Boundary Flow: A Siamese Network that Predicts Boundary Motion without Training on Motion
(边界流:一种在没有基于运动训练的情况下预测边界运动的孪生网络)文章看这里
不知道Siamese Network(孪生网络)是什么的同学请将这两个词复制一下,问问度娘~推荐
摘要
本文通过深度学习解决了视频中联合对象边界检测和边界运动估计的问题,并将之称之为边界流估计。边界流是一个重要的中级视觉线索,因为边界表征了物体的空间范围,流动表明了物体的运动和相互作用。然而,先前大多数关于运动估计的工作都集中在密集的对象运动或可能不位于边界上的特征点。对于边界流估计,我们提出一个新的全卷积孪生网络(FCSN),它联合估计两个连续帧中的对象级边界。两帧中的边界对应由相同的FCSN用新的非常规反卷积方法预测。最后,通过基于边缘的滤波来改进边界流估计。本文对三个任务进行评估:视频中的边界检测,边界流估计和光流估计。在边界检测方面,我们在基准VSB100数据集上实现了最先进的性能。在边界流量估计上,我们在Sintel训练数据集上提出了第一个结果。对于光流估计,我们运行最近的方法CPM-Flow,但是使用我们的边界流匹配增强输入,并在Sintel基准上实现显着的性能改进。
引言
- 关键的挑战是共享边界的不同表面随着不同的运动,平面外旋转和变化的遮挡而移动。这使得沿着边界的外观在连续帧中可能不一致。当沿边界的多个点具有相似的外观时,在两个图像中匹配边界的难度也增加。
- 我们的关键假设是,由于沿着边界的丰富的视觉线索,边界流可以在没有像素级运动注释的情况下学习,这通常很难得到(先前的工作模拟[24]或计算机图形[8],可能不代表真实的图像)。
- 本文首次在深度学习框架中考虑边界流估计的问题,给出边界流的严格定义,并提出和广泛评估了用于解决该问题的新的深度架构FCSN。本文还证明了边界流用于估算密集光流的有效性。
- 本文提出了一种新方法,从FCSN生成基于激励的对应分数用于边界匹配,并开发基于边缘的匹配,用于精细化相应边界的点匹配。
- 本文改进了最新的时空边界检测技术,提供了边界流估计的第一个结果,并在与CPM-Flow集成时实现了对密集光流的较大改进。
- 本文主要框架如下图所示。由两部分构成,首先FCSN将两个连续的视频帧编码为粗略关节特征表示(JFR)(在下图中标记为绿色立方体)。然后,一个孪生解码器使用反卷积和非最大池来估计两个输入图像中的每一个的边界。孪生网络能够预测两帧中不同(但正确)的边界,而两个解码器分支的唯一区别是最大池化索引。因此,本文的关键直觉是每个边缘的JFR层必须有一个共同的边缘表示,它通过不同的最大集合索引映射到两个不同的边界预测。
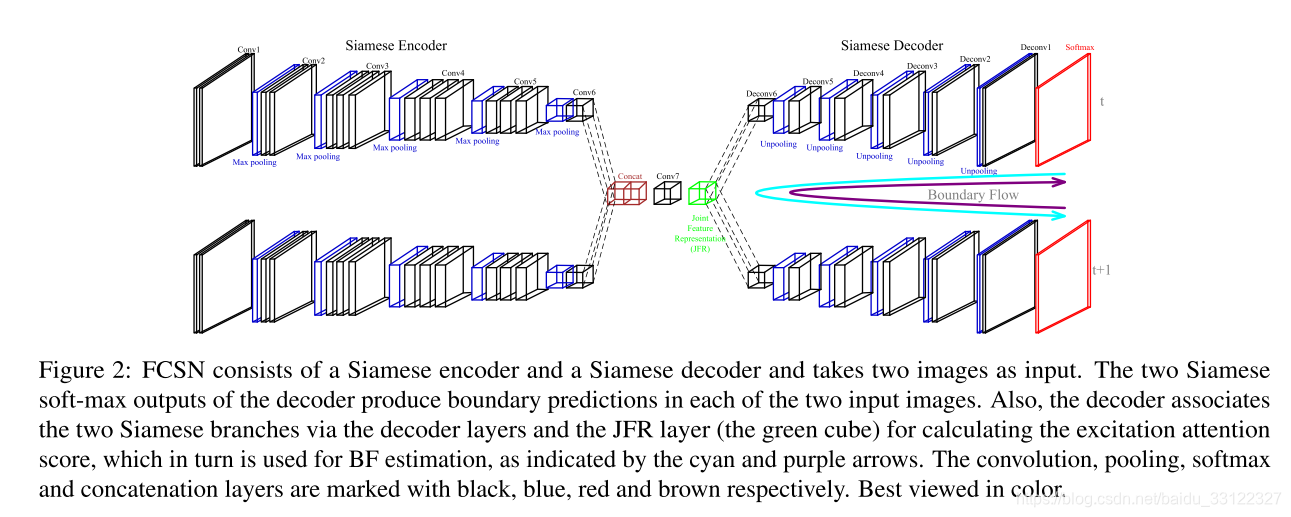
Fully Convolutional Siamese Network(FCSN,全卷积孪生网络)由两部分组成,一个孪生编码器(Siamese encoder)和一个孪生解码器(Siamese decoder)。其中编码器存储所有池化层的索引,同时通过一系列的卷积、ReLU和池化层将两帧图像编码为joint feature representation(JFR,联合特征表示)。两帧图像的编码器输出结果以通道方式连接,然后作为解码器的输入。解码器将JFR和编码器中的最大池化索引一起作为输入,最后,解码器输出的特征被传递到一个softmax层以获得两幅图像中每一个像素的边界标记。
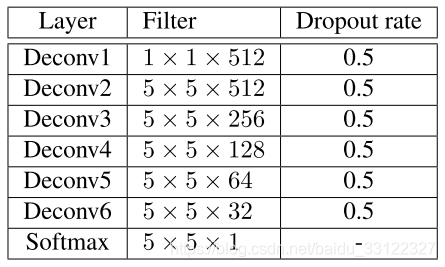
编码器和解码器的两条分支共同使用相同的结构和相同的权重。然而,对于两个不同的输入图像,这两条分支依然输出不同的预测图,因为解码器的预测是用记录在其相应的编码器分支中不同的池化索引来调制的。每条编码器分支使用VGG结构。解码器通过一系列unpooling(反池化)、反卷积、ReLU和dropout操作将JFR解码至原图大小。一般的反卷积网络使用一个与编码器对称的解码器,而本文与此不同,本文设计了一种轻量级解码器,其重量参数比对称结构更少,效率更高。本文解码器中,处理softmax层之前的那层,其它所有的卷积层后面都跟随着一个ReLU操作和dropout层。FCSN解码器网络结构设计如下图所示。
Excitation Attention Score (激励注意力得分)
首先边界流(BF)估计的核心问题为识别一对边界点
之间的对应关系。本文的主要想法就是通过计算帧t中每个边界点
在帧t+1中的激励注意力分数以及计算帧t+1中每个边界点
在帧t中的激励注意力分数,来估计两帧图片中边界点的对应关系。本文使用excitation backpropagation (ExcitationBP) 来有效的生成激励注意力分数。ExcitationBP是一种概率性的赢家通吃方法,通过神经网络的卷积层来模拟神经激活的依赖性,以识别用于预测的相关神经元,即注意力图。
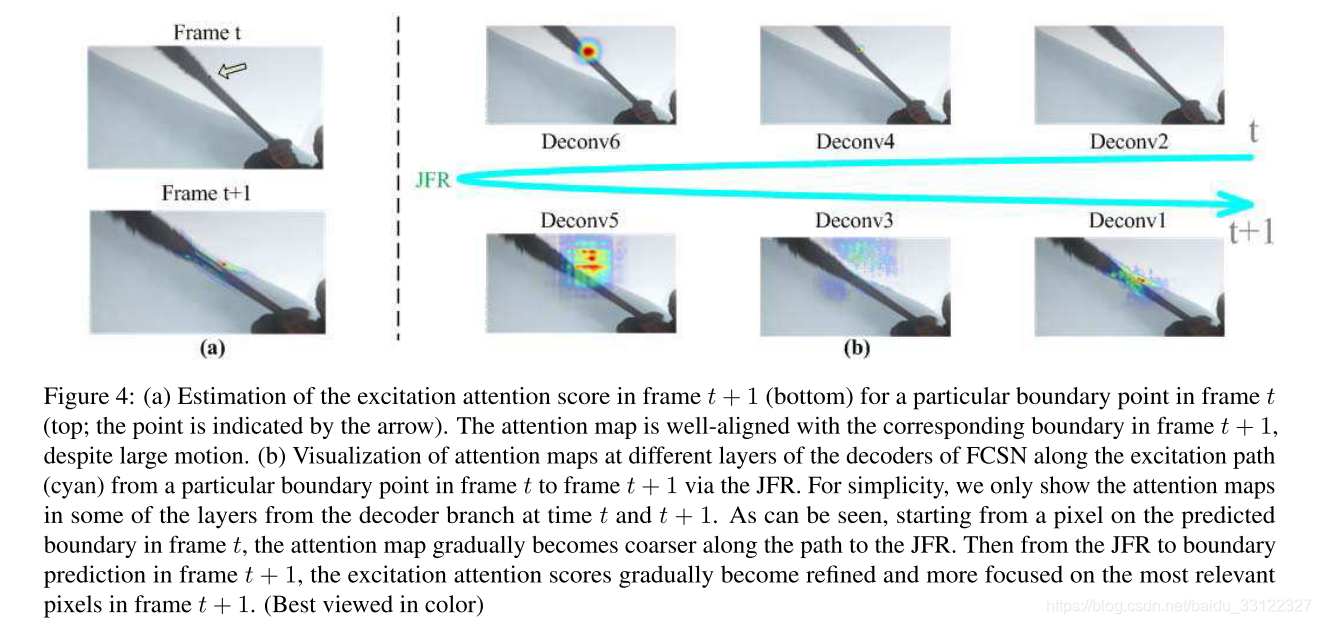
该方法背后的直觉是JFR存储两个图像的两个相应边界的联合表示,因此可以用作匹配它们的“桥”。通过沿着从解码器的一个分支通过JFR层到另一个分支的路径来跟踪最相关的神经元来建立该“桥”(第一幅图中的青色和紫色箭头)。
本文的方法基于条件获胜概率,从帧t通过JFR到帧t+1的路径上的每个层按顺序地采集获胜神经元。每个神经元的相关性被定义为被选为路径上的胜利者的概率。神经元获胜概率定义公式如下:(没看太懂,感兴趣者可以详细看论文)
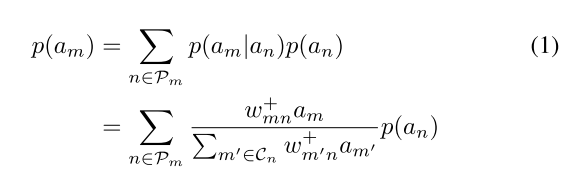
ExcitationBP能够有效识别哪些神经元负责最终预测。在本文的方法中,Exci-tionBP可以并行的运行于预测边界的每个边缘。从第t帧中的边界预测图开始到JFR,我们沿着这条路径计算所有神经元的边际获胜概率。一旦达到JFR,就在FCSN的解码器分支中前向传播这些概率,以最终估计帧t+1中的逐个像素激励注意分数。从而获得一对边界点的注意分数
。相反,从第t+1帧的边界预测开始到JFR,我们沿着这条路径计算所有神经元的边际获胜概率,并通过解码器向前馈送它们以计算帧t中的激发注意力图,从而获得注意力得分
。一对边界点的注意力得分
被定义为
和
的平均值。ExcitationBP的示例如下图。
Edgelet-based Matching (基于边缘的匹配)
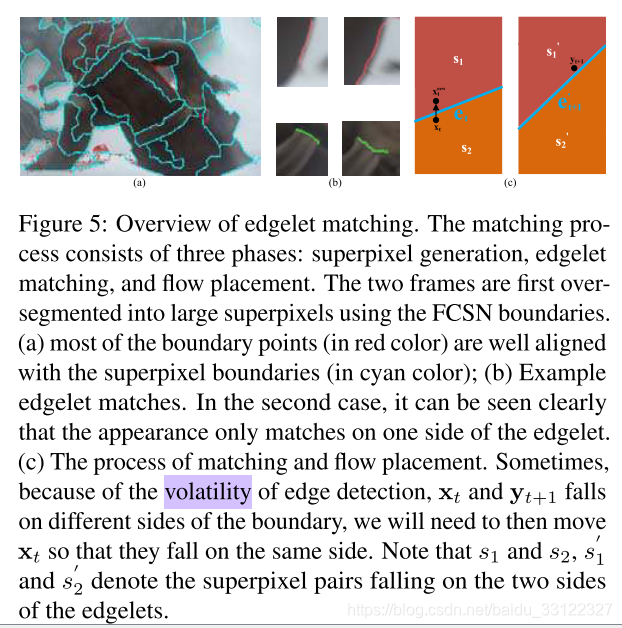
该论文提出了更加精细化的边界匹配算法,主要分为三个部分,超像素生成,小边缘匹配和流定位。首先粘性超像素来对两个帧的预测边界进行超细分,并将超像素合并到更大的区域。然后将基于边缘的匹配应用于边缘对,这一步中先是利用之前得到的像素对之间的注意力分数来表征边缘之间的相似性,得到前10个最相似的边缘对,然后按法线进行过滤,即判断边缘对的角度相差不高于45度,之后利用贪婪匹配算法来近似边缘的二分匹配,对边缘对进行进一步的筛选。最后,进行边界流定位,文中提到由于边缘检测的volatility(挥发性),可能一些边界点会被错误的放置在边缘的另一边,导致两幅图像对应的边界点被放置在边缘的不同侧,因此本文利用由颜色定义的归一化区域相似性来将运动分配给在颜色上彼此更相似的超像素对,即将分配错误的一点运动至另一边去。
好了,本片论文导读到此结束,有兴趣者可以自己去细读论文,基本上不难读懂,祝各位好运~
PS:文中作者虽然写了源码是用caffe写的,但是好像没有公布源码链接。嗯。。。之前看到一句话我觉得很有道理,不公布源码的论文都是在耍流氓。