版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/asasasaababab/article/details/82314314
本周主要是讲了一个OCR的案例。主要内容是machine learning pipeline, text detection,character segmentation,data synthesis,以及ceiling analysis。
Machine Learning Pipeline
数据集比较多的时候,可能端到端训练更好,但是数据集比较少的时候,可能PipeLine更有效一些:
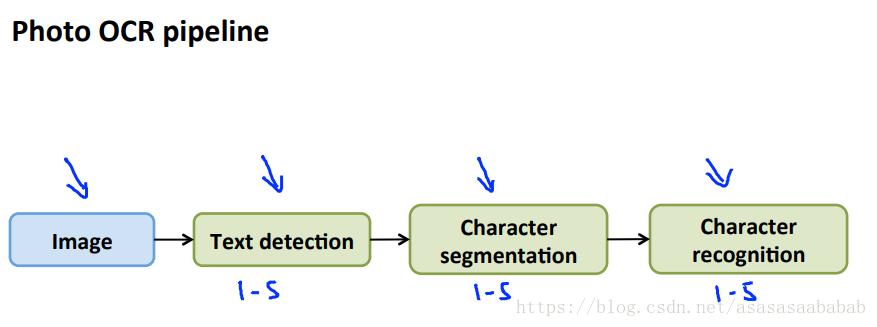
Text Detection
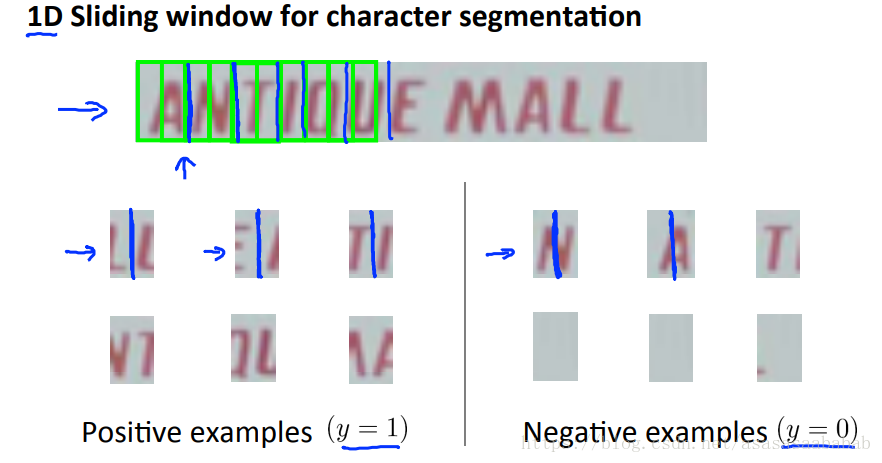
这块Dr. Ng用的是Sliding Window的方式,其实现在已经有很多Detection的网络了。当然,这门课是13年讲的吧,所以并不是那么更新的快。Deeplearing.ai已经用的是yolov2了。
Character Segementation
这块也是sliding window。应该也有一些检测网络能够检测了。其实目标检测就可以啊。
Data Synthesis
其实DeepLearing.ai里边也有讲,这里就是给一个案例:
比方说对于字符来说,我有了A,B的样本,其实我是可以知道是什么字体的。那么我就可以使用样本的背景,然后相同字体替换样本,扩充数据集。同时也可以增加一些畸变。

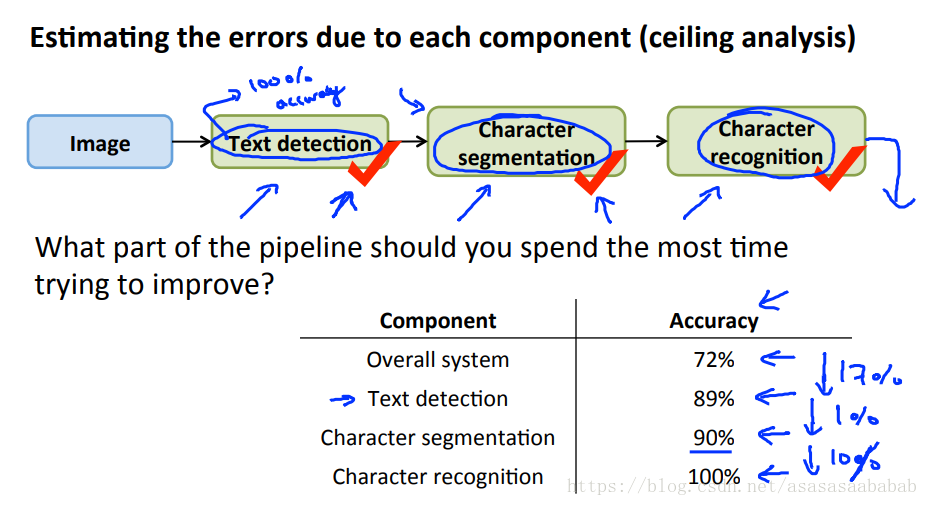
Ceiling Analysis
这个其实比较重要,尤其是对于PipeLine来讲。方法就是假如我有一个pipeline,ABCD。然后我的总体系统性能是70%。那么我可以依次把A先设定为完美,看系统性能,再在这个基础上把B设定为完美,看系统性能,以此类推,这样我就能知道到底那个系统最值得投入时间和资源进行改进,从而让整体系统最优。
Discussion on Getting More Data
有的时候我们可能高估了采数据的难度,所以我们应该仔细分析一下究竟想获得x10倍的数据,需要花多久。
