版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/liangdong2014/article/details/85244265
Background
- 存在什么问题?
- 训练深度神经网络是比较复杂的,因为每层输入的分布在训练过程中都在变化。如果每层输入的分布在不停的变化,那我们就需要不停的调整我们的参数去补偿这部分变化,这就使得训练过程更加缓慢。
- 此外,由于分布的变化使得使用saturating nonlinearity function变得更加难以训练。
- 首先我们区分什么是saturating,什么是non-saturating
- non-saturating:如果一个函数 或者是 则 是non-saturating的。比如,ReLU
- saturating:如果函数 不是non-saturating,则他就是saturating。比如,sigmoid
- 接下来,为什么saturating nonlinearity 难以训练?因为他会面临梯度消失问题。
- 考虑以sigmoid为激活函数的一层。 。
- 当我们 增长的时候,我们 趋近于0。这时候就可能会出现梯度消失问题。
- 但是 又被 和之前layer的参数影响,所以有很大可能性梯度会比较小。
- 首先我们区分什么是saturating,什么是non-saturating
- 现存的有什么解决方法?
- 数据分布—白化操作,PCA Whitening
- 我们可以在每一层输入之前都使用白化操作将数据映射到0为中心, 不同特征之间具有相同方差的空间。
- 但是这样操作计算量很大,并且有时候是不可导的。因为在计算PCA Whitening的过程中,我们需要计算协方差矩阵 ,然后再进行特征值分解。这样提取得到了特征之间无关(decorrelated)的新特征向量空间。
- 所以,目前我们一般只在预处理阶段使用白化操作。
- non-saturating nonlinearity—ReLU
- 上面提到,我们使用saturating nonlinearity会导致梯度消失的问题,所以我们可以使用non-saturating nonlinearity来代替saturating nonlinearity。但是这样并没有从本质上改变数据的分布。我们还是要调整parameter来补偿输入分布的变化,这就使得我们的训练更慢。
- 数据分布—白化操作,PCA Whitening
Method
- 为了normalized 数据分布,并且简化计算,使得处处可导。相对于PCA计算向量不同纬度之间的correlation,Batch Normalization 单独normalized 特征向量的每个纬度。这是Batch Normalization和PCA 白化的一个重要不同。
- LeCun et al.提出了 ,但是只使用这个可能会降低模型的表达能力。比如说我们使用non-linear的sigmoid,在输入之前经过这个transform处理后,会使得我们的sigmoid有点趋近于linear的transform。
- 为了解决该问题,作者定义了 , 来强化模型的表达能力。
- 总结一下,在训练过程中,我们使用如下的流程来计算normalization。

- 此外,作者也给出了反向传播的公式,如下所示。
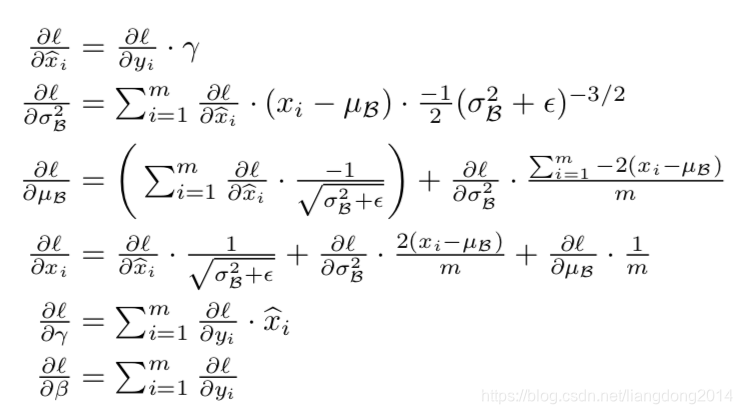
- 上面描述了在训练阶段normalization的过程。但是在测试(inference)阶段我们应该怎么处理呢?关键在于怎么计算 ,我们知道在训练阶段我们通过减去batch 内的均值除以方差可以得到 ,但是在测试阶段我们没有batch,或者batch的分布和训练时候不一样。那么我们怎么处理呢?作者提出了同样的处理方式 ,不过 无偏估计量来表示。然后再 。
- 此外还有以下几点需要注意
- 文中说为了避免saturating 激活函数的梯度消失问题,BN一般放在激活函数之前
- 和 是针对每一个特征有一对。比如说我们通过全连接层的输出是512纬的,那么BN层就有512对 和 。针对卷积层的情况, 和 也是针对每一个特征有一对。假设说我们Convolutional layer的输出是 ,那么BN层就有512对 和 。不过计算均值 的 就变成了 。用原文中的话就是We learn a pair of parameters and for per feature map.