写在前面的话:每一个实例的代码都会附上相应的代码片或者图片,保证代码完整展示在博客中。最重要的是保证例程的完整性!!!方便自己也方便他人~欢迎大家交流讨论~
环境:Anaconda3(python3.5)
爬虫学习打卡3——xpath https://blog.csdn.net/Leo_Huang720/article/details/81433841中我们已经用xpath在豆瓣图书TOP250中爬取了250本书的信息,这么多的信息在console中不方便查阅,所以今天我们把数据放入Excel中,并讲解从Excel中存取数据的方法!
从Excel提取数据信息
新建一个Excel,取名为,并输入以下信息
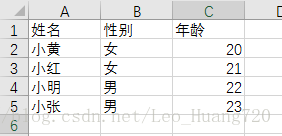
一个execl文件一般都至少有一个table,图中的Sheet1就表示一个table

调用xlrd库从Excel中提取数据(“xlrd”是E x ce lr ea d 的缩写)
import xlrd
data = xlrd.open_workbook("F:/Python/SPIDER/read_excel.xlsx")#Excel文件地址
table = data.sheets()[0] #通过索引顺序获取table,Sheet1索引为0
rowsNum=table.nrows#获取行数
colsNum=table.ncols#获取列数
print(rowsNum)
print(colsNum)
for k in range(rowsNum): #遍历行数据
print (table.row_values(k))
for i in range(colsNum): #遍历列数据
print(table.col_values(i))
#获取单元格数据,cell()前一个是行数,从0开始,后一个是列数,且列数从0开始
print (table.cell(2,2).value)
for a in range(1,rowsNum): #行数据,去掉第1行标题,range从1开始
for b in range(colsNum):
print( table.cell(a,b).value)
print ('----------------------')运行结果:

数据存入Excel
调用xlwt库从Excel中提取数据(“xlrd”是E x ce lw ri t e 的缩写)
import xlwt
f = xlwt.Workbook() #创建工作薄
#创建个人信息表
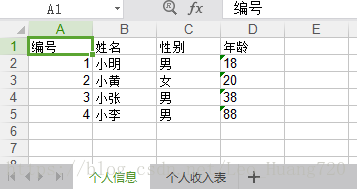
sheet1 = f.add_sheet(u'个人信息',cell_overwrite_ok=True)
rowTitle = [u'编号',u'姓名',u'性别',u'年龄']
rowDatas = [[u'小明',u'男',u'18'],[u'小黄',u'女',u'20'],[u'小张',u'男',u'38'],[u'小李',u'男',u'88']]
for i in range(0,len(rowTitle)):
sheet1.write(0,i,rowTitle[i])
for k in range(0,len(rowDatas)): #先遍历外层的集合,即每行数据
rowDatas[k].insert(0,k+1) #每一行数据插上编号即为每一个人插上编号
for j in range(0,len(rowDatas[k])): #再遍历内层集合
sheet1.write(k+1,j,rowDatas[k][j]) #写入数据,k+1表示先去掉标题行,另外每一行数据也会变化,j正好表示第一列数据的变化,rowdatas[k][j] 插入数据
#创建个人收入表
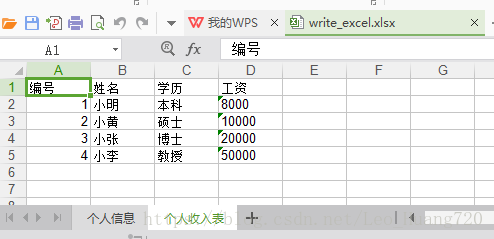
sheet1 = f.add_sheet(u'个人收入表',cell_overwrite_ok=True)
rowTitle2 = [u'编号',u'姓名',u'学历',u'工资']
rowDatas2 = [[u'小明',u'本科',u'8000'],[u'小黄',u'硕士',u'10000'],[u'小张',u'博士',u'20000'],[u'小李',u'教授',u'50000']]
for i in range(0,len(rowTitle2)):
sheet1.write(0,i,rowTitle2[i])
for k in range(0,len(rowDatas2)): #先遍历外层的集合
rowDatas2[k].insert(0,k+1) #每一行数据插上编号即为每一个人插上编号
for j in range(0,len(rowDatas2[k])): #再遍历内层集合
sheet1.write(k+1,j,rowDatas2[k][j]) #写入数据,k+1表示先去掉标题行,另外每一行数据也会变化,j正好表示第一列数据的变化,rowdatas[k][j] 插入数据
f.save('F:/Python/SPIDER/write_excel.xlsx')运行结果:
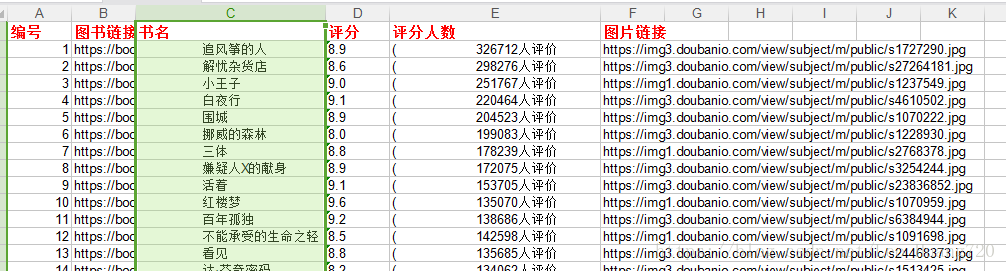
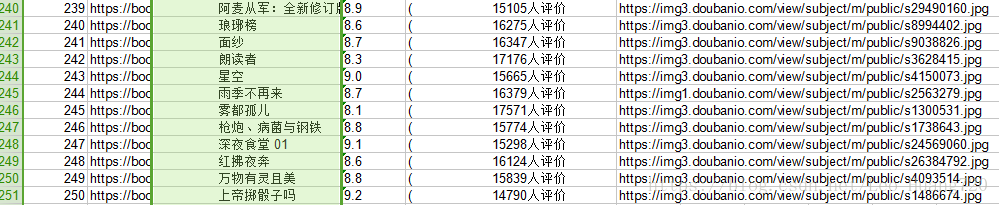
爬取数据存入Excel
学会了用python进行Excel的数据操作之后,我们来把数据放入Excel中吧
import requests
import xlwt
import xlrd
from lxml import etree
class doubanBookData(object):
def __init__(self):
self.f = xlwt.Workbook() #创建工作薄
self.sheet1 = self.f.add_sheet(u'图书列表',cell_overwrite_ok=True)#命名table
self.rowsTitle = [u'编号',u'图书链接',u'书名',u'评分',u'评分人数',u'图片链接']#创建标题
for i in range(0, len(self.rowsTitle)):
#最后一个参数设置样式
self.sheet1.write(0, i, self.rowsTitle[i], self.set_style('Times new Roman', 220, True))
#Excel保存位置
self.f.save('F:/Python/SPIDER/Book.xlsx')
#该函数设置字体样式
def set_style(self,name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name
font.bold = bold
font.colour_index = 2
font.height = height
style.font = font
return style
def getUrl(self):
for i in range(10):
url = 'https://book.douban.com/top250?start={}'.format(i*25)
self.spiderPage(url)
def spiderPage(self,url):
if url is None:
return None
try:
data = xlrd.open_workbook('F:/Python/SPIDER/Book.xlsx')#打开Excel文件
table = data.sheets()[0] #通过索引顺序获取table,因为初始化时只创建了一个table,因此索引值为0
rowCount = table.nrows #获取行数 ,下次从这一行开始
proxies = {#使用代理IP,获取IP的方式在上一篇文章爬虫打卡4中有叙述
'http':'http://110.73.1.47:8123'}
user_agent='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
headers = {'User-Agent': user_agent}
respon=requests.get(url, headers=headers,proxies=proxies)#获得响应
htmlText=respon.text#打印html内容
s = etree.HTML(htmlText)#将源码转化为能被XPath匹配的格式
trs = s.xpath('//*[@id="content"]/div/div[1]/div/table/tr')#提取相同的前缀
m = 0
for tr in trs:
data = []
bookHref=tr.xpath('./td[2]/div[1]/a/@href')
bookTitle=tr.xpath('./td[2]/div[1]/a/text()')
bookScore=tr.xpath('./td[2]/div[2]/span[2]/text()')
bookPeople=tr.xpath('./td[2]/div[2]/span[3]/text()')
bookImg=tr.xpath('./td[1]/a/img/@src')
bookHref = bookHref[0] if bookHref else '' # python的三目运算 :为真时的结果 if 判定条件 else 为假时的结果
bookTitle = bookTitle[0] if bookTitle else ''
bookScore = bookScore[0] if bookScore else ''
bookPeople =bookPeople[0] if bookPeople else ''
bookImg = bookImg[0] if bookImg else ''
#拼装成一个列表
data.append(rowCount+m) #为每条书添加序号
data.append(bookHref)
data.append(bookTitle)
data.append(bookScore)
data.append(bookPeople)
data.append(bookImg)
for i in range(len(data)):
self.sheet1.write(rowCount+m,i,data[i]) #写入数据到execl中
m+=1 #记录行数增量
print(m)
print (bookHref,bookTitle,bookScore,bookPeople,bookImg)
except Exception as e:
print ('出错',type(e),e)
finally:
self.f.save('F:/Python/SPIDER/Book.xlsx')
if '_main_':
dbBook = doubanBookData()
dbBook.getUrl()运行结果: