目录
Selenium库的find_element的语法使用格式如下。
逆向分析爬取动态网页
了解静态网页和动态网页区别
1.判断静态网页
在浏览器中打开网站“http://www.tipdm.com”,按“F12”键调出Chrome开发者工具或者单击“更多工具”选项中的“开发者工具”选项。Chrome开发者工具中的元素面板上显示的是浏览器执行JavaScript之后生成的HTML源码。找到解决方案的第一条数据对应的HTML源码,如图所示。
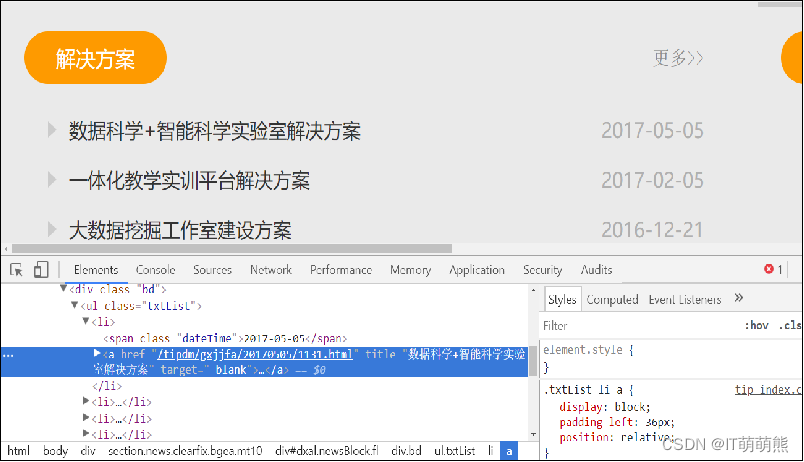
还有另一种方法查看源码,右键单击鼠标页面,选择“查看页面源代码”,如图所示。
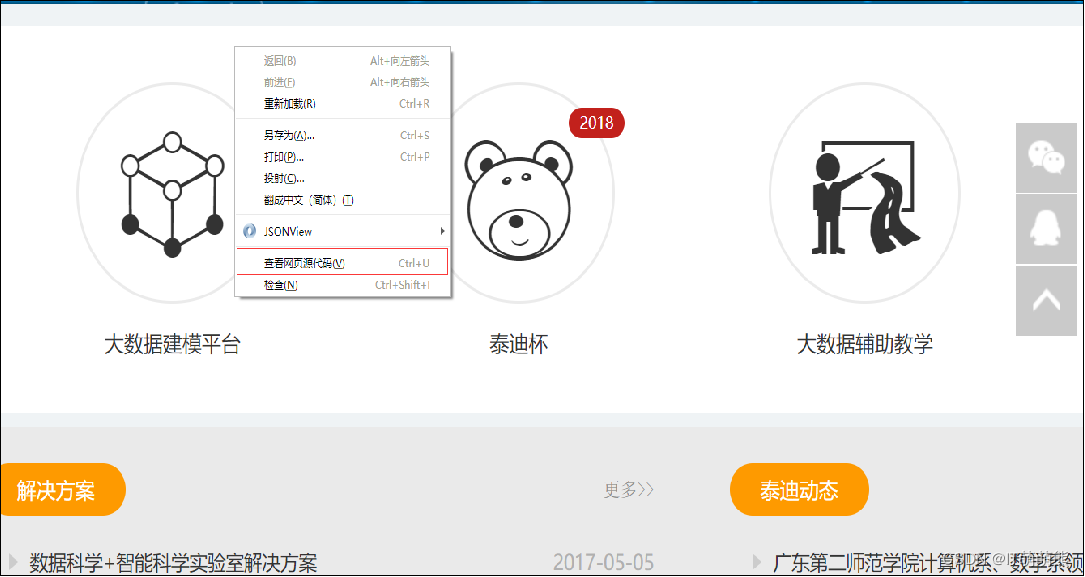
得到服务器直接返回的HTML源码,找到解决方案的第一条数据的信息,如图所示。
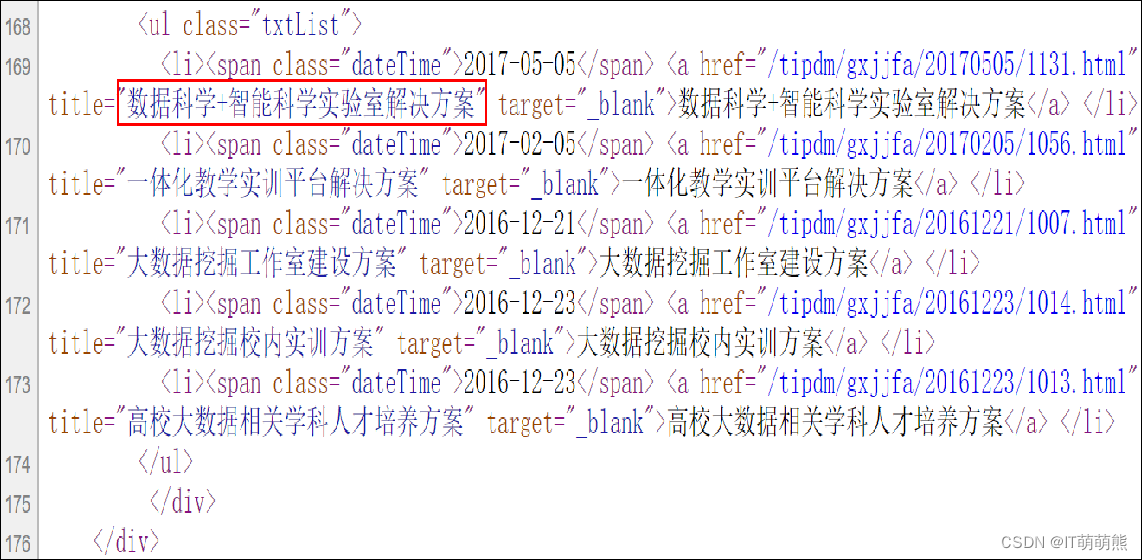
2.判断动态网页
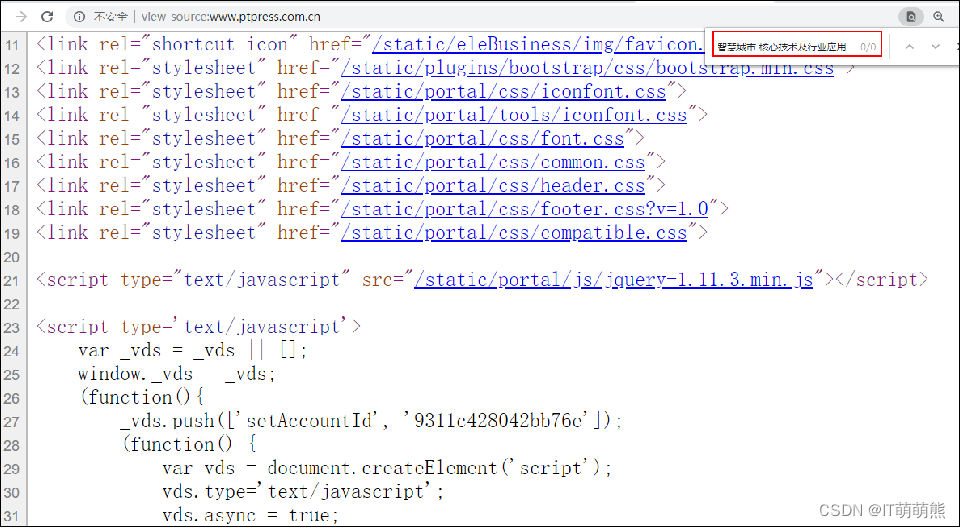
在浏览器中打开网站“http://www.ptpress.com.cn”,按“F12”键调出Chrome开发者工具,找到“互联网+智慧城市 核心技术及行业应用”的HTML信息,如图所示。

在浏览器呈现的网页中,右键单击页面,单击“查看页面源代码”选项,在弹出的HTML源码中,查找“互联网+智慧城市 核心技术及行业应用”关键字,如图所示。
逆向分析爬取动态网页
在确认网页是动态网页后,需要获取从网页响应中由JavaScript动态加载生成的信息,在Chrome浏览器中爬取“http://www.ptpress.com.cn”网页的信息,步骤如下。
“F12”键打开“http://www.ptpress.com.cn”网页的Chrome开发者工具,如图所示。
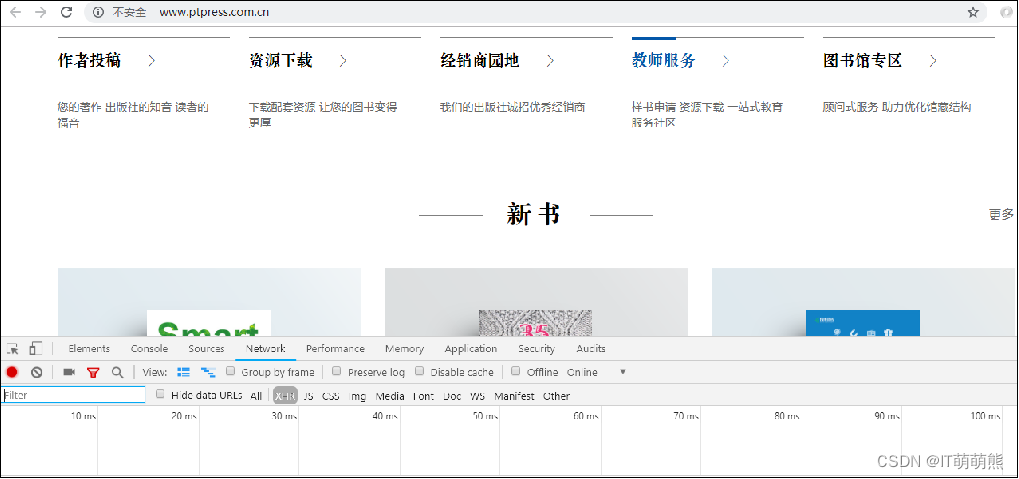
单击网络面板后,发现有很多响应。在网络面板中XHR是Ajax中的概念,表示XML-HTTP-request,一般Javascript加载的文件隐藏在JS或者XHR。通过查找发“http://www.ptpress.com.cn”网页。
“新书”模块的信息在XHR的Preview标签中有需要的信息。在网络面板的XHR中,查看“/bookinfo”资源的Preview信息,可以看到网页新书的HTML信息,如图所示。

若需要爬取“http://www.ptpress.com.cn”网页标题信息,则步骤如下。
单击“/bookinfo”资源的Headers标签,找到“Request URL”信息,如图所示。
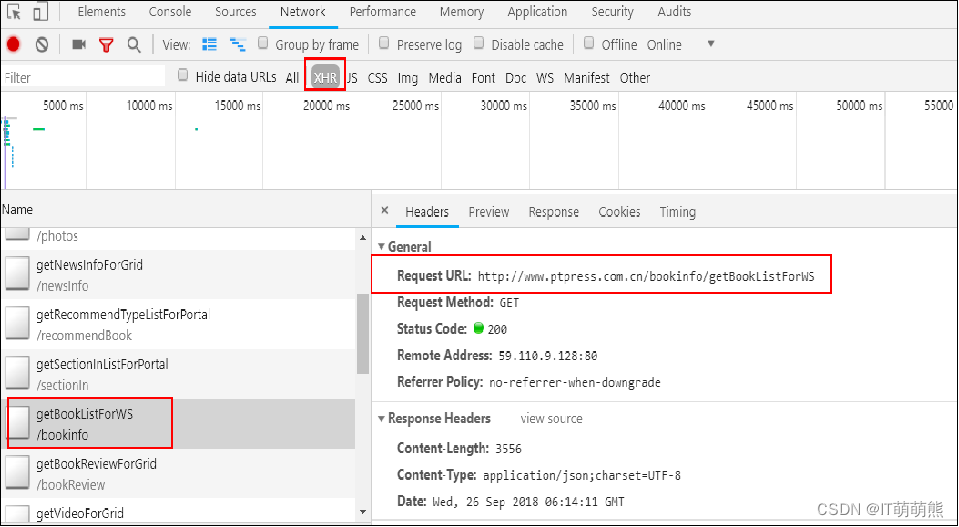
打开“Request URL”URL网址信息,找到需要爬取的信息,如图所示。
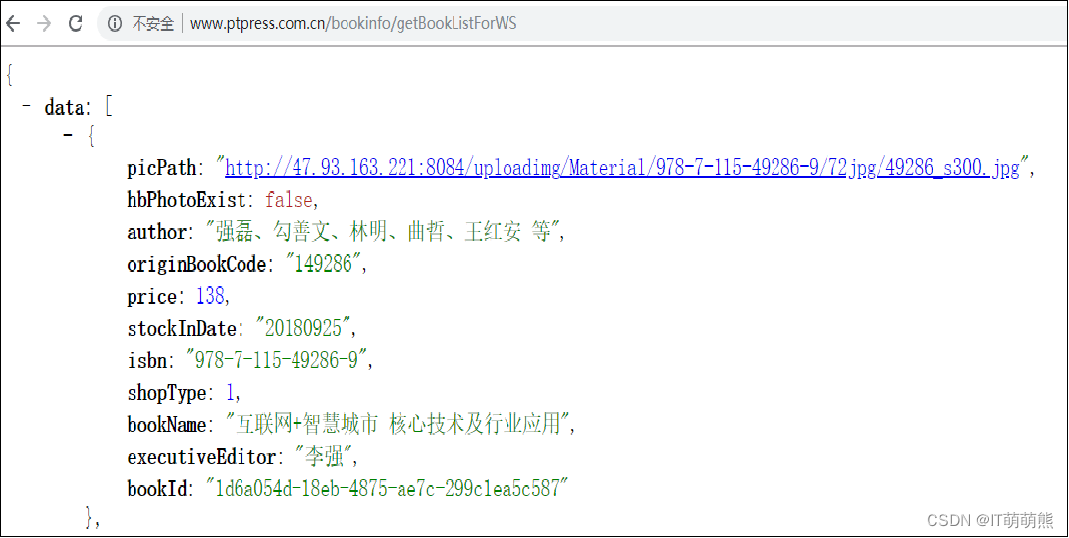
爬取“http://www.ptpress.com.cn”首页新书模块的书名、作者和价格,如代码 4‑1所示。
使用Selenium库爬取动态网页
安装Selenium库以及下载浏览器补丁
以Chrome浏览器的chromedrive补丁为例,在安装好Selenium 3.9.0之后,下载并安装chromedrive补丁的步骤如下。
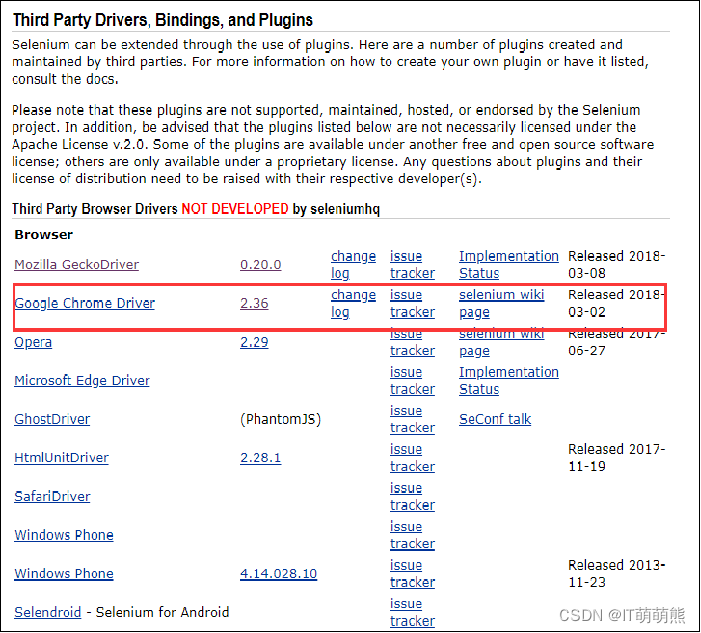
在Selenium官网下载对应版本的补丁。下载如图所示的“Google Chrome Driver 2.36”文件,根据操作系统选择chromedrive文件。
将下载好的chromedrive.exe文件,存放至python安装根目录(与python.exe文件同一目录)即可。
页面等待
Selenium Webdriver提供两种类型的等待——隐式和显式。显式的等待使网络驱动程序在继续执行之前等待某个条件的发生。隐式的等待使WebDriver在尝试定位一个元素时,在一定的时间内轮询DOM。在爬取“http://www.ptpress.com.cn/search/books”网页搜索“Python编程”关键词过程中,用到了显示等待,本节主要介绍显示等待。显式等待是指定某个条件,然后设置最长等待时间。如果在这个时间还没有找到元素,那么便会抛出异常,在登“http://www.ptpress.com.cn/search/books”网页等待10秒。
WebDriverWait函数是默认每500毫秒调用一次ExpectedCondition,直到成功返回。ExpectedCondition的成功返回类型是布尔值,对于所有其他ExpectedCondition类型,则返回True或非Null返回值。如果在10秒内不能发现元素返回,就会在抛出TimeoutException异常。 WebDriverWait的语法使用格式如下。

页面操作
1.填充表单
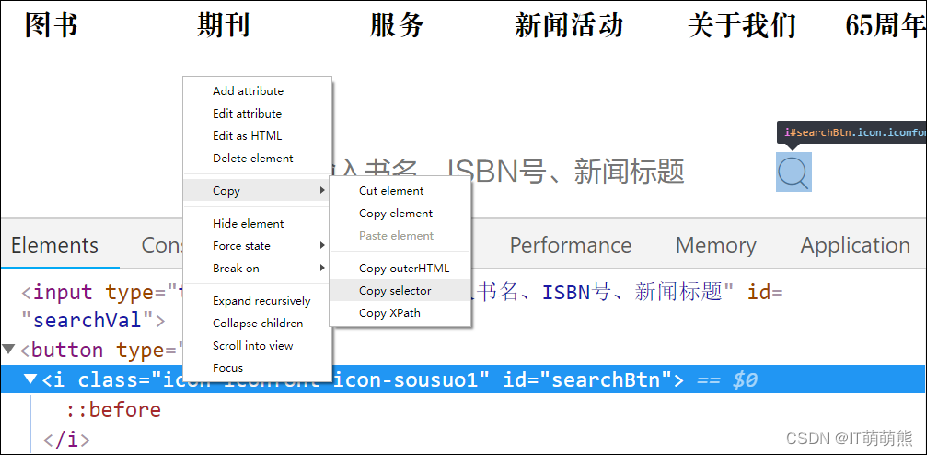
HTML表单包含了表单元素,而表单元素指的是不同类型的input元素、复选框、单选按钮、提交按钮等。填写完表单后,需要提交表单。定位“搜索”按钮并复制该元素的selector,如图所示。
2.执行JavaScript
Selenium库中的execute_script方法能够直接调用JavaScript方法来实现翻页到底部、弹框等操作。比如在“http://www.ptpress.com.cn/search/books”网页中通过JavaScript翻到页面底部,并弹框提示爬虫。
元素选取
在页面中定位元素有多种策略。Selenium库提供了如表所示的方法来定位页面中的元素,使用find_element进行元素选取。在单元素查找中使用到了通过元素ID进行定位、通过XPath表达式进行定位、通过CSS选择器进行定位等操作。在多元素查找中使用到了通过CSS选择器进行定位等操作。
| 定位一个元素 |
定位多个元素 |
含义 |
| find_element_by_id |
find_elements_by_id |
通过元素ID进行定位 |
| find_element_by_name |
find_elements_by_name |
通过元素名称进行定位 |
| find_element_by_xpath |
find_elements_by_xpath |
通过XPath表达式进行定位 |
| find_element_by_link_text |
find_elements_by_link_text |
通过完整超链接文本进行定位 |
| find_element_by_partial_link_text |
find_elements_by_partial_link_text |
通过部分超链接文本进行定位 |
| find_element_by_tag_name |
find_elements_by_tag_name |
通过标记名称进行定位 |
| find_element_by_class_name |
find_elements_by_class_name |
通过类名进行定位 |
| find_element_by_css_selector |
find_elements_by_css_selector |
通过CSS选择器进行定位 |
Selenium库的find_element的语法使用格式如下。
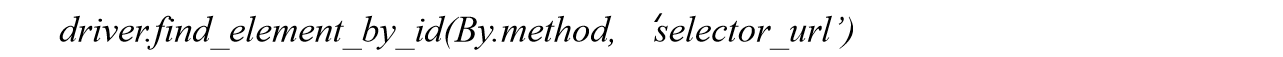
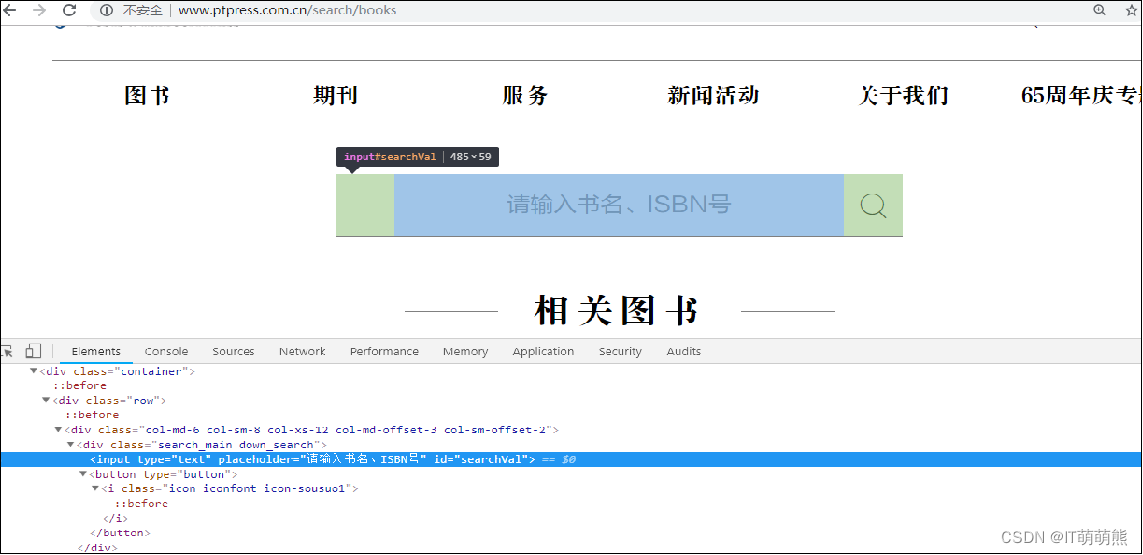
1.单个元素查找
获取“http://www.ptpress.com.cn/search/books”响应的网页搜索框架元素,如图所示。
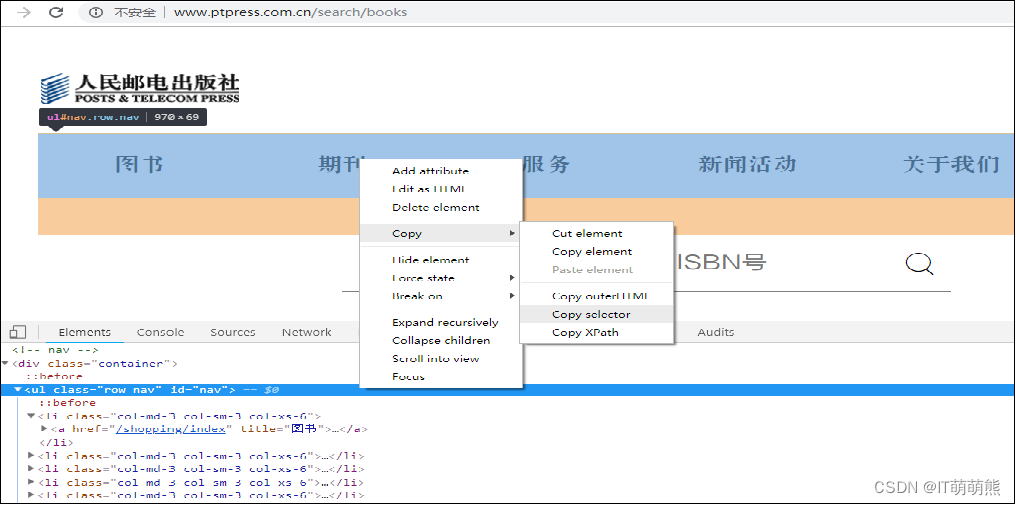
2.多个元素查找
查找“http://www.ptpress.com.cn/search/books”网页第一行多个信息,复制到selector的信息是“#nav”如图所示。
预期的条件
在自动化Web浏览器时,不需要手动编写期望的条件类,也不必为自动化创建实用程序包,Selenium库提供了一些便利的判断方法如表 4‑2所示,在爬取“http://www.ptpress.com.cn/search/books”网页搜索“Python编程”关键词的过程中,用到了element_to_be_clickable方法、元素是否可点击等判断方法。
| 方法 |
作用 |
| title_is |
标题是某内容 |
| title_contains |
标题包含某内容 |
| presence_of_element_located |
元素加载出,传入定位元组,如(By.ID, 'p') |
| visibility_of_element_located |
元素可见,传入定位元组 |
| visibility_of |
传入元素对象 |
| presence_of_all_elements_located |
所有元素加载出 |
| text_to_be_present_in_element |
某个元素文本包含某文字 |
| text_to_be_present_in_element_value |
某个元素值包含某文字 |
| 方法 |
作用 |
| frame_to_be_available_and_switch_to_it frame |
加载并切换 |
| invisibility_of_element_located |
元素不可见 |
| element_to_be_clickable |
元素可点击 |
| staleness_of |
判断一个元素是否仍在DOM,可判断页面是否已经刷新 |
| element_to_be_selected |
元素可选择,传元素对象 |
| element_located_to_be_selected |
元素可选择,传入定位元组 |
| element_selection_state_to_be |
传入元素对象以及状态,相等返回True,否则返回False |
| element_located_selection_state_to_be |
传入定位元组以及状态,相等返回True,否则返回False |
| alert_is_present |
是否出现Alert |
结果分析
了解MongoDB数据库和MySQL数据库的区别
传统的关系数据库一般由数据库(database)、表(table)、记录(record)三个层次概念组成,MongoDB是由数据库(database)、集合(collection)、文档对象(document)三个层次组成。MongoDB中的概念和MySQL中的概念进行对比,如表所示。
| SQL概念 |
MongoDB概念 |
说明 |
| database |
database |
数据库 |
| table |
collection |
数据库表∕集合 |
| row |
document |
数据库行∕文档 |
| column |
field |
数据字段列∕域 |
| index |
index |
索引 |
| primary key |
primary key |
主键 |
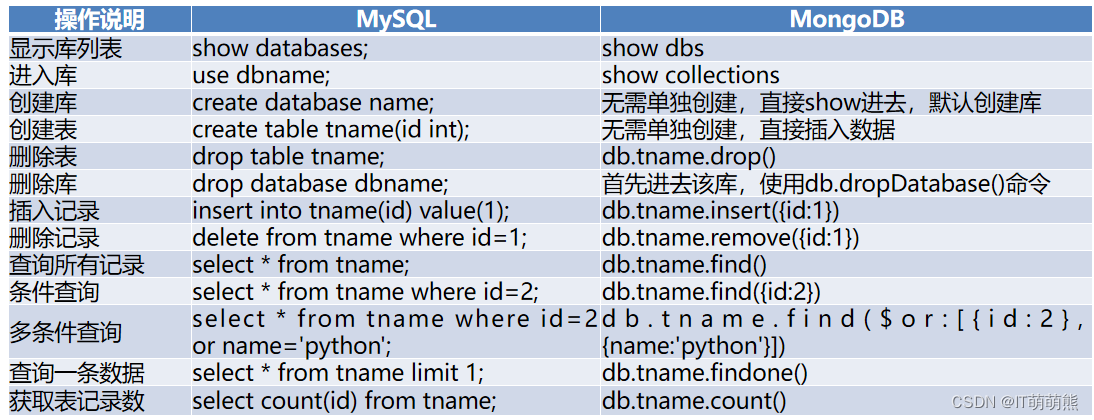
MongoDB具有独特操作语句,与MySQL使用传统的sql语句不同。MongoDB与MySQL基本操作命令的区别如表所示。
 将数据存储入MongoDB数据库
将数据存储入MongoDB数据库
1.建立连接
pymongo是Python用于操作MongoDB的模块,在导入pymongo模块之前,需要先使用pip命令安装pymongo模块,安装成功之后,导入pymongo模块,然后建立连接。MongoDB连接字符串的格式如下。

2.获取数据库
MongoDB的一个实例可以支持多个独立的数据库。在使用pymongo模块时,可以使用MongoClient实例上的属性的方式来访问数据库,如果数据库名称使用属性方式访问无法正常工作(如:python-db),也可以使用字典方式访问。
3.获取一个集合
集合是存储在MongoDB中的一组文档,可以类似于关系数据库中的表。在pymongo模块中获取集合的方式与获取数据库一样,或者使用字典方式获取集合。
4.插入文档
数据在MongoDB中是以JSON类文件的形式保存起来的,而且存储到MongoDB数据库中的数据类型必须是{key:value}型的。在pymongo模块中使用inset_one方法插入文档,将4.1.2小节爬取到的新书信息存储到MongoDB数据库中。
总结
本章介绍了两种方法爬取动态网页,分别是逆向分析爬取和通过Selenium爬取,同时也介绍了如何将爬取到的数据,储存到MongoDB中,具体内容如下。
通过源码比对,实现了静态网页与动态网页的区分。
使用逆向分析技术爬取网站“http://www.ptpress.com.cn”首页新书信息。
使用Selenium爬取网站“http://www.ptpress.com.cn/search/books”中的以“python编程”为关键词的信息。
将爬取到的数据,储存至MongoDB数据库。