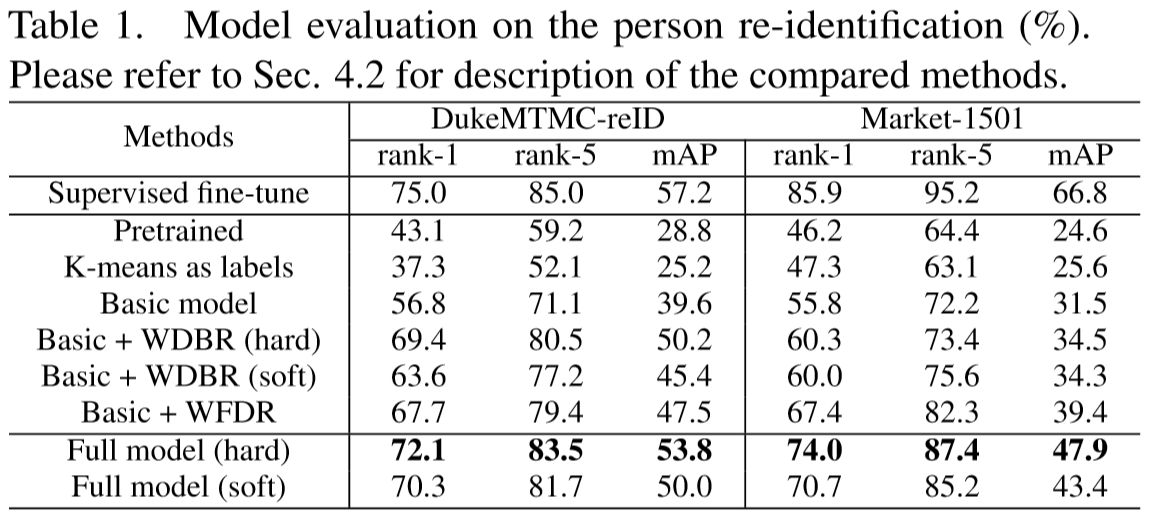
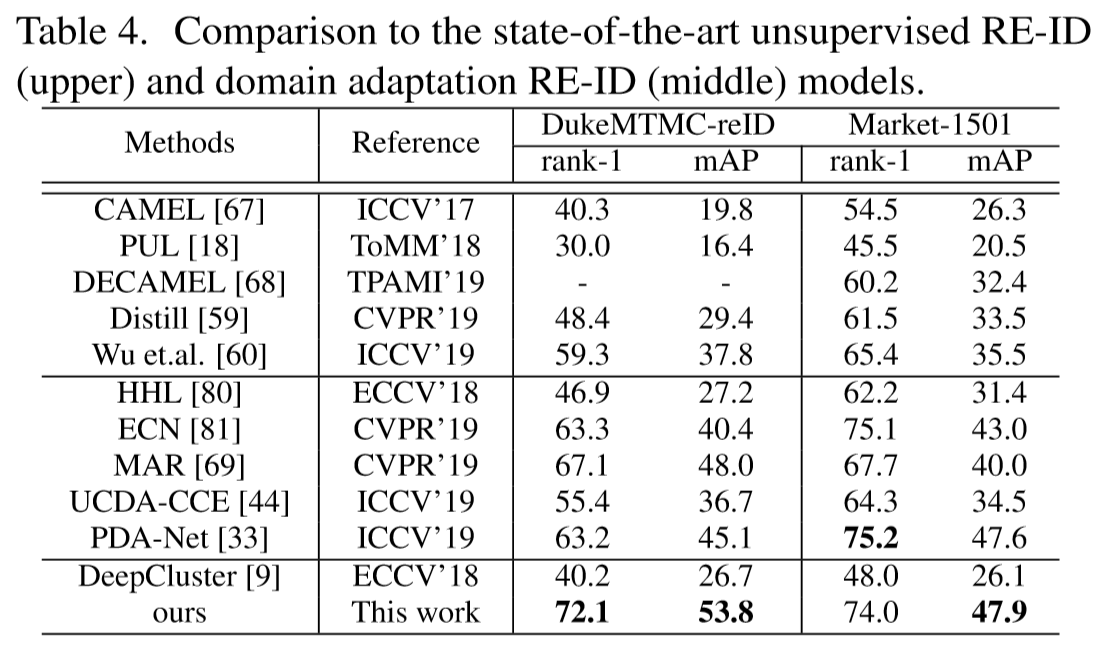
Introduction
每个行人图片都会有视角、姿态等状态信息,虽然自身不带标签,但可以预测这些状态信息作为伪标签,如下图:

由于无监督学习通常存在结果出错的问题,一些未标签的样本会偏离正确的决策边界,为此作者提出了弱监督决策边界修正(weakly supervised decision boundary rectification)来解决这个问题,由此每个样本获得了一个伪类,作为状态信息。
当特征失真严重时,样本会偏移到不正确的决策区域,但每个状态都有着特定的失真模式,会使得样本产生特定的偏移,对此作者提出了弱监督特征漂移正则化(weakly supervised feature drift regularization)。
方法概览如下:
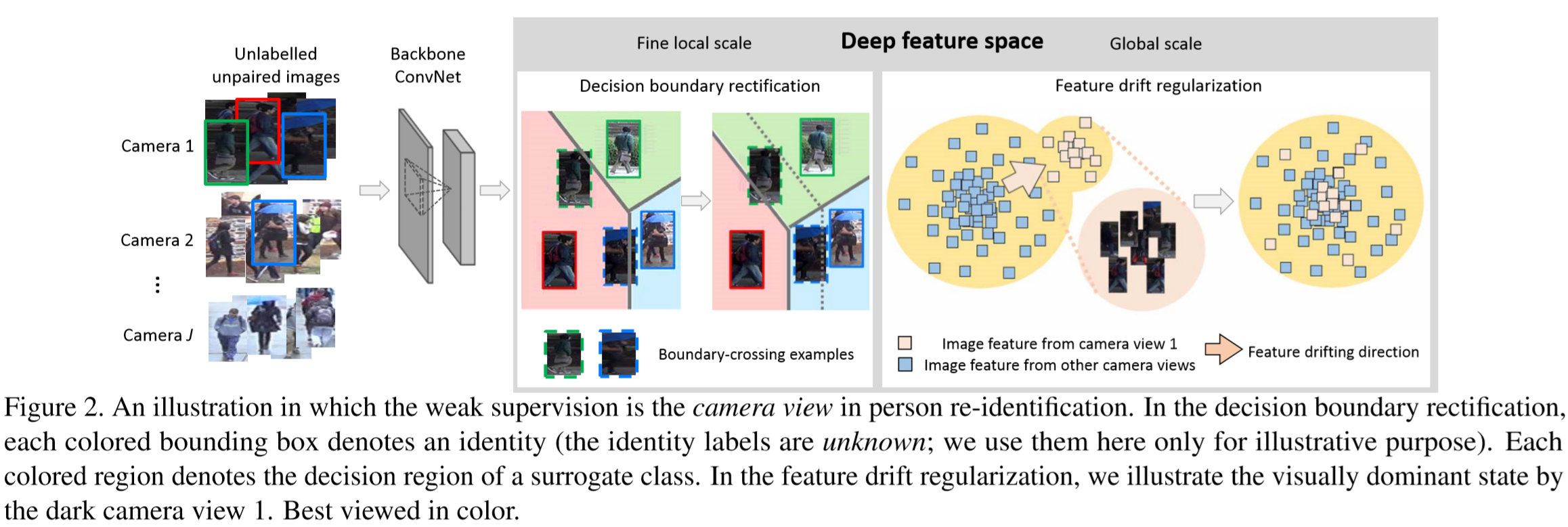
带有状态信息的弱监督判别特征学习
定义无标签的训练为:![]() ,定义状态为:
,定义状态为:![]() ,例如用于表述 ui 是黑暗、一般、明亮。目标是学习一个网络 f 来提取行人的判别特征,即
,例如用于表述 ui 是黑暗、一般、明亮。目标是学习一个网络 f 来提取行人的判别特征,即![]() 。每个特征特征向量 x 都属于一个代理类(surrogate class)μ,每个代理类都预测为未标签数据中的一个潜在的行人身份,判别学习问题定义为:
。每个特征特征向量 x 都属于一个代理类(surrogate class)μ,每个代理类都预测为未标签数据中的一个潜在的行人身份,判别学习问题定义为:
![]()
其中 K 表示代理类的数量,![]() 表示 x 的代理类的标签,即:
表示 x 的代理类的标签,即:![]()
(![]() 是动态更新的量)
是动态更新的量)
推导:
x 为第 y 类的概率值为:

设置:![]() ,
,![]()
![]() ,
,
则![]()
概率值更新为:
![]()
(1)弱监督决策边界修正(Weakly supervised decision boundary rectification,WDBR)):
量化一个代理类被状态支配的程度,称为 Maximum Predominance Index(MPI),表示为在代理类中最常见状态的比例。第 k 个代理类的MPI定义为:
![]()
其中![]() ,
,![]() ,则分母表示为该代理类的元素数量,分子表示为代理类中最常见状态的元素数量,
,则分母表示为该代理类的元素数量,分子表示为代理类中最常见状态的元素数量,![]() 会动态更新。
会动态更新。
Rk 越高,表明一些样本错误的进入了代理类![]() 中(直观理解,每个代理类,即每个行人被不同监控拍摄下来,所包含的状态分布相对均匀)。由此得到弱监督的修正分配为:
中(直观理解,每个代理类,即每个行人被不同监控拍摄下来,所包含的状态分布相对均匀)。由此得到弱监督的修正分配为:
![]()
其中 p(k) 为修正函数,用于抑制 Rk 较高的代理类,具体为:
![]()
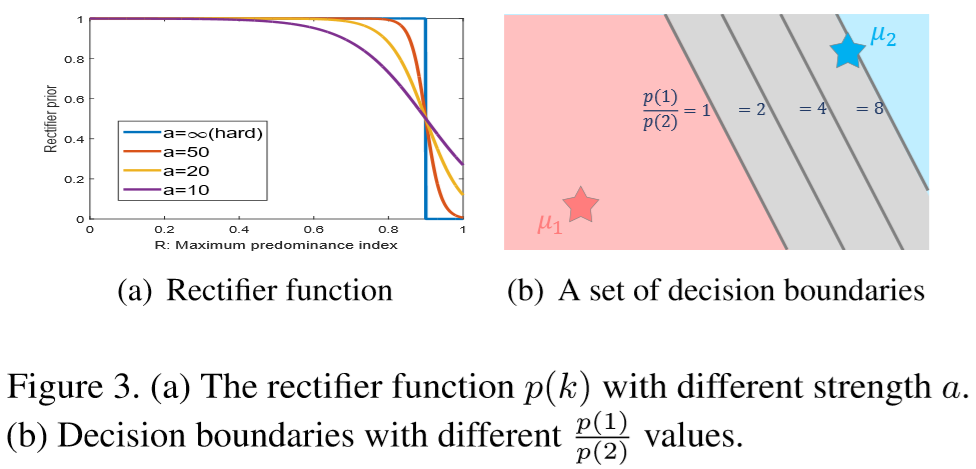
上述称为 soft rectifier 函数,若 b = 0.95, a = 无穷,可以简化得到 hard rectifier 函数:
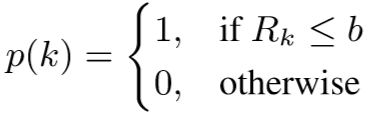
对于 hard rectifier 函数,当超过阈值时,比如这部分决策区域超过95%的样本都是黑暗的,那么说明这部分过于黑无法匹配出行人,则取消这片决策区域;
对于 soft rectifier 函数,当超过阈值时,决策区域不会无效,而是对决策边界进行调整。
二分类的决策边界推导:
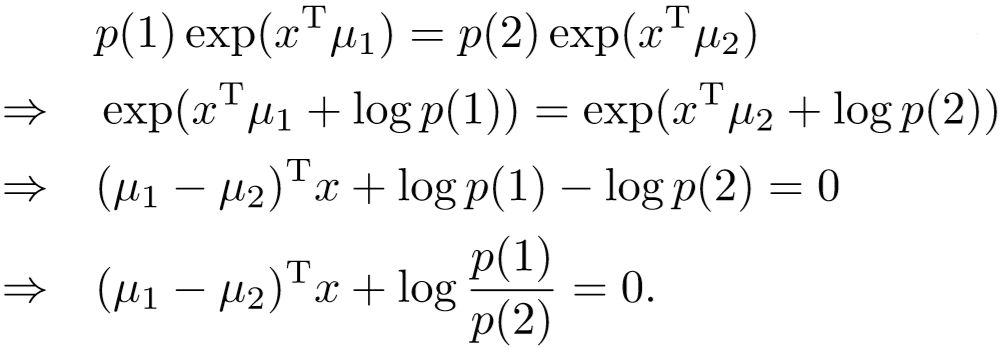
(2)弱监督特征漂移正则化(Weakly supervised feature drift regularization,WFDR):
视觉的主导状态会导致显著的特征失真,但其遵循着特定的失真模式,比如低分率状态下颜色暗淡、纹理模糊等。定义状态子分布(state sub-distribution)为![]() ,所有未标签的训练集的分布为
,所有未标签的训练集的分布为![]() ,其中
,其中![]() ,特征失真会导致
,特征失真会导致![]() 远离
远离![]() ,作者提出校准子分布和总分布,来对抗特征的漂移,即 WFDR:
,作者提出校准子分布和总分布,来对抗特征的漂移,即 WFDR:
![]()
其中 d 为Wasserstein距离,衡量两个分布之间的距离【传送门】,为了计算的方便,对距离计算进行简化:
![]()
其中 ![]() 分别为
分别为![]() 中特征向量的均值和方差,
中特征向量的均值和方差,![]() 分别为
分别为![]() 中特征向量的均值和方差。
中特征向量的均值和方差。
(3)结合两方面的考虑,得到总损失函![]()
主干网络采用ResNet-50,训练迭代次数为1600次,batchsize = 384,momentum = 0.9,weight decay = 0.005,采用梯度下降法,学习率为0.001,并在1000、1400次迭代后下降至0.1倍,
Experiments
将模型应用到两个领域进行测试:行人重识别和姿态鲁棒人脸识别(只看了行人重识别):