摘要
本文介绍了一种在训练CNN时使用的数据增强方法:随即擦除。它在训练时使用随机值随机地擦除掉图像的一块矩形范围。这能够帮助模型减少过拟合,以及在面对遮挡现象时更为健壮。它无需学习参数,容易实现,且可以应用到许多基于CNN的识别模型上。同时,它与其它的数据增强方法能够互相补充。
介绍
众所周知,CNN有着非常强大的功能,但当它的结构过于复杂时,往往就会出现过拟合的现象。这就导致了,模型可能会在训练时表现出很高的准确率,但却在测试时效果很差。为了提高模型的预测能力,人们提出了很多数据增强的方法。
遮挡是影响CNN泛化能力的一个重要因素。理想的情况是,无论遮挡的情况有多严重,模型都能够很好地识别出目标物体。但实际上,如果不在训练时加入被遮挡的样本,那么在面对被遮挡的测试样本时,模型的识别能力就会下降。为了解决这个问题,一个直观的做法是:在训练样本中加入别的图片作为遮挡物。但这种做法的问题是,它会耗费太多的资源,且对遮挡的图片也有一定的要求。
为了解决这个问题,作者提出了一种新的数据增强方法:随即擦除。它可以很容易地应用在大多数现存的CNN模型中。
随即擦除的基本原理是,在训练时,随机地对图片进行以下两种操作之一:1、什么也不做;2、在图像的任一位置上选择一个随机大小的矩形区域,并赋给这个区域以随机值或选取的数据集的平均值。
与其它两种常见的数据增强方法,水平翻转和cropping,相比,随即擦除导致了数据损失,且保留了图像的结构信息。同时,它被擦除的区域获得了新的值,因此可以被视作在图像中加入了块状的噪音。
随即擦除和dropout也很像,但它们的区别在于:1、随即擦除擦除的是连续的像素,而非单个像素;2、随即擦除并不丢弃像素;3、随即擦除的目的是增强模型对噪音和遮挡的健壮性。
算法
首先,作者设定一幅图片被随机擦除的概率是p。
随后,作者设Ie为要擦除的区域。若训练数据的面积为S=W*H,作者将被擦除的区域的面积初始化为Se,其中Se/S的值位于被指定的sl和sh之间。随机擦除区域的长宽比例由r1和r2间的随机值确定,作者将其设为re。Ie的长为
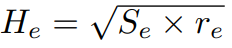
宽为
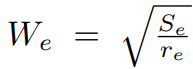
随后,作者在图像上随机地找一个点P=(xe,ye),若xe+We≤W且ye+He≤H,则Ie=(xe,ye,xe+We,ye+We)。否则重新进行以上流程,直到选到合适的Ie。其伪代码如下:

