FLAG
Kong K, Li G, Ding M, et al. Flag: Adversarial data augmentation for graph neural networks[J]. arXiv preprint arXiv:2010.09891, 2020.
本文主要是提出了GNN的数据增强方法——FLAG,在增强模型鲁棒性的同时,研究其对模型准确率的影响。
我将FLAG方法也运用到了我自己设计的模型当中,在减少标准差的同时也让模型的准确率有了小幅度的提升。此外,FLAG方法使用起来灵活方便,以后的应用应该会十分的广泛。
问题的提出
OGB数据集是一个真实且大型的图数据集,它的出现给GNN带来了不小的挑战,很多模型都会在OGB数据集上出现overfit的情况,也就导致了acc一直上不去。
每当GNN发生一些问题,我们总是会去借鉴CNN中的一些策略。那么,CV中如何去缓解overfit呢?——就是采样数据增强(data augmentation)的方法。自然而然的就会想到,我们可不可以把数据增强推广到GNN上。
当然,很多人都针对GNN的数据增强提出了自己的观点。以往的观点关注的是图结构,一般是采用DropoutEdge的方法去进行正则化,以达到数据增强的效果。但是,也暴露出了灵活性、通用性、易用性、有效性等弊端。而本文主要是关注针对节点特征空间的数据增强方法。
提到节点特征空间,其他领域内很多都是采用对抗性数据增强的方法。它是通过对抗性扰动来增强数据并最终缓解overfit的。虽然它能够增强模型的鲁棒性,但是往往是以牺牲acc为代价的,如何在这种情况下提高acc,成为了一个需要研究的问题。
FLAG方法
FLAG(Free Large-scale Adversarial Augmentation on Graphs),是图上免费的大型对抗性数据增强方法,以缓解overfit。它主要是通过为输入节点特征增加基于梯度的对抗性扰动,来实现数据增强的。
FLAG方法的算法流程

算法思路详解:
其实弄明白之后发现其实思路和实现还是比较简单的。原来我们用SGD或Adam优化器来训练时,每个epoch就一次梯度下降、前向和反向传播,即N个epoch,每个epoch有1个SGD。现在FLAG方法的情况是,为了和之前的runtime大致相当,增加每个epoch中的PGD(投影梯度下降)次数,减少epoch,即N/M个epoch,每个epoch有M次PGD(当然也可以不减少epoch)。
在每个epoch中,我们首先定义一个和X形状相同且服从(-alpha, alpha)均匀分布的扰动矩阵pert,它带有梯度,然后作为扰动和X一起送入模型中训练M个step。在每个step中,我们根据pert的grad手动更新pert,然后清零pert的grad;每次都会得到loss所在的计算图的grad的1/M,不清零,将M次梯度进行累加。在M次step做完之后,统一对loss所在的计算图进行1次反向传播并更新参数。
更新pert的方法借鉴了对抗性训练的PGD方法,大家可以自己去阅读paper来感受。
FLAG方法的pytorch代码
# M as ascent steps, alpha as ascent step size
# X denotes input node features, y denotes labels
def flag(model, X, y, optimizer, criterion, M, alpha):
"""
model:模型
X:输入节点特征矩阵
y:节点标签
optimizer:优化器
criterion:损失函数
M:每个epoch的step数
alpha:每个step的步长
"""
model.train()
optimizer.zero_grad()
# pert初始化为和X形状相同、服从(-alpha, alpha)均匀分布的矩阵
pert = torch.FloatTensor(*X.shape).uniform_(-alpha, alpha)
# pert带有梯度
pert.requires_grad_()
# 为输入数据增加对抗性扰动pert
out = model(X+pert)
# 因为loss的梯度一直是累加的,所以每个step贡献1/M的grad值
loss = criterion(out, y)/M
# 每个epoch分为M个step,M个loss的grad进行累加,得到最终的loss
for _ in range(M-1):
loss.backward()
# 根据pert的grad来更新pert,alpha可以看作是pert的学习率
pert_data = pert.detach() + alpha*torch.sign(pert.grad.detach())
pert.data = pert_data.data
# pert梯度grad清零
pert.grad[:] = