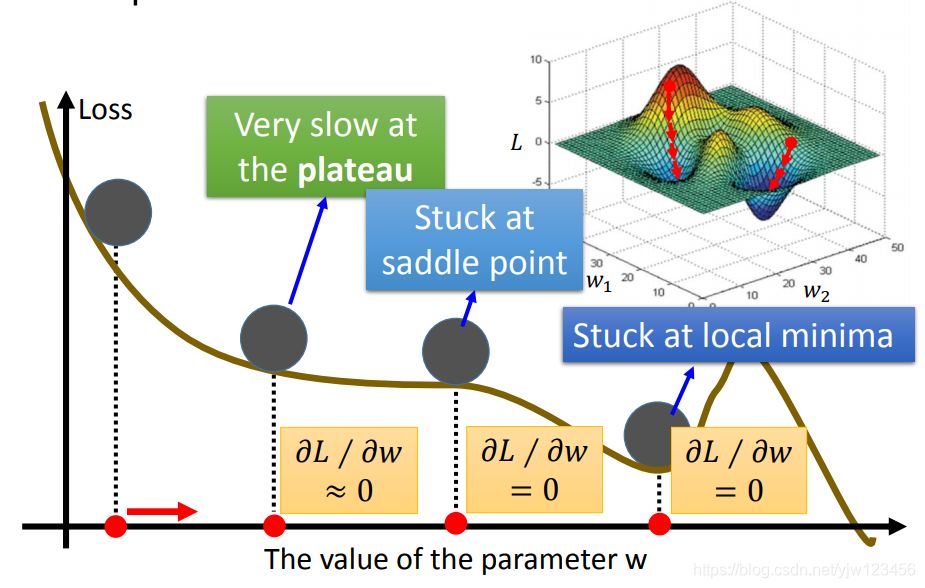
我们知道,走到了最小值点时,微分值为0,因此参数就不再更新。但是微分值是0的点,不一定是极值点。
存在鞍点(saddle point) 微分为0,但是不是极值。
不过实际情况是,很难算出微分值刚好为0的点,常见的做法是找到一个微分值足够小的点,就不再计算下去了。
但是又会存在另一个问题,有可能微分值很小的点,它离极小值点还很远,比如上图的plateau点。
在做线性回归时,不太需要担心上面的问题,如上图右上角所示,它的图形通常是一个碗的形式,一般都能找到局部或全局最小点。
接下来想一下如何计算对 和 对 的偏微分?(复合函数的求导法则)
代码实现
def gradient_descent():
x_data = [338, 333, 328, 207, 226, 25, 179, 60, 208, 606]
y_data = [640, 633, 619, 393, 428, 27, 193, 66, 226, 1591]
b = -120
w = -4
lr = 0.0000001 #learning rate
iteration = 10000 #迭代次数
for i in range(iteration):
b_grad = 0.0
w_grad = 0.0
for n in range(len(x_data)):
w_grad = w_grad - 2.0 * (y_data[n] - (b + w * x_data[n])) * x_data[n]
b_grad = b_grad - 2.0 * (y_data[n] - (b + w * x_data[n])) * 1.0
b = b - lr * b_grad
w = w - lr * w_grad
print(b,w)
我们把得出的参数代入到画图代码,得出的图形如下:

同时求出损失值为:86.371
画图代码为:
import matplotlib.pyplot as plt
import numpy as np
def draw(b,w):
cp = [338, 333, 328, 207, 226, 25, 179, 60, 208, 606]
