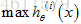第七章 Logistic回归(一种分类算法)
分类
之前的课程主要解决回归分析问题,这一次的课程主要为分类问题,分类问题也可看做将回归问题的连续性离散化。
先来谈谈二分类问题。课程中先给出了几个例子:

邮件是垃圾邮件还是非垃圾邮件;网上交易是的欺骗性(Yor N);肿瘤是恶性的还是良性的。
在所有的这类问题中,尝试预测的变量y都可以用0或1来表示,,0表示负类,1表示正类。

对于上述的数据集来说,使用线性回归的方法来拟合数据的结果显然不是一个好的方法,不建议将线性回归用于分类问题,如果对于分类问题使用线性回归,会出现以下的问题:对于分类,Y是0或1,如果使用线性回归,假设hθ(x)的输出值会远大于1或小于0,这样的结果会有些奇怪。于是,考虑造特殊函数使0=<hθ(x)<=1,也就是使用Logistic回归的方法。
假设陈述提出假设让估算值在0和1之间:
使用Logistic回归模型,想要使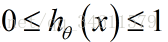
Logistic回归中假设函数的表示方法:
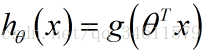
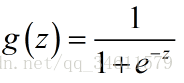
得出假设函数为:
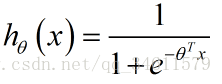
Logistic函数也就是Sigmoid函数的图像表示:

注意到z趋向于负无穷大时,值越接近0;z趋向于正无穷大时,值越接近1。这样就可以使输出值在0到1之间。有了这个假设函数,就可以拟合数据了,根据给定的θ参数值,假设会做出预测。
假设函数代表了一种概率含义:

通过这个公式就可以计算出一些相关的概率了。
决策界限
决策界限的概念能帮助更好地理解假设函数在计算什么,决策界限是假设函数的一个属性。
根据上述的假设函数,进行假设预测:

如果要决定是预测y=1还是y=0取决于估值概率是大于等于0.5还是小于0.5。
下面采用具体事例来体会一下边界的含义,假设有一个样本训练集如下所示:
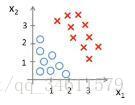
假设函数为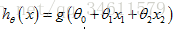
在直线的左边都预测y=0,在直线的右边都预测y=1。
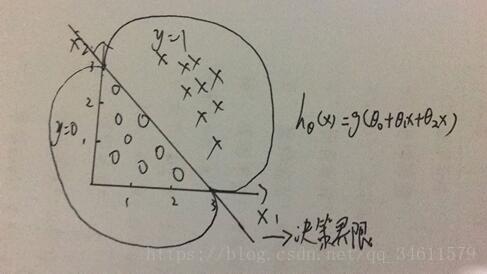
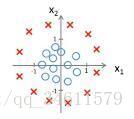
下面看另一个实例,有一个样本训练集如下:
假设函数为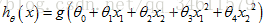
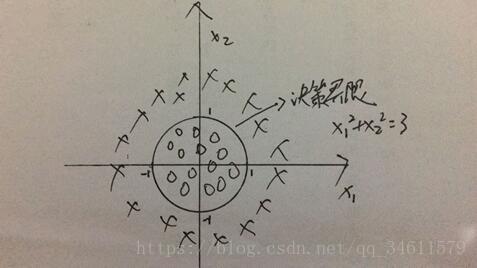
在圆的外面都预测y=1,在圆的里面都预测y=0。
总结:假设函数越复杂,也就是说特征数不断增加,将会得到更复杂的图像和决策界限。
代价函数
这一节中,主要讲解如何拟合Logistic回归模型的参数θ。
首先要定义代价函数:

假设函数:
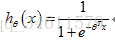
先来看看线性回归中的代价函数:
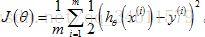
换一种方式改写一下,不写平方误差项,写成:

假如将上述的代价函数用到Logistic回归,会出现什么问题?
因为假设函数hθ(x)的非线性,代价函数会出现以下形状:
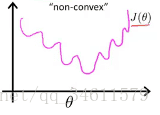
这是一个非凸函数,会出现多个局部最低点,也就是说,如果我们运用梯度下降法,不能保证算法收敛到全局最小值。
Logistic回归的代价函数:

如果y=1时绘制上述函数的图像:

如果y=0时绘制上述函数的图像:

总结:以上讨论的是单训练样本的代价函数。
简化代价函数与梯度下降
这一节中主要是找出简单一点的方法来写代价函数,同时要知道如何运用梯度下降算法来拟合出Logistic回归的参数。
逻辑回归的代价函数:
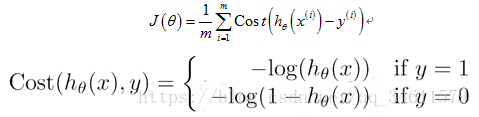
具体来说,为了避免把代价函数分成y=1或y=0两种情况来写,要用一种方法把这两个式子合并成一个等式:
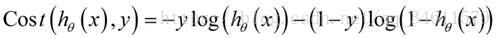
这样就得到了逻辑回归的代价函数如下:

根据梯度下降法,最小化代价函数的更新规则为:

这和线性回归的更新规则是一样的,但不同的是在线性回归中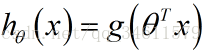
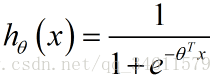
所以即使公式一样,但是两个假设的定义不一样,实际上是两种完全不同的东西。但是应用在线性回归中的特征缩放的方法也同样可以让逻辑回归中的梯度下降收敛更快。
高级优化
这一节中将会介绍一些高级优化的算法和概念,相比于梯度下降,这些方法能够大大提高逻辑回归的效率,也能使算法能够实现大规模的机器学习问题。
一些高级的优化算法:共轭梯度法、BFGS、L-BFGS。
它们的优点:
(1)通常不需要手动的选择学习率,它可以自动选择较好的学习率;
(2)它们的收敛速度远远快于梯度下降。
这些算法的主要缺点是比梯度下降法要复杂的多。
具体实例介绍如何使用这些算法:
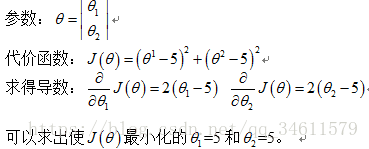
实现的过程如下:

调用高级优化算法:
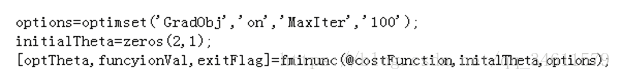
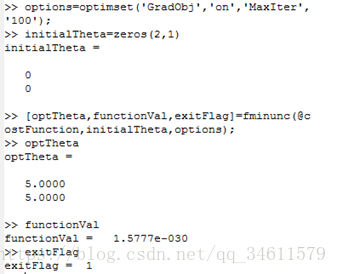
fminunc是Octave中无约束化的最小化函数,执行优化算法的结果如下所示:
这一节介绍如何用逻辑回归解决多类别分类问题。
什么叫做多元分类?
例如:将邮件分类在工作、朋友、家人、爱好等4个不同的文件夹中,这就是四元分类问题;一个病人鼻塞可能没有生病、可能感冒、可能得了流感,这就是三元分类问题;利用机器学习处理天气问题,有晴天、多云、雨天、雪天,这就是四元分类问题。
下面用图像的表示来看一看二元和多元分类的情况:
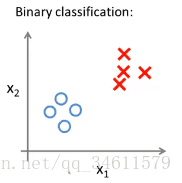
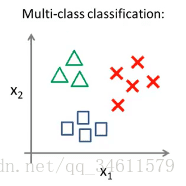
对二元的分类,可以在中间用直线分开;对三元的分类,同样也可以用类似的原理进行操作。
一对多的原理:对于上面的三元问题,可以将之转化为三个独立的二元分类问题,对于多分类,可以给每一类i拟合一个逻辑回归分类器,来预测y=i可能性,下图展示了这样的分类过程:

对于拟合分类器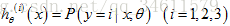
总结:给出一个新的输入值x,期望获得预测,选择分类器中可信度最高、效果最好的,最终预测值为