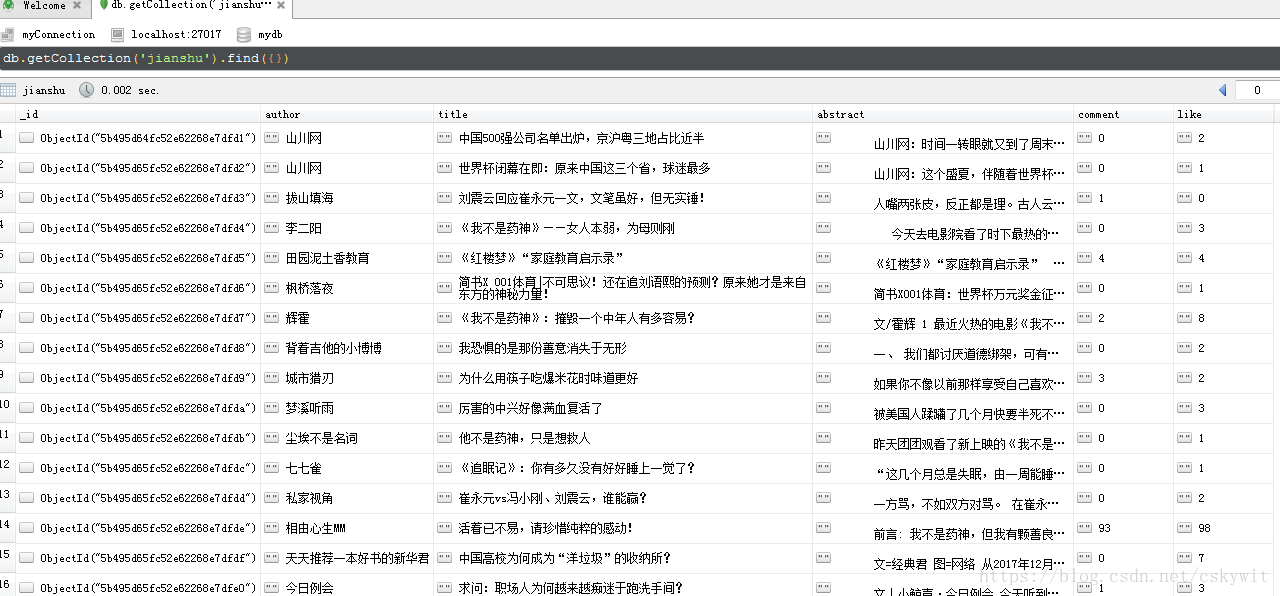
本代码爬取简书社会热点栏目10000页的数据,使用多进程方式爬取,从简书网页可以看出,网页使用了异步加载,页码只能从response中推测出来,从而构造url,直接上代码:
import requests
from lxml import etree
import pymongo
from multiprocessing import Pool
import time
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'
}
client = pymongo.MongoClient('localhost',27017)
mydb = client['mydb']
jianshu = mydb['jianshu_2']
num = 0
def get_jianshu_info(url):
global num
html = requests.get(url,headers=headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//ul[@class="note-list"]/li')
for info in infos:
try:
author = info.xpath('div/div/a[1]/text()')[0]
title = info.xpath('div/a/text()')[0]
abstract = info.xpath('div/p/text()')[0]
comment = info.xpath('div/div/a[2]/text()')[1].strip()
like = info.xpath('div/div/span/text()')[0].strip()
data = {
'author':author,
'title':title,
'abstract':abstract,
'comment':comment,
'like':like
}
jianshu.insert_one(data)
num = num +1
print("已爬取第{}条信息".format(str(num)))
except IndexError:
pass
if __name__=='__main__':
urls = ['https://www.jianshu.com/c/20f7f4031550?utm_medium=index-collections&utm_source=desktop&page={}'.format(str(i)) for i in range(1,10000)]
pool = Pool(processes=8)
start_time = time.time()
pool.map(get_jianshu_info,urls)
end_time = time.time()
print("八进程爬虫耗费时间:", end_time - start_time)可以看到爬取的信息已经保存到了mongodb中: