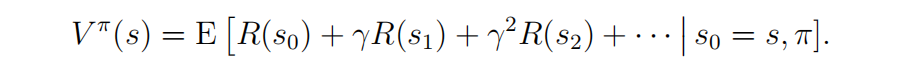强化学习定义
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
在强化学习框架中,我们将只提供我们的算法一个奖励函数,它指示学习代理何时做得好,当它做得不好。然后,学习算法的工作将是找出如何随时间选择行动,从而获得巨大的奖励。
强化学习系统一般包括四个要素:策略(policy),奖励(reward),价值(value)以及环境或者说是模型(model)。
策略
策略定义了智能体对于给定状态所做出的行为,换句话说,就是一个从状态到行为的映射,事实上状态包括了环境状态和智能体状态,这里我们是从智能体出发的,也就是指智能体所感知到的状态。因此我们可以知道策略是强化学习系统的核心,因为我们完全可以通过策略来确定每个状态下的行为。我们将策略的特点总结为以下三点:
- 策略定义智能体的行为
- 它是从状态到行为的映射
- 策略本身可以是具体的映射也可以是随机的分布
奖励(Reward)
奖励信号定义了强化学习问题的目标,在每个时间步骤内,环境向强化学习发出的标量值即为奖励,它能定义智能体表现好坏,类似人类感受到快乐或是痛苦。因此我们可以体会到奖励信号是影响策略的主要因素。我们将奖励的特点总结为以下三点:
- 奖励是一个标量的反馈信号
- 它能表征在某一步智能体的表现如何
- 智能体的任务就是使得一个时段内积累的总奖励值最大
价值(Value)
接下来说说价值,或者说价值函数,这是强化学习中非常重要的概念,与奖励的即时性不同,价值函数是对长期收益的衡量。我们常常会说“既要脚踏实地,也要仰望星空”,对价值函数的评估就是“仰望星空”,从一个长期的角度来评判当前行为的收益,而不仅仅盯着眼前的奖励。结合强化学习的目的,我们能很明确地体会到价值函数的重要性,事实上在很长的一段时间内,强化学习的研究就是集中在对价值的估计。我们将价值函数的特点总结为以下三点:
- 价值函数是对未来奖励的预测
- 它可以评估状态的好坏
- 价值函数的计算需要对状态之间的转移进行分析
环境(模型)
也叫外界环境,它是对环境的模拟,举个例子来理解,当给出了状态与行为后,有了模型我们就可以预测接下来的状态和对应的奖励。但我们要注意的一点是并非所有的强化学习系统都需要有一个模型,因此会有基于模型(Model-based)、不基于模型(Model-free)两种不同的方法,不基于模型的方法主要是通过对策略和价值函数分析进行学习。我们将模型的特点总结为以下两点:
- 模型可以预测环境下一步的表现
- 表现具体可由预测的状态和奖励来反映
https://blog.csdn.net/weixin_45560318/article/details/112981006
MDP过程 Markov decision processes
马尔可夫决策过程(MDPs)以安德烈马尔可夫的名字命名 ,针对一些决策的输出结果部分随机而又部分可控的情况,给决策者提供一个决策制定的数学建模框架。MDPs对通过动态规划和强化学习来求解的广泛的优化问题是非常有用的。
马尔可夫决策过程是一个元组(S、a、{Psa}、γ、R),其中:
- S是一组状态。(例如,在自主直升机飞行中,S可能是直升机所有可能的位置和方向的集合。)
- A是一组动作。(例如,可以推直升机控制杆的所有可能的方向集合。)
- Psa是状态转移的概率。对于每个状态的∈S和动作∈a,Psa是状态空间上的分布。简单地说,Psa给出了如果我们在状态s中采取行动a,我们将过渡到什么状态的分布。
- γ∈[0,1)被称为折扣因子。
- R:S×A7→R是奖励函数。(奖励有时也只写成状态S的函数,在这种情况下,我们将有R:S7→R)。
MDP的动态过程如下:我们在某些状态s0开始,然后选择在MDP中选择一些动作a0∈a。由于我们的选择,MDP的状态随机过渡到某个后继状态s1,根据s1∼Ps0a0绘制。然后,我们可以选择另一个动作a1。由于这个动作,状态再次转换,现在转换到一些s2∼Ps1a1。然后我们选择一个2,以此类推。。
我们可以这样表示这个过程:
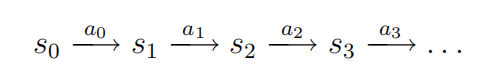
在访问状态序列s0,s1,…对于动作a0,a1,…,,我们的总收益为
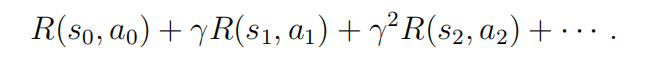
或者,当我们把奖励仅仅作为状态的函数来书写时,这就变成了
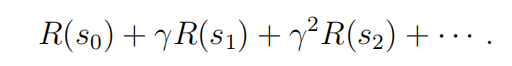
在我们的大部分开发中,我们将使用更简单的状态奖励R(s),尽管推广到状态动作奖励R(s,a)没有提供特殊的困难。
我们在强化学习中的目标是随着时间的推移而选择行动,以最大化总收益的期望值:
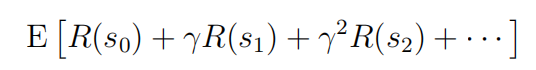
策略是任意函数π:S→A反映了从状态到所映射的动作。我们说,如果我们处于状态s时,我们采取=π(s),我们正在执行一些策略π。我们还定义了策略π的值函数