版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_25343557/article/details/82392399
必知
首先我们需要切记的是我们需要爬取的微博地址为:https://m.weibo.cn。不是https://weibo.com/。因为前者的数据时通过AJAX加载的,有利于我们的抓取,后者难度大,本人找了半天也找不到接口。
本次我们爬取演员张一山的微博。
操作
打开开发者工具,刷新爬取页面,由于微博数据是通过AJAX请求获取的,所以选择XHR 只查看AJAX请求。
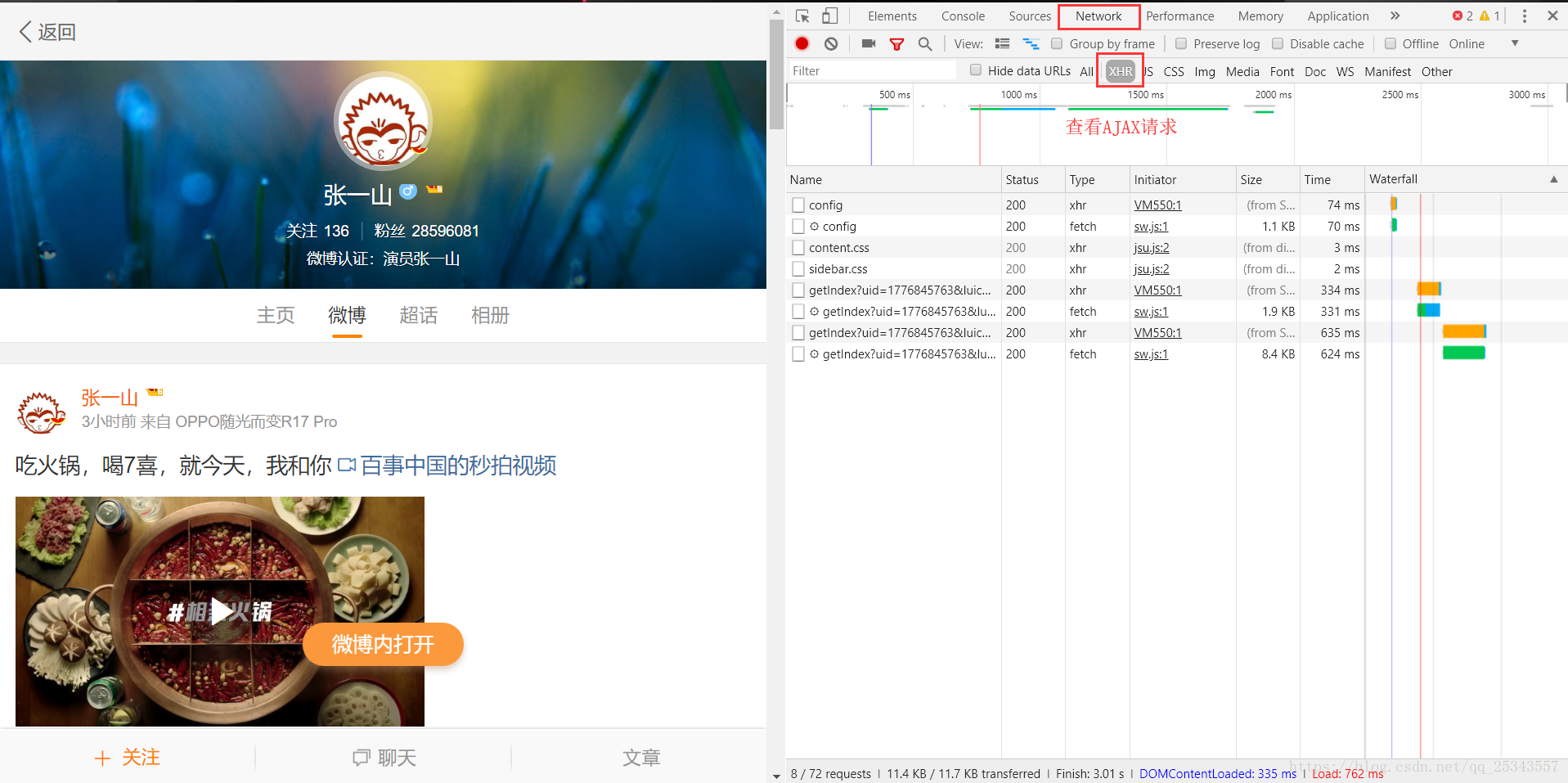
依次点击AJAX请求查找获取数据的接口。
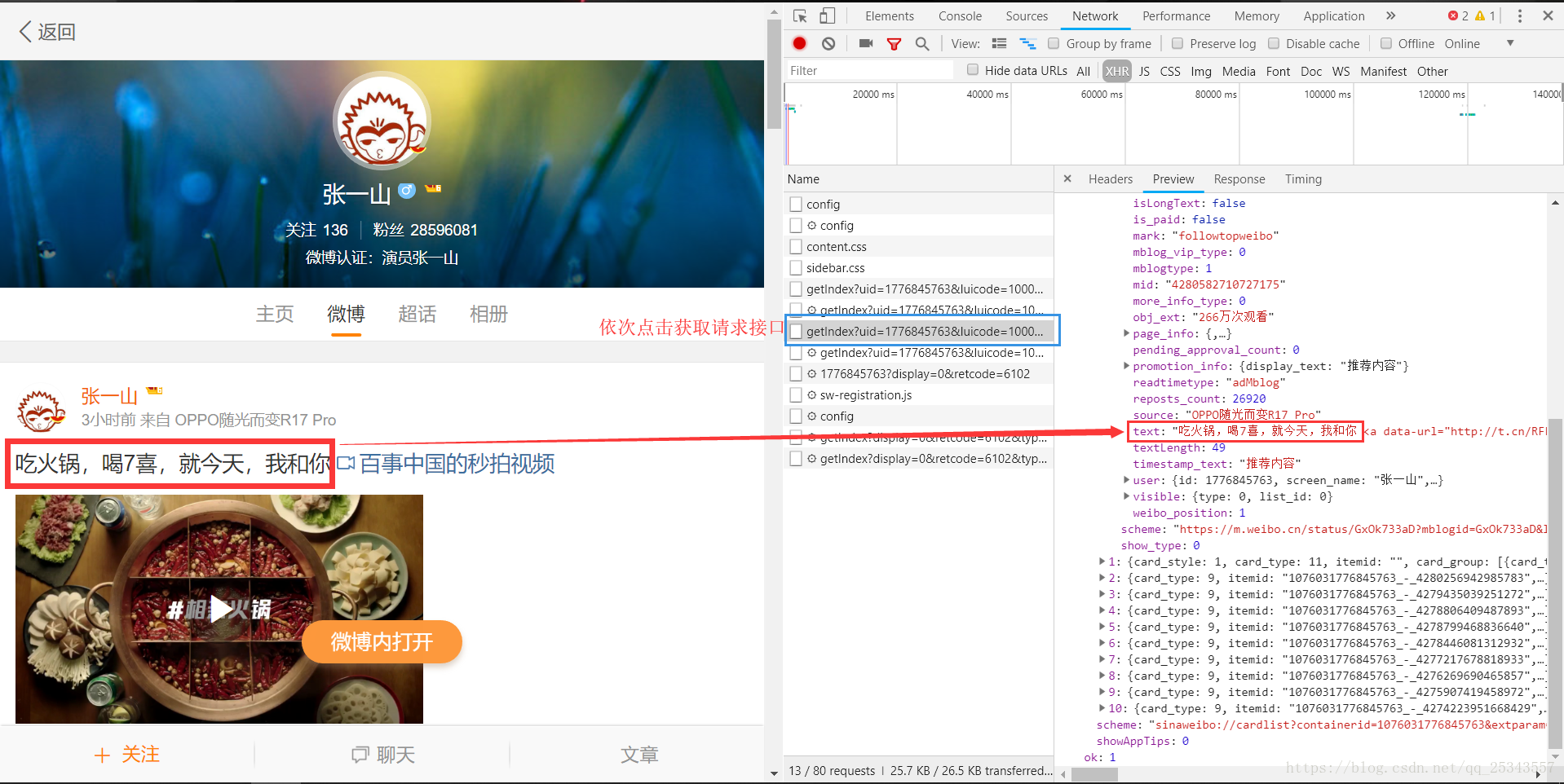
获取的接口为:
https://m.weibo.cn/api/container/getIndex?uid=1776845763&luicode=10000011&lfid=100103type=1&q=张一山&sudaref=login.sina.com.cn&display=0&retcode=6102&type=uid&value=1776845763&containerid=1076031776845763微博数据的加载时通过滚动来实现的,每一次加载10条数据。
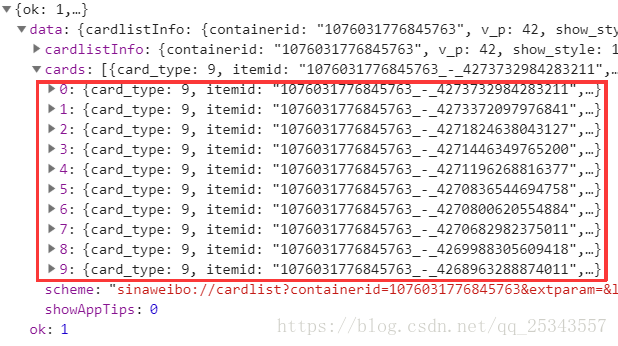
我们需要多次获取接口从而找出每次加载数据接口的变化部分,方便自动爬取。第二次加载时的接口为:
https://m.weibo.cn/api/container/getIndex?uid=1776845763&luicode=10000011&lfid=100103type=1&q=张一山&sudaref=login.sina.com.cn&display=0&retcode=6102&type=uid&value=1776845763&containerid=1076031776845763&page=2到此处我们就能发现接口的关键就是page参数。通过page的改变即可获取每页数据。
以上接口太长了,经过多次测试得出精简版接口:
https://m.weibo.cn/api/container/getIndex?uid=1776845763&type=uid&value=1776845763&containerid=1076031776845763&page=1坑
注意坑一:
通过返回的json数据我们可以很容易的发现每条微博数据都在data.cards.mblog中,但是第一次加载时需要注意以下内容也会出现在cards中:
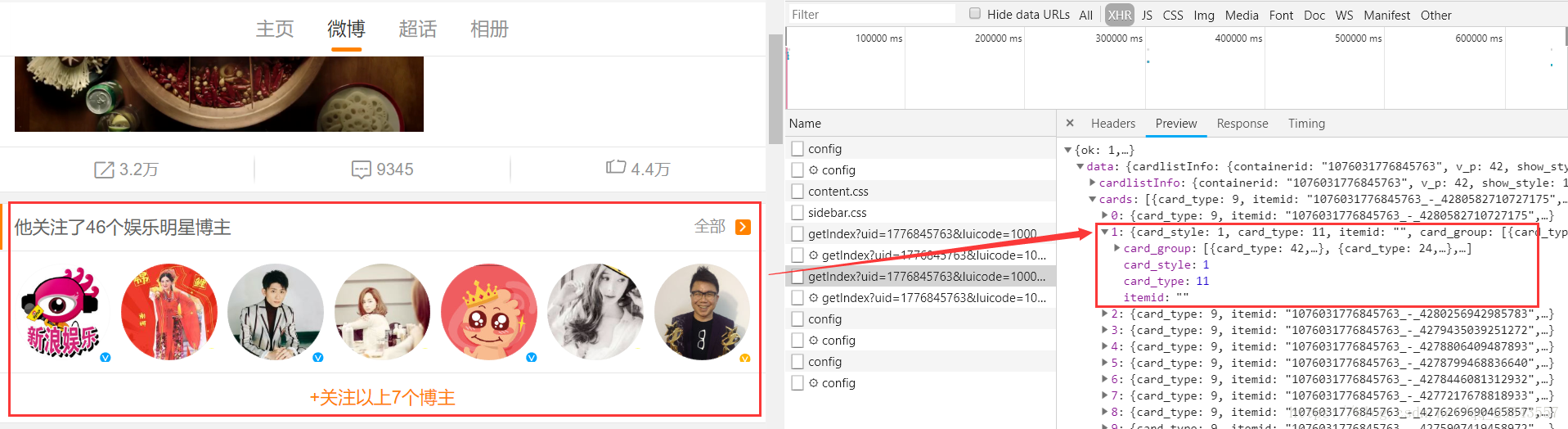
显然如果去获取mblog是会失败的,我们需要判断以下是否获取成功。
注意坑二:
有的正文中有html标签,最终结果不应该有标签,我们应该将这些标签中的文本内容取出。我们可以通过pyquery提取text。
注意坑三:
获取微博发布时间需要注意以下几种情况:
- 几小时前
- 昨天 xx
- 月-日,表示当年
- 年-月-日
所以我们需要对获取到的create_at值进行解析转换。
项目实现代码如下:
from pyquery import PyQuery as pq
from pymongo import MongoClient
from datetime import timedelta,datetime
import requests
import re
client = MongoClient(host='127.0.0.1',port=27017)
db = client.weibo
collection = db.zhangyishan
headers = {
'Host':'m.weibo.cn',
'Referer':'https://m.weibo.cn/u/1776845763',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE',
'X-Requested-With': 'XMLHttpRequest'} # 伪装成浏览器
def created_time(created_at):
'''
转换为年-月-日这种形式
:param created_at: 微博发布时间
:return: 转换后的微博发布时间
'''
if re.compile('\d{4}-\d{2}-\d{2}').match(created_at):
return created_at
else:
if re.compile('\d{2}-\d{2}').match(created_at):
return datetime.today().strftime('%Y') + '-' + created_at
else:
if re.compile('昨天').search(created_at):
return (datetime.today() + timedelta(-1)).strftime('%Y-%m-%d')
else:
return datetime.today().strftime('%Y-%m-%d')
def get_data(url):
'''
根据url获取json数据
:param url: 请求地址
:return: json形式数据
'''
try:
resp = requests.get(url,headers)
if resp.status_code == 200:
print('获取到数据')
return resp.json()
except requests.RequestException as e:
print('获取数据失败')
def parse_data(json):
'''
解析json数据
:param json: json数据
:return: 生成器
'''
if json:
items = json.get('data').get('cards')#获取所有加载的数据
for item in items:
item = item.get('mblog')#获取每条数据的信息
if item==None:
continue
data = {}
data['weiboid'] = item.get('id')#微博ID
data['source'] = item.get('source')#微博来源
#使用pyquery获取html标签内的文本内容
data['text'] = pq(item.get('text')).text()#微博正文
data['created_at'] = created_time(item.get('created_at'))#微博发布时间
data['attitudes_count'] = item.get('attitudes_count')#微博点赞数
data['comments_count'] = item.get('comments_count')#微博评论数
data['reposts_count'] = item.get('reposts_count')#微博转发数
yield data#返回一个生成器
def save_data(data):
'''
将微博数据保存到MongoDB中
:param data: 微博数据
:return:
'''
for item in data:
if collection.insert_one(item):
print('保存成功!')
def main(page):
url = 'https://m.weibo.cn/api/container/getIndex?uid=1776845763&type=uid&value=1776845763&containerid=1076031776845763&page='+str(page)
data = get_data(url)#获取数据
data = parse_data(data)#解析数据
save_data(data)#保存数据
if __name__=='__main__':
for page in range(1,51):
print('=======================正在爬取%s页======================='%page)
main(page)
扩展:以上代码获取到的只是微博内容的缩略信息,如果需要爬取全文怎么解决?