y = [640, 633, 619, 393, 428, 27, 193, 66, 226, 1591]
#data = np.loadtxt("pokemon.csv", delimiter=",", skiprows=1) #跳过第一行
#cp = data[:,0]
#y = data[:,1]
#plt.annotate("$(x_{cp}^n,\hat{y}^n)$", xy = (cp[4], y[4]), xytext = (250, 150), arrowprops = dict(facecolor = 'black', shrink = 0.1))
plt.xlabel("Original CP")
plt.ylabel("CP after evoluation")
plt.plot(cp,y,'bo')
pre_y = b + w * np.array(cp)
plt.plot(cp, pre_y, 'r-')
error = 0
for i in range(len(cp)):
error = error + (abs(y[i] - (b + w * cp[i])))
error = error / 10
print(error)
plt.show()
if __name__ == '__main__':
draw(-120.362,2.474)
如何评判结果

以之前通过暴力方法得到的预测函数为例,error就是真实值与实际值的差距。
我们把每个数据的error加起来求平均得到:
cp = [338, 333, 328, 207, 226, 25, 179, 60, 208, 606]
y = [640, 633, 619, 393, 428, 27, 193, 66, 226, 1591]
error = 0
for i in range(len(cp)):
error = error + (abs(y[i] - (-120.362 + 2.474 * cp[i])))
error = error / 10
print(error)
输出为:86.371(没错确实是这么多,我把视频中的参数带进去结果比这个还差一点点)
但是我们真正在意的是这个预测函数对我们从来没见过的宝可梦的预测能力,因此我们需要再抓10只宝可梦。
并且计算新的10只宝可梦的预测值与实际值的差值:
import matplotlib.pyplot as plt
import numpy as np
def draw():
cp = [338, 333, 328, 207, 226, 25, 179, 60, 208, 606]
y = [640, 633, 619, 393, 428, 27, 193, 66, 226, 1591]
data = np.loadtxt("pokemon.csv", delimiter=",", skiprows=1) #跳过第一行
cp = data[:,0]
y = data[:,1]
#plt.annotate("$(x_{cp}^n,\hat{y}^n)$", xy = (cp[4], y[4]), xytext = (250, 150), arrowprops = dict(facecolor = 'black', shrink = 0.1))
plt.xlabel("Original CP")
plt.ylabel("CP after evoluation")
plt.plot(cp,y,'bo')
pre_y = -120.362 + 2.474 * np.array(cp)
plt.plot(cp, pre_y, 'r-')
error = 0
for i in range(len(cp)):
error = error + (abs(y[i] - (-196 + 2.699 * cp[i])))
error = error / 10
print(error)
plt.show()
if __name__ == '__main__':
draw()
其中pokemon.csv(我随便取了连续的10只新的宝可梦数据):
cp,cp_new
384,694
366,669
353,659
338,640
242,457
129,243
10,15
25,47
24,47
161,305
得出的结果为:83.832,图像为:
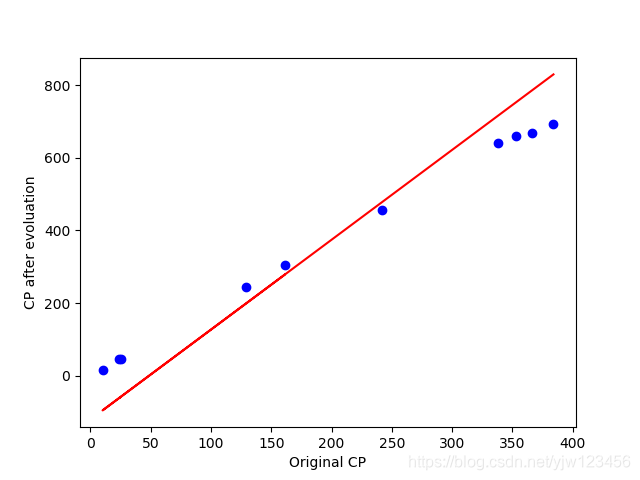
算出来的结果比训练数据的结果还要好一点!!(这有点不合理啊)。
那么是否还能做得更好,可能CP值与进化后的CP值不是一个一次线性关系,而是二次关系:

可以看到,二次曲线更加合适。继续尝试三次曲线,四次曲线:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LP5uUmdk-1573375434155)(_v_images/20191110154336020_2206.png)]](https://img-blog.csdnimg.cn/20191110165127854.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lqdzEyMzQ1Ng==,size_16,color_FFFFFF,t_70)
结果模型更复杂了,在训练数据上确实效果更好,但是在测试数据上结果反而更差。这种现象称为过拟合。
过拟合:在训练数据集上表示很好,但是在测试数据集上不理想称为过拟合。如何避免呢?增大训练数据集。
要解决过拟合问题可以收集更多的数据。
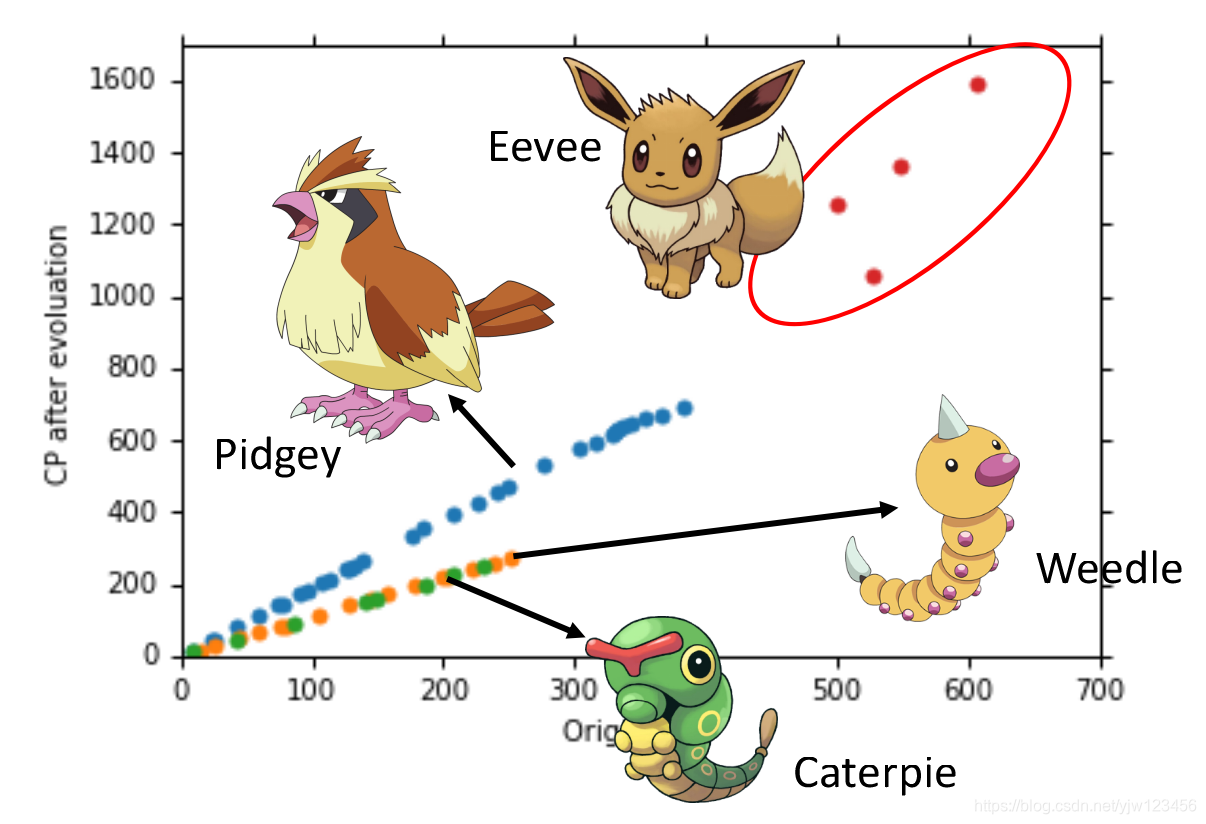
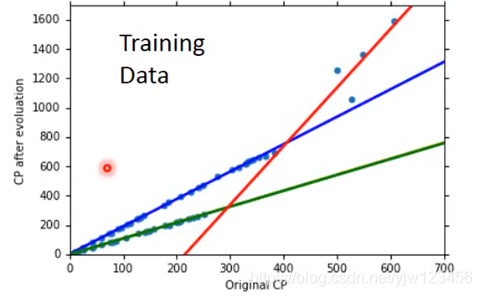
当我们找到更多的数据后,可以发现,似乎还有什么因素影响了进化后的CP值,观察数据可知,是宝可梦的种类。比如蓝色点种类都属于Pidgey。
因此重新回到第一步,重新设计下模型:
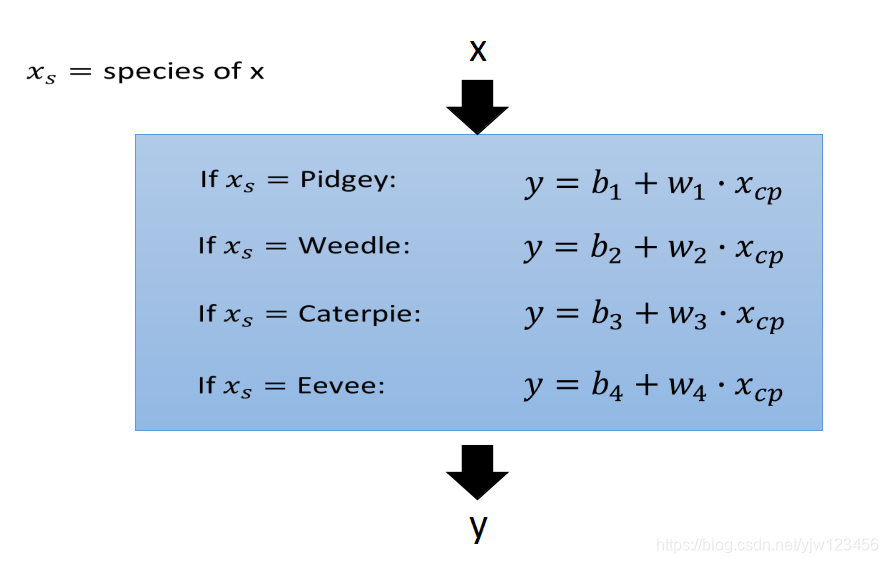
也就是根据不同的种类,分别计算不同的参数值。
最后会得到四条直线(其中有两条几乎重叠了)。
正则化
上面说了在训练数据上得到损失最小的函数就是最好的函数。这个叙述可能没有那么精确,因为可能会导致过拟合。
因此,我们要换一个损失函数。
原来的损失函数为:
原来的损失函数只是预测损失有多大,现在新的损失函数还增加了一项:
这样找到的函数不仅可以是损失较小,同时还需要使得
也很小,也就意味着这个函数比较平滑。
因为我们相信大多数情况下,与抖动很大的函数比,平滑的函数更可能是正确的。
其中 可以用来控制平滑程度,值越大越平滑。
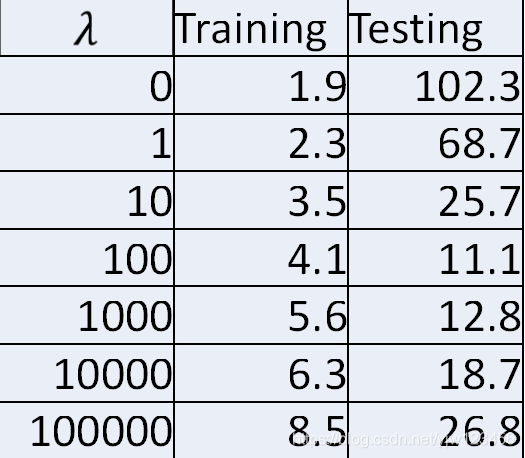
假设
与训练数据集以及测试集的损失值的关系如上图。由上图可知,取100时较好。
任何事情都是过犹不及,我们需要平滑的函数,但也不能太过平滑。
