写在前面的话:每一个实例的代码都会附上相应的代码片或者图片,保证代码完整展示在博客中。最重要的是保证例程的完整性!!!方便自己也方便他人~欢迎大家交流讨论~
环境:Anaconda3(python3.5)
在上一节我们将爬取的数据存到了Excel中,这一节我们要把数据存入MongoDB中。
import requests
from lxml import etree
import pymongo
class doubanBookData(object):
def __init__(self):
self.mongo_client=pymongo.MongoClient('localhost',27017)#创建数据库链接
self.db=self.mongo_client['doubanBook'].text#打开test数据库
def getUrl(self):
for i in range(10):
#这一次以爬取两页为例
url = 'https://book.douban.com/top250?start={}'.format(i*2)
self.spiderPage(url)
def spiderPage(self,url):
if url is None:
return None
try:
proxies = {#使用代理IP
'http':'http://110.73.1.47:8123'}
user_agent='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
headers = {'User-Agent': user_agent}
respon=requests.get(url, headers=headers,proxies=proxies)#获得响应
htmlText=respon.text#打印html内容
s = etree.HTML(htmlText)#将源码转化为能被XPath匹配的格式
trs = s.xpath('//*[@id="content"]/div/div[1]/div/table/tr')#提取相同的前缀
for tr in trs:
bookHref=tr.xpath('./td[2]/div[1]/a/@href')
bookTitle=tr.xpath('./td[2]/div[1]/a/text()')
bookScore=tr.xpath('./td[2]/div[2]/span[2]/text()')
bookPeople=tr.xpath('./td[2]/div[2]/span[3]/text()')
bookHref = bookHref[0] if bookHref else ''
bookTitle = bookTitle[0] if bookTitle else ''
bookScore = bookScore[0] if bookScore else ''
bookPeople =bookPeople[0] if bookPeople else ''
#创建每条图书信息的字典
data={"链接":bookHref,
"书名":bookTitle,
"评分":bookScore,
"评分人数":bookPeople}
self.db.restaurants.insert_one(data)#插入数据库中
print("成功存入数据库中")
except Exception as e:
print ('出错',type(e),e)
if '_main_':
dbBook = doubanBookData()
dbBook.getUrl()运行结果:
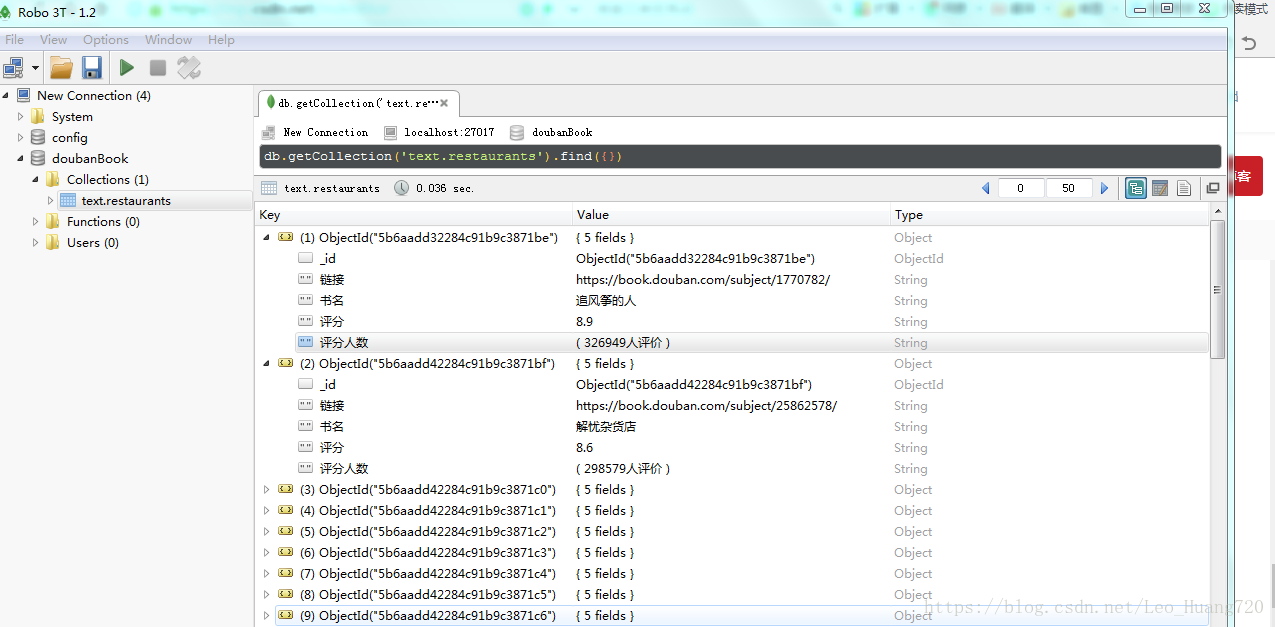
前面我们已经讲过了怎么安装Robomongo并连接MongoDB,直接打开Robo 3T可视化界面查看
附:&官方文档PyMongo 3.7.1 Documentation — PyMongo 3.7.1 documentation http://api.mongodb.com/python/current/