Cascaded Feature Network for Semantic Segmentation of RGB-D Images
目前的问题:
1.为了计算对象/场景关系的表示,最近大量的分割网络使用一组感受野来丰富卷积特征的文本信息。这些感受野通常是预先定义的,具有不同大小的有规则形式。然而,这种规则的接受域是与上下文无关的,因为它们不考虑它们相对于非真实图像结构的范围。
2.具有多个分支的全卷积网络(FCN)被用来为不同的兴趣区域生成不同的特征,这些特征适用于不同的场景分辨率。特别地,FCN有独立的分支,可以用不同的场景分辨率来分割区域。虽然不同的分支通过共享的特征进行连接,但是每个独立的分支只影响场景分辨率区域内的共享卷积特征。这意味着在训练阶段,共享的卷积特征不能通过捕获不同场景分辨率区域之间关系的信号进行更新。它不可避免地限制了那些确实能够有效更新网络的区域的上下文信息。
简述:
在这篇论文中,在RGB-D图像分割的背景下解决了上述两个问题。
1.为了使特征更集中于被观察场景的共同视觉特征,我们引入了一个上下文感受野 (CaRF)。CaRF可以更好地控制所学习特性的相关上下文信息,我们的CaRF是基于超级像素计算的,由底层场景结构定义。因此,CaRF提供的上下文信息可以缓解过度小区域或过大区域特征混合的负面影响。
2.我们提出了一个具有并行分支的级联特征网络(CFN)。每个分支都配有一个CaRF。它是在一个更集中的背景下训练和操作的,具有类似的场景分辨率。CaRF和级联网络的结合,使得不同场景分辨率下的区域能够相互通信,从而明智地更新共享的卷积特性。
模型:
1.Context-aware Receptive Field (CaRF)

(a)图像被分割成不同大小的超像素;(b)在粗网格的每个节点上,我们将在同一超像素上的特征聚合起来;©聚合相邻超级像素的内容;(d)feature map中的聚合内容表示一个CaRF。对不同尺寸的超像素分割图像重复使用二级CaRF。注意,由于网络向下采样,feature map的分辨率比图像小。
由b到c的过程中,式1:其中h,w为一个通道的长款,c为通道数。
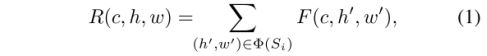
由c到d的过程中,将与相邻的超像素相关的R的特征集合起来,建立新的feature map M,式2:
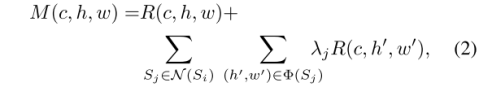
2.cascaded feature network (CFN).
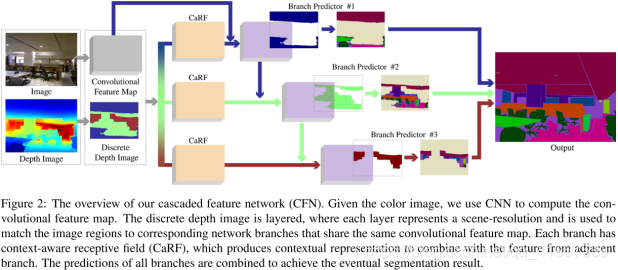
级联特征网络(CFN):对于给定的彩色图像,我们使用CNN得到feature map。将离散深度图像分层,每一层代表一个场景分辨率,用于将图像区域匹配到共享相同卷积特征映射的对应网络分支。每个分支都有上下文感知的接受域(CaRF),它产生上下文表示来与相邻分支的特征相结合。将各分支的预测结果结合起来,得到最终的分割结果。
在CFN中,第一个分支用于最高场景分辨率,每一分支的输入是上一个分支的输出与此分支的CaRF的输出相加得到:如式3,其中F代表分支,M代表CaRF输出。
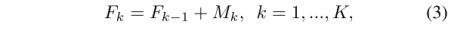
将特征Fk输入预测器进行分割。给定分配给第k个分支的所有像素,我们将它们的类标签表示为一个集合yk。见式4:
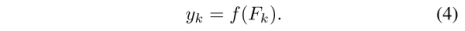
3.Network Training
CFN网络的目标函数是
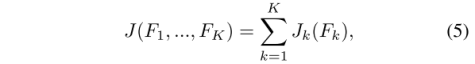
Jk是第k个分支的目标函数,函数L为惩罚像素级分类错误的softmax loss,网络训练是通过最小化式(5)所表示的目标来完成的。
实验:
1,分支数越多,mean IOU不一定越好,分支数为3最好:

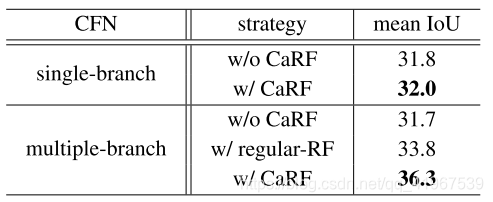
2,有CaRF模块比没有CaRF模块效果好(其中,multiple-branch分支数为3):
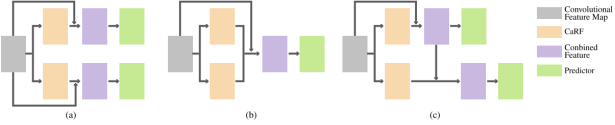
3,不同的branch融合方法的效果不同,其中,separate branches (a), combined branches (b) or cascaded branches ©:可以看到CFN(cascaded branches)效果最好:

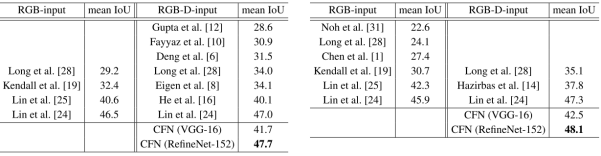
4,不同方法及本实验采用不同backbone的实验结果比较,可以看出CFN(RefineNet-152)效果最好:
5,真实图片比较,图片取自NYUDv2 和 SUN-RGBD数据集:

