一、scrapy 安装:可直接使用Anaconda Navigator安装, 也可使用pip install scrapy安装
二、创建scrapy 爬虫项目:语句格式为 scrapy startproject project_name

生成的爬虫项目目录如下,其中spiders是自己真正要编写的爬虫。
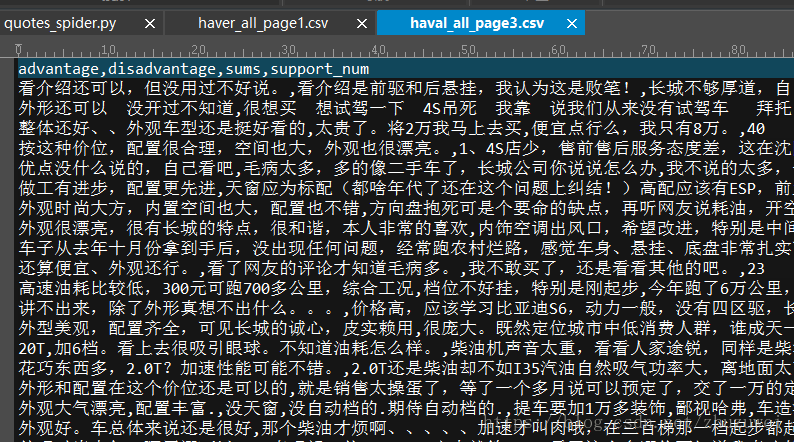
三、爬取腾讯新闻并保存到csv文件
1. 只爬取一个页面:在spiders目录下创建spider程序car_comment_spider.py 并编辑代码如下:
import scrapy
class CarCommentSpider(scrapy.Spider):
name = 'CarComment' # 蜘蛛的名字
# 指定要抓取的网页
start_urls = ['https://koubei.16888.com/117870/']
# 网页解析函数
def parse(self, response):
for car in response.xpath('/html/body/div/div/div/div[@class="mouth_box"]/dl'): # 遍历xpath
advantage = car.xpath('dd/div[2]/p[1]/span[@class="show_dp f_r"]/text()').extract_first()
disadvantage = car.xpath('dd/div[2]/p[2]/span[2]/text()').extract_first()
sums = car.xpath('dd/div[2]/p[3]/span[2]/text()').extract_first()
support_num = car.xpath('dd/div/div[@class="like f_r"]/a/text()').extract_first()
print('优点:',advantage)
print('缺点:',disadvantage)
print('综述:',sums)
print('支持人数:',support_num)在cmd命令行中执行scrapy runspider car_comment_spider.py

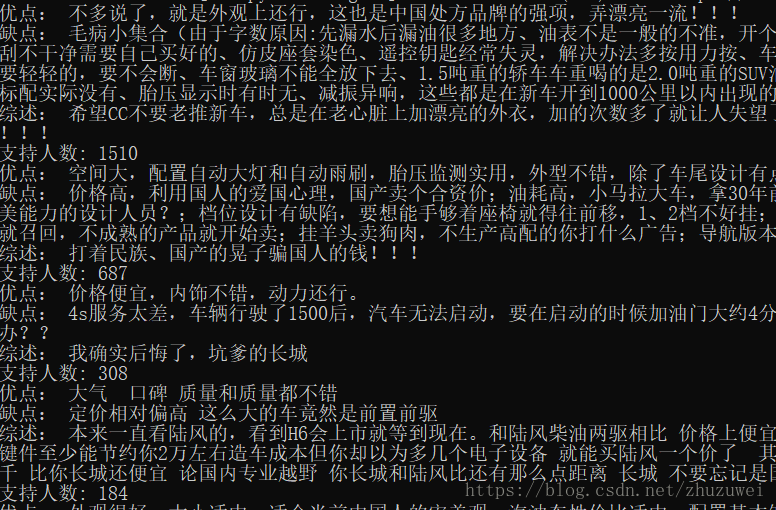
2. 爬取某个车型的所有评论并保存到csv文件
(1)自行组建不同页面的url: 根据网页url的规律可设置
start_urls = ['https://koubei.16888.com/117870/0-0-0-%s' % p for p in range(1,125)]
import scrapy
class CarCommentSpider(scrapy.Spider):
name = 'CarComment' # 蜘蛛的名字
# 指定要抓取的网页, 从第1页到第124页,程序会自动解析每个url
start_urls = ['https://koubei.16888.com/117870/0-0-0-%s' % p for p in range(1,125)]
# 网页解析函数
def parse(self, response):
for car in response.xpath('/html/body/div/div/div/div[@class="mouth_box"]/dl'): # 遍历xpath
advantage = car.xpath('dd/div[2]/p[1]/span[@class="show_dp f_r"]/text()').extract_first()
disadvantage = car.xpath('dd/div[2]/p[2]/span[2]/text()').extract_first()
sums = car.xpath('dd/div[2]/p[3]/span[2]/text()').extract_first()
support_num = car.xpath('dd/div/div[@class="like f_r"]/a/text()').extract_first()
print('优点:',advantage)
print('缺点:',disadvantage)
print('综述:',sums)
print('支持人数:',support_num)
if len(advantage) != 0 and len(disadvantage) != 0 and len(sums) != 0 and len(support_num) != 0:
yield {'advantage':advantage, 'disadvantage':disadvantage, 'sums':sums, 'support_num':support_num}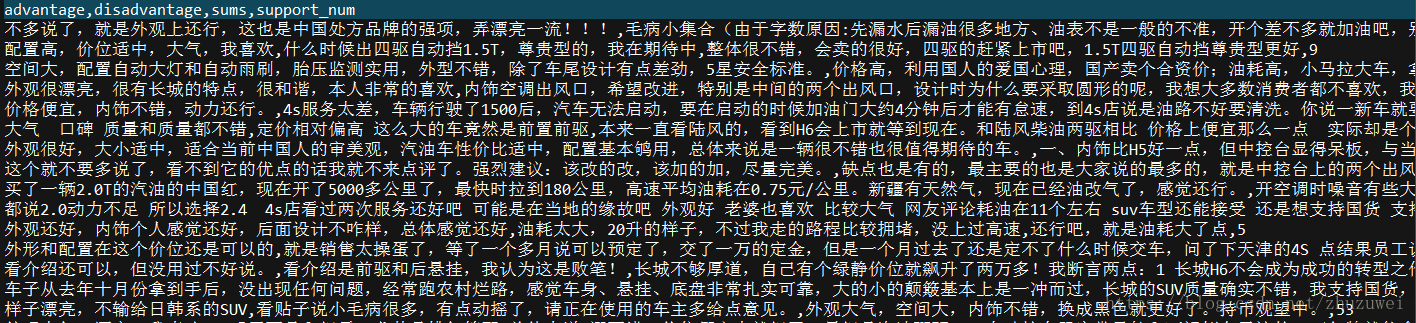
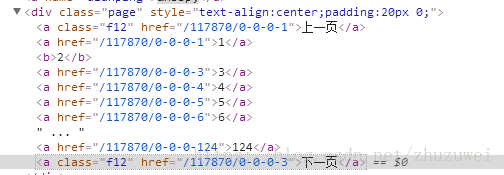
(2)从每一页的代码解析找到下一页的url
下一页的url在a标签中,此处存在多个a标签,故需要从中找到下一页对应的a标签

import scrapy
class CarCommentSpider(scrapy.Spider):
name = 'CarComment' # 蜘蛛的名字
# 指定要抓取的网页, 从第1页到第124页,程序会自动解析每个url
start_urls = ['https://koubei.16888.com/117870/0-0-0-1/']
# 网页解析函数
def parse(self, response):
for car in response.xpath('/html/body/div/div/div/div[@class="mouth_box"]/dl'): # 遍历xpath
advantage = car.xpath('dd/div[2]/p[1]/span[@class="show_dp f_r"]/text()').extract_first()
disadvantage = car.xpath('dd/div[2]/p[2]/span[2]/text()').extract_first()
sums = car.xpath('dd/div[2]/p[3]/span[2]/text()').extract_first()
support_num = car.xpath('dd/div/div[@class="like f_r"]/a/text()').extract_first()
print('优点:',advantage)
print('缺点:',disadvantage)
print('综述:',sums)
print('支持人数:',support_num)
if advantage is not None and disadvantage is not None and sums is not None and support_num is not None:
yield {'advantage':advantage, 'disadvantage':disadvantage, 'sums':sums, 'support_num':support_num}
n = len(response.xpath('/html/body/div/div/div/div/div[@class="page"]/a'))
for i in range(1,n+1): # 遍历每个a元素,获取下一页的url
text = response.xpath('/html/body/div/div/div/div/div[@class="page"]/a['+str(i)+']/text()').extract_first()
if text == '下一页':
next_page = response.xpath('/html/body/div/div/div/div/div[@class="page"]/a['+str(i)+']/@href').extract_first()
next_page = response.urljoin(next_page) # 将相对地址转换为绝对地址
yield scrapy.Request(next_page, callback=self.parse) # next_page继续进行spider解析