背景:淘宝的Ajax加密处理,不方便直接解析Ajax请求数据,所以利用selenium库实现模拟爬取
架构:
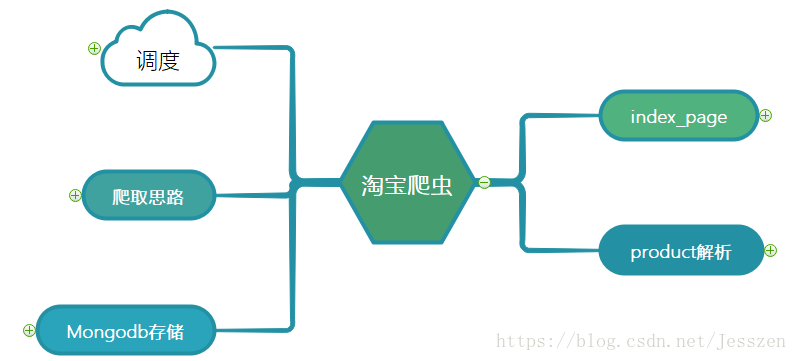
第一:主要的思路

第二:定义mongodb是类,实现数据存储

主要注意的是,mongodb用户名和密码的问题。
第三:爬取产品搜索结果页面
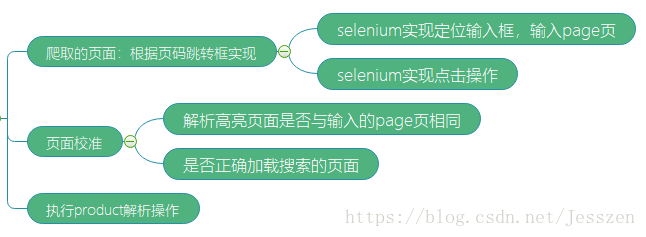
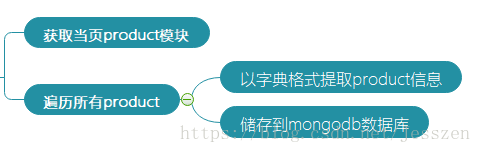
第四:解析具体的product
第五:源码
import pymongo
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from lxml import etree
from urllib.parse import quote
import time
browser=Chrome()
wait=WebDriverWait(browser,timeout=10)
keyword='ipad'
mongo_host='127.0.0.1'
mongo_port=27017
mongo_user=''
mongo_password=''
database_name='taobao'
data_col='products'
class mongodb():
def __init__(self):
self.client=pymongo.MongoClient('mongodb://{0}:{1}@{2}:{3}'.format(mongo_user,mongo_password,mongo_host,mongo_port))
self.db=self.client[database_name]#获得数据库句柄
self.col=self.db[data_col]#获得
def add(self,item):
self.col.insert(item)
mongo_data=mongodb()
def index_page(page):
"""
爬取特定页面
:param page:
:return:
"""
try:
url='https://s.taobao.com/search?q=' +quote(keyword)
browser.get(url)
if page >1:
input=wait.until(EC.presence_of_element_located((By.XPATH,'//input[@class="input J_Input"]')))#页面下脚输入框
submit=wait.until(EC.element_to_be_clickable((By.XPATH,'//span[@class="btn J_Submit"]')))
input.clear()
input.send_keys(page)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.XPATH,'//li[@class="item active"]/span'),str(page)))#当前高亮的页面数
wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="grid g-clearfix"]')))
get_product()
except TimeoutException:
index_page(page)
def get_product():
"""
提取商品数据
:return:
"""
html=browser.page_source
doc=etree.HTML(html)
items=doc.xpath('//div[@class="item J_MouserOnverReq "]')
for item in items:
product={
'image':item.xpath('.//img[@class="J_ItemPic img"]/@data-src'),
'price':item.xpath('.//div[@class="price g_price g_price-highlight"]/strong/text()'),
'shop':item.xpath('.//div[@class="shop"]/a/span[2]/text()')
}
print(product)
mongo_data.add(product)
max_page=100
def main():
for i in range(1,max_page+1):
time.sleep(5)
index_page(i)
k=main()