平常的过,再过几分钟就25岁了,不知道怎么捕捉这个时刻,越来越喜欢孤独的感觉,常哭,常生气,希望未来的人会出现吧,真的要长大了
–槛外人–
Abstract
随机的数据扩增对于网络训练很重要,以前的方法是数据扩增和网络训练是分开的,本文设计一种自动的扩增网络来产生hard的样本扩增,augmentation网络探索了target(hourglass)网络的弱点,target网络从hard样本中去实现更加优越的性能,作者设计了reward/penalty机制来方便网络的joint训练
Introduction
传统的数据扩增的弱点
- 整个训练集采取一套的扩增参数
- 随机的数据扩增不能跟踪训练的动态分布
- 不能解决长尾巴问题,对于那些很少出现但很有用的扩增获得他的概率很小
Contribution(和论文里的不太一样)
- augmentation网络用来生成对抗分布,从对抗分布中采样
- 提出了新的reward/penalty的机制保证joint训练的顺利进行
- augmentation网络的输入不是图片奥,是houglass网络的bridged特征
- hourglass网络用来做判别网络
Adversarial Human Pose Estimation
augmentation网络用来产生使hourglass(判别器)损失增加的‘hard’ augmentation,pose Network也即hourglass用来从对抗扩增的数据中进行网络的学习,并且评估生成的样本的质量好坏(评估结果是通过reward/penalty进行反馈的)
数据扩增有随机扩增
和对抗扩增
两种,判别器网络优化的目的就是让对抗扩增产生的损失大于随机扩增产生的损失,这样才能挖掘到hard的样本,优化式子如下,很平常的优化
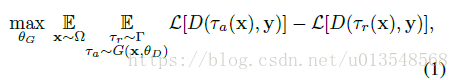
是训练图片集,y是图像标注,
用来强调G的产生受到了target网络(hourglass)D的影响和输入的影响
判别器的目的:
- 评估生成的样本的质量好坏
- 从对抗扩增的样本中去学习网络
上式代表普通的hourglass损失
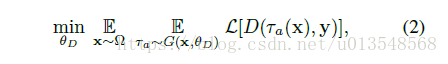
Joint Traing
从D返回到G如何能够反向传播是很重要的,因此作者采取了新的reward/penalty来实现这一功能。这里的G是生成一种分布,而不是直接的去生成新的扩增样本,通过从distributions采样,生成器能避免产生upside-down的扩增,防止陷入局部极小
Details
Augmentation网络
Augmentation网络用U-net的bridged特征作为输入,如图
预训练
ASR预训练
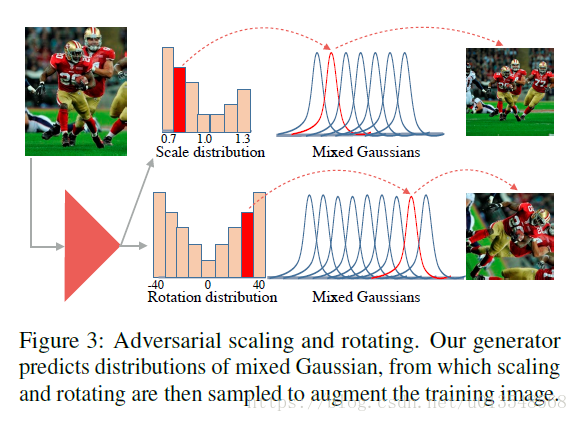
ASR网络用来产生扩增网络的尺度和旋转角度,那么怎么产生呢?作者力求产生一种分布。首先作者设计了7中尺度和9中旋转角度,组成7+9=16个bins,每个bin都是一个窄高斯。也就是说对于一张图片扩增方案就有63种(实则无数种)。
作者将一个batch的图片送入到ASR中,然后将图片进行63中扩增,每一种扩增都来计算损失,这样就会形成63个损失,将这63个损失进行归一化为1,对行,列分别归一化后会产生两个分布:
,
用这两个分布去做gt
网络会预测产生一个分布
,
,网络优化的目的就是使得学习出来的分布尽量符合gt的分布,优化式子如下
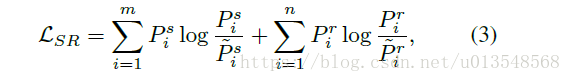
然后前向送入target网络的时候需要根据学习出来的分布采样,但是呢作者并不是只用这63中,作者首先会根据尺度分布,选择一种尺度,在该尺度下的高斯分布(上面提到的窄高斯bin)进行采样,获得一个采样尺度;对于产生的角度分布,作者首先根据分布抽样选择一个旋转角度,然后在该旋转角度对应的高斯分布下采样,获得一个采样的旋转角度。
这样做的好处是
- 引入更多的不确定性
- 在joint训练的时候没有标签,可以缓解这一问题???????
AHO pretraining
AHO的部分是生成随机遮挡的,但是他不是对原图进行随机遮挡,而是对特征图进行随机遮挡,仅仅在最低的尺度4x4下生成遮挡,其余尺度下的遮挡由4x4采样获得,这是一种方式吧,网络输入也是bridged特征
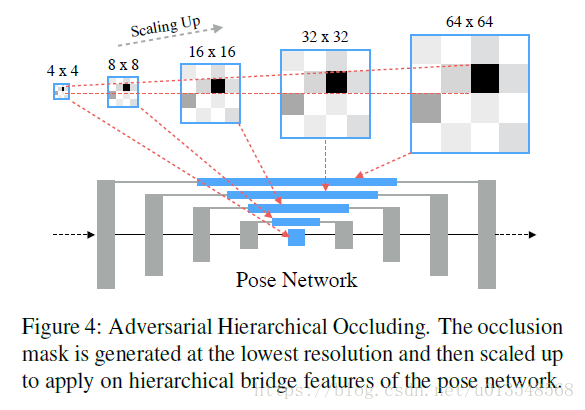
对于AHO的预训练和前面不同,首先作者会统计所有图像(这里不知道是所有图像还是一个batch的图像???)的每个关键点落在4x4的格子中的概率来看落在那个格子的概率大,将这个概率分布作为gt。然后进行训练,目标是使得AHO的输出尽量的接近gt分布
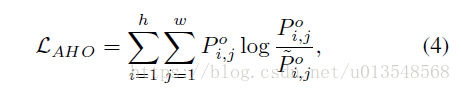
是预测出来的分布,网络根据这个分布选取1~2个格子以示忽略,也就是遮挡,然后送入到hourglass网络里面
联合训练
将ASR,AHO,D一起训练是比较困哪的
首先如果在联合训练时仍然按照预训练的方式训练ASR和AHO,那么网络会十分十分的慢且低效(要不断的生成分布的gt哇),如果不按照预训练的方式训练又会缺少标签,所以怎么办呢?
作者设计了reward/penalty,用对抗扩增出来的数据的损失和同一张图片经过随机扩增获得的损失做差,对抗出来的样本的损失减去随机扩增获得的损失越大的话,表明生成的样本有效,此时就会对这一采样的概率加大,对其他的削弱,反之亦然

这样的话网络就会产生损失,同时可导,将D的信息反馈到augmentation网络
如果将ASR和AHO一起训练的话,会很困难,因此作者对于一个patch的图像分为了等量的好几部分,一部分用来学习D,一部分用来学习ASR,一部分用来学习AHO


整个网络的学习是交替的,先学 D,然后是ASR和AHO
Result Analysis
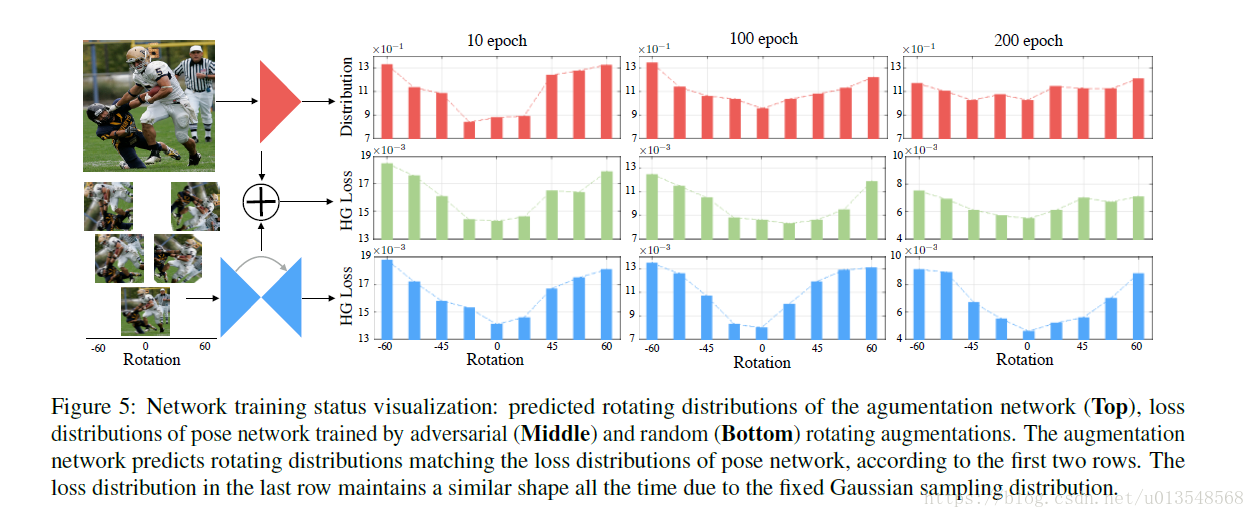
以尺度为例,生成器生成的尺度分布近似的等同于用生成的样本送入到hourglass网络产生的损失分布,根据损失来确定每种采样的扩增比重