MongoDB:
1. 什么是MongoDB
MongoDB是一个高性能,开源,无模式的文档型数据库
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成
2. MongoDB相关的安装
Mac OS 安装MongoDB:
官网下载:https://www.mongodb.com/download-center#community
将下载的安装包剪切到/usr/local后,终端 cd /usr/local,
解压:sudo tar -zxvf mongodb-osx-x86_64-3.4.2.tgz
重命名目录:sudo mv mongodb-osx-x86_64-3.4.2 mongodb
安装完成后,我们可以把 MongoDB 的二进制命令文件目录(安装目录/bin)添加到 PATH 路径中:export PATH=/usr/local/mongodb/bin:$PATH
3. 运行MongoDB
创建一个数据库存储目录 /data/db:sudo mkdir -p /data/db启动:sudo mongod
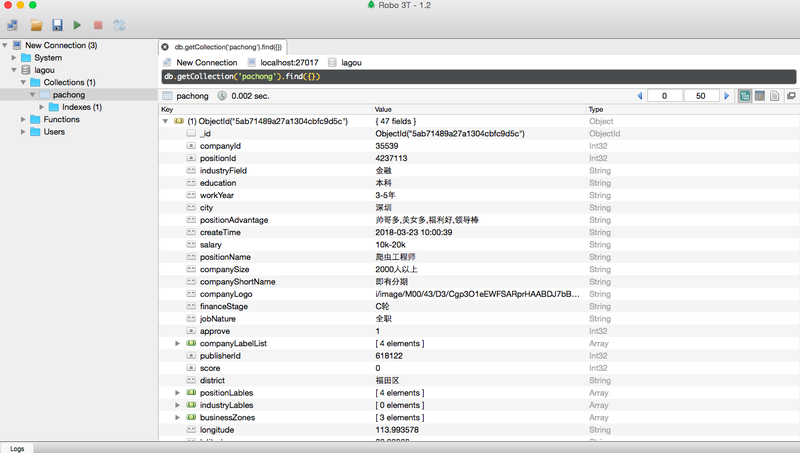
下载安装Robomongo(mongodb的可视化工具):
实战环节
爬取拉勾网有关“爬虫”的职位信息,并把爬取的数据存储在MongoDB数据库中
- 首先前往拉勾网“爬虫”职位相关页面
- 确定网页的加载方式是JavaScript加载
- 通过谷歌浏览器开发者工具分析和寻找网页的真实请求,确定真实数据在position.Ajax开头的链接里,请求方式是POST
- 使用requests的post方法获取数据,发现并没有返回想要的数据,说明需要加上headers
- 加上headers的’Cookie’,’User-Agent’,’Referer’等信息,成功返回数据
- 再把返回的对应数据存储到MongoDB
1. 爬取单页数据
import requests
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0'
payload = {
'first':'false',
'pn':'1',
'kd':'爬虫',
}
headers = {
'Cookie':'JSESSIONID=ABAAABAABEEAAJA056CAD85932E542C97E3C75AC57647E4; _ga=GA1.2.302262330.1521882979; _gid=GA1.2.2071000378.1521882979; index_location_city=%E6%B7%B1%E5%9C%B3; user_trace_token=20180324171739-00a5a016-8463-4097-a1b7-835ab1dcdc77; LGSID=20180324171824-4ddbb0d9-2f44-11e8-b606-5254005c3644; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fzhaopin%2F; LGUID=20180324171824-4ddbb39e-2f44-11e8-b606-5254005c3644; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1521883105; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1521883519; LGRID=20180324172522-4700c949-2f45-11e8-9b5d-525400f775ce; SEARCH_ID=1473baba22fb4fedbd4b4fdec0fd70bc',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36',
'Referer':'https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB?city=%E6%B7%B1%E5%9C%B3&cl=false&fromSearch=true&labelWords=&suginput=',
}
response = requests.post(url, data = payload, headers = headers)
print(response.json()['content']['positionResult']['result'])定义一个函数爬取多页的数据;使用fake-Agent包随机选取User-Agent
from pymongo import MongoClient
import requests
from fake_useragent import UserAgent
import time
client = MongoClient()
db = client.lagou
lagou = db.pachong
def get_job_info(page, keyword):
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false&isSchoolJob=0'
headers = {
'Cookie':'JSESSIONID=ABAAABAABEEAAJA056CAD85932E542C97E3C75AC57647E4; _ga=GA1.2.302262330.1521882979; _gid=GA1.2.2071000378.1521882979; index_location_city=%E6%B7%B1%E5%9C%B3; user_trace_token=20180324171739-00a5a016-8463-4097-a1b7-835ab1dcdc77; LGSID=20180324171824-4ddbb0d9-2f44-11e8-b606-5254005c3644; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fzhaopin%2F; LGUID=20180324171824-4ddbb39e-2f44-11e8-b606-5254005c3644; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1521883105; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1521883519; LGRID=20180324172522-4700c949-2f45-11e8-9b5d-525400f775ce; SEARCH_ID=1473baba22fb4fedbd4b4fdec0fd70bc',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36',
'Referer':'https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB?city=%E6%B7%B1%E5%9C%B3&cl=false&fromSearch=true&labelWords=&suginput=',
}
for i in range(1, page+1):
payload = {
'first': 'false',
'pn': i,
'kd': keyword,
}
useragent = UserAgent()
headers['User-Agent'] = useragent.random
response = requests.post(url, data = payload, headers = headers)
print('正在爬取第' + str(i) + '页的数据')
if response.status_code == 200:
job_json = response.json()['content']['positionResult']['result']
lagou.insert(job_json)
else:
print('Something Wrong!')
time.sleep(3)
if __name__ == '__main__':
get_job_info(3, '爬虫')