写文件时,我们主要用到 with open() 语句:
with open(name,mode,encoding) as file:
file.write()
# 注意,with open() 后面的语句有一个缩进
name:包含文件名称的字符串,比如:‘xiaozhu.txt’; mode:决定了打开文件的模式,只读/写入/追加等; encoding:表示我们要写入数据的编码,一般为 utf-8 或者 gbk ; file:表示我们在代码中对文件的命名。
用我们前面爬的小猪的例子来看一下,实际是什么样的:
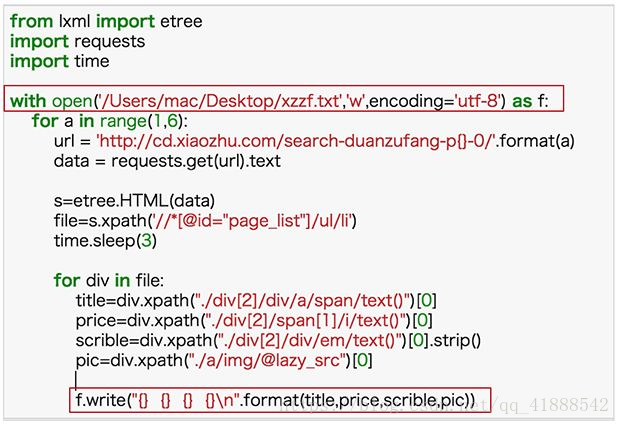
from lxml import etree
import requests
import time
with open('/Users/mac/Desktop/xzzf.txt','w',encoding='utf-8') as f:
for a in range(1,6):
url = 'http://cd.xiaozhu.com/search-duanzufang-p{}-0/'.format(a)
data = requests.get(url).text
s=etree.HTML(data)
file=s.xpath('//*[@id="page_list"]/ul/li')
time.sleep(3)
for div in file:
title=div.xpath("./div[2]/div/a/span/text()")[0]
price=div.xpath("./div[2]/span[1]/i/text()")[0]
scrible=div.xpath("./div[2]/div/em/text()")[0].strip()
pic=div.xpath("./a/img/@lazy_src")[0]
f.write("{},{},{},{}\n".format(title,price,scrible,pic))
将写入的文件名 xzzf.txt,如果没有将自动创建。
/Users/mac/Desktop/xzzf.txt
在前面加了一个桌面的路径,它将存在桌面,如果不加路径,它将存在你当前工作目录中。
w:只写的模式,如果没有文件将自动创建;
encoding='utf-8':指定写入文件的编码为:utf-8,一般指定utf-8即可;
f.write("{} {} {} {}\n".format(title,price,scrible,pic))
#将 title,price,scrible,pic 的值写入文件
来看一下存下来的数据是怎样的:

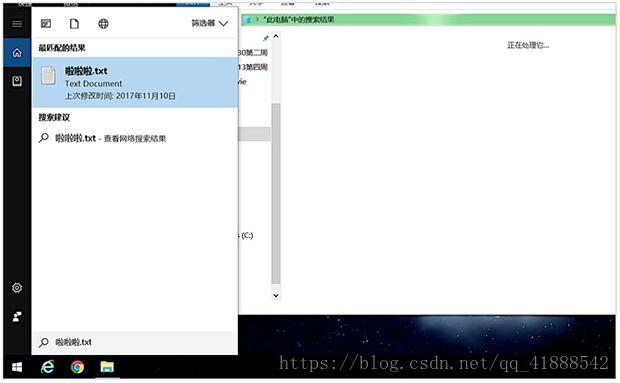
如果你没有指定文件路径,怎么找写在本地的文件呢?给你两种方法:
1.在 win10 中打开小娜(cortana),搜索你的文件名即可
2.推荐软件“everything”,查询文件更方便快捷。
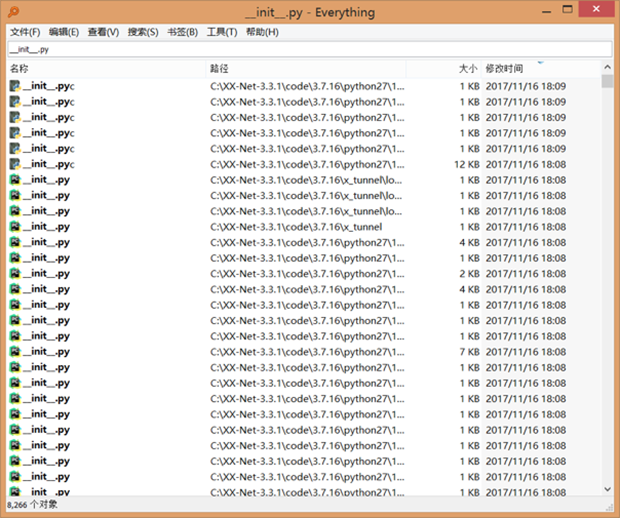
这个软件非常小,百度很容易找到,但确实是神器用了你会回来感谢我的~
所以还是建议你在写代码的时候,老老实实在文件名前面加上你想存放的路径。什么,你连路径怎么写都不知道?好吧,比如我想把文件存在桌面,那么怎么查看路径?
随便找一个文档,比如桌面的文档, 右键 >“属性”,“位置”后面的信息,就是该文档所在的路径了。
 2.文件存为CSV格式
2.文件存为CSV格式
当然,你也可以将文件存为 .csv 格式,在 with open() 语句后更改文件后缀即可。
from lxml import etree
import requests
import time
with open('/Users/mac/Desktop/xiaozhu.csv','w',encoding='utf-8') as f:
for a in range(1,6):
url = 'http://cd.xiaozhu.com/search-duanzufang-p{}-0/'.format(a)
data = requests.get(url).text
s=etree.HTML(data)
file=s.xpath('//*[@id="page_list"]/ul/li')
time.sleep(3)
for div in file:
title=div.xpath("./div[2]/div/a/span/text()")[0]
price=div.xpath("./div[2]/span[1]/i/text()")[0]
scrible=div.xpath("./div[2]/div/em/text()")[0].strip()
pic=div.xpath("./a/img/@lazy_src")[0]
f.write("{},{},{},{}\n".format(title,price,scrible,pic))

另外,需要注意的是:CSV 每个字段之间要用逗号隔开,所以这里把之前的空格改为了逗号。
CSV 文件怎么打开?
一般情况下,用记事本就可以直接打开,如果你直接用 Excel 打开,很有肯能会出现乱码,就像下面这样:
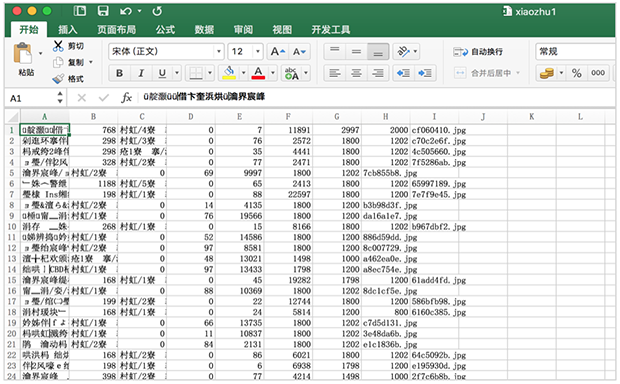
Excel 打开 CSV 出现乱码怎么办?
- 在记事本中打开文件
- 另存为 – 选择编码为“ANSI”
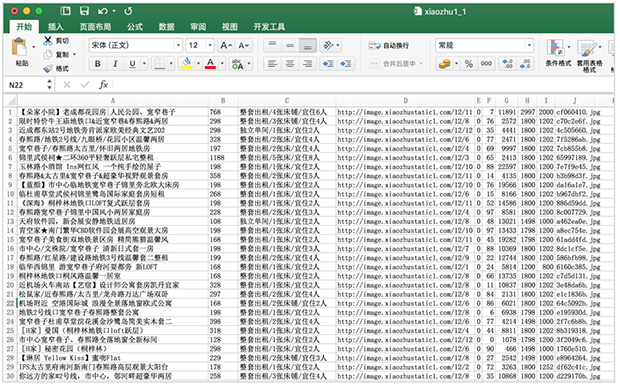
再来看看之前的豆瓣TOP250图书写入文件:
from lxml import etree
import requests
import time
with open('/Users/mac/Desktop/top250.csv','w',encoding='utf-8') as f:
for a in range(10):
url = 'https://book.douban.com/top250?start={}'.format(a*25)
data = requests.get(url).text
s=etree.HTML(data)
file=s.xpath('//*[@id="content"]/div/div[1]/div/table')
time.sleep(3)
for div in file:
title = div.xpath("./tr/td[2]/div[1]/a/@title")[0]
href = div.xpath("./tr/td[2]/div[1]/a/@href")[0]
score=div.xpath("./tr/td[2]/div[2]/span[2]/text()")[0]
num=div.xpath("./tr/td[2]/div[2]/span[3]/text()")[0].strip("(").strip().strip(")").strip()
scrible=div.xpath("./tr/td[2]/p[2]/span/text()")
if len(scrible) > 0:
f.write("{},{},{},{},{}\n".format(title,href,score,num,scrible[0]))
else:
f.write("{},{},{},{}\n".format(title,href,score,num))
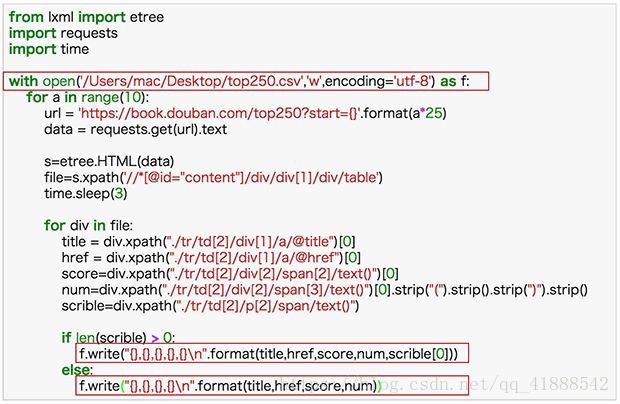
最后存下来的数据是这样的:

好了,这节分享就到这里!喜欢Python并且想要学习Python的同学可以加下我的Python学习交流群:663033228