You Only Look Once:Unified, Real-Time Object Detection
Homepage: https://pjreddie.com/darknet/yolo/
Abstract
Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation.
Compared to state-of-the-art detection systems, YOLO makes more localization errors but is less likely to predict false positives on background.

Introduction
A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes. YOLO trains on full images and directly optimizes detection performance. This unified model has several benefits over traditional methods of object detection.
1) YOLO is extremely fast. Since we frame detection as a regression problem we don't need a complex pipeline. We simply run our neural network on a new image at test time to predict detections. Our base network runs at 45 frames per second with no batch processing on a Titan X GPU and a fast version runs at more than 150 fps. YOLO achieves more than twice the mean average precision of other real-time systems.
2) YOLO reasons globally about the image when making predictions. YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance. YOLO makes less than half the number of background errors compared to Fast R-CNN.
3) YOLO learns generalizable representations of objects. When trained on natural images and tested on artwork, YOLO outperforms top detection methods like DPM and R-CNN by a wide margin. Since YOLO is highly generalizable it is less likely to break down when applied to new domains or unexpected inputs.
但是YOLO在accuracy上仍然落后于state-of-the-art的检测系统,但是它可以快速并努力更准确的定位图像中的物体,特别是较小的物体。
Unified Detection
Our network uses features from the entire image to predict each bounding box. It also predicts all bounding boxes across all classes for an image simultaneously.
此系统将输入图像resize到S x S的grid。如果一个object的中心落在一个grid中,那么这个grid理所当然要detect这个object。
每一个grid预测B个bounding boxes和对应的confidence scores。这些confidence scores反应了模型对box包含object和它预测的box的精度的confidence。Confidence可以表示为:
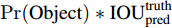
如果Cell里面没有object,我们希望confidence score为0,否则我们希望confidence score等于预测的box和ground truth之间IOU的交集。
每个bounding box有5个预测:x, y, w, h, confidence。其中(x, y)代表与grid cell边界相关的box的中心坐标。(w, h)即预测的宽度与高度与整副图像相关。预测的confidence代表了预测框box与ground truth box之间的IOU。
注意(x, y)的预测,论文中这么说的:
Our final layer predicts both class probabilities and bounding box coordinates. We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1. We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1.
当时没搞懂这句话的意思,直到看到YOLO9000文章中的这一句:
Instead of predicting offsets we follow the approach of YOLO and predict location coordinates relative to the location of the grid cell
即(x, y)预测的其实是相对于每一个grid cell位置的偏移量。
每个grid也会预测C个有条件的class概率:
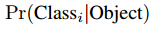
这些概率取决于包含object的grid cell。每个grid cell只预测一套class概率,而不管boxes B的数量。
综上,yolo的输出维度应该是: output_size = (cell_size * cell_size) * (num_class + boxes_per_cell * 5)。即每个grid cell有num_class + boxes_per_cell * 5个预测。
At test time we multiply the conditional class probabilities and the individual box confidence predictions,

which gives us class-specific confidence scores for each box. These scores encode both the probability of that class appearing in the box and how well the predicted box fits the object.
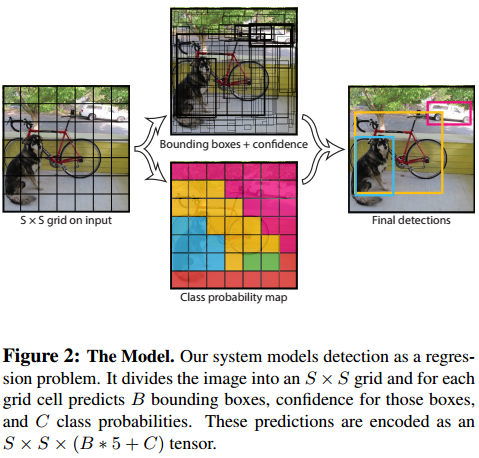
For evaluating YOLO on PASCAL VOC, we use S = 7, B = 2. PASCAL VOC has 20 labelled classes so C = 20. Our final prediction is a 7 × 7 × 30 tensor.
两种网络结构设计
1. YOLO的网络结构设计
此网络基于卷积网络,前面的卷积层用来extract features,后面的全连接层用来预测输出概率和坐标。并使用了1x1的reduction layers在3x3的卷积层前面。该网络共有24层卷积层,2层全连接层。完整网络见Figure 3.

2. Fast YOLO
具有更少的卷积层(9层),且在这些层中具有更少的filter。除了这些,其他包括train和testing paramerters都与YOLO相同。
网络的最终输出都是7x7x30的tensor的预测。
训练
关于网络
卷积层在有1000-class的ImageNet上预训练。预训练的时候使用Figure 3中所示网络的前20层卷积层,后面接着一个average-pooling层,然后是一个全连接层。We achieve a single crop top-5 accuracy of 88% on the ImageNet 2012 validation set。所有的training和inference都使用Darknet。
注意了,作者预训练的时候只用了20个卷积层和一个全连接层,为啥??
因为后面说了,Ren等人在文献[29]中证明了在预训练的网络上添加卷积层和全连接层可以提高性能。所以作者在预训练的网络后面加了4个卷积层和两个全连接层,并且随机初始化了weights!
还有一点就是预训练的时候的input image的resolution是224x224,作者在应用自己的Detection网络时将input resolution从224x224增加到了448x448. 为啥??因为Detection often requires fine-grained visual information。
关于参数
将bounding box的width和height归一化到(0,1]之间,x和y作为特定grid cell的位置偏移量也在(0,1]之间。
最后一层使用线性激活函数,其他层后面使用leaky relu作为激活函数:
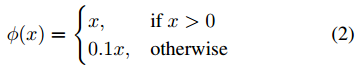
loss function:
此模型的损失函数如上式(3)所示。
问题来了,作者为啥不用sum-squared error?为啥??
因为:
it does not perfectly align with our goal of maximizing average precision. It weights localization error equally with classification error which may not be ideal. Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
怎么解决?
增加来自bounding box coordinate的loss,减少不包含object的boxes的confidence预测的loss。这两个操作是通过两个参数完成的:λcoord和λnoobj,并将它们设为:λcoord=5,λnoobj=5。
还有一点要注意,Sum-squared error also equally weights errors in large boxes and small boxes. Our error metric should reflect that small deviations in large boxes matter less than in small boxes. To partially address this we predict the square root of the bounding box width and height instead of the width and height directly。直接预测bounding box的宽度和高度的平方根,而不是宽度和高度。
Note that the loss function only penalizes classification error if an object is present in that grid cell (hence the conditional class probability discussed earlier). It also only penalizes bounding box coordinate error if that predictor is “responsible” for the ground truth box (i.e. has the highest IOU of any predictor in that grid cell)
超参数:
epochs: 135
batch size: 64
momentum: 0.9
decay: 0.0005
learning rate schedule is as follows:
For the first epochs we slowly raise the learning rate from 10-3 to 10-2. We continue training with 10-2 for 75 epochs, then 10-3 for 30 epochs, and finally 10-4 for 30 epochs.
学习率慢慢减小容易理解,但是为什么一开始的时候是先小后大?因为如果一开始学习率比较高,模型会因为梯度不稳定而偏移:If we start at a high learning rate our model often diverges due to unstable gradients.
防止过拟合的两个方法:
Dropout rate: 0.5. After the first connected layer prevents co-adaptation between layers [18].
data augmentation: 我们引入了随机缩放和最多20%原始图像大小的翻译。 我们还在HSV色彩空间中随机调整图像的曝光和饱和度,最高可达1:5.
Limitations of YOLO
很强的空间约束。每个grid cell只能预测两个bounding box,且只能有一个class。这种空间约束限制了模型预测靠的比较近的object的数量。当有一群小物体密集的时候模型很难正确预测bounding box。
因为结构中有不少downsampling layers,模型也会用较粗糙的features来预测bounding boxes。
loss function会将小bounding box和大bounding box的error同等对待。一个小的error对大的box影响不大,但是对小的box的IOU有较大的影响。
Experiments
我们可以看到,YOLO在保持较高的准确率的情况下还能有45帧的处理速度。
Conclusion
We introduce YOLO, a unified model for object detection. Our model is simple to construct and can be trained directly on full images. Unlike classifier-based approaches, YOLO is trained on a loss function that directly corresponds to detection performance and the entire model is trained jointly.
Fast YOLO is the fastest general-purpose object detector in the literature and YOLO pushes the state-of-the-art in real-time object detection. YOLO also generalizes well to new domains making it ideal for applications that rely on fast, robust object detection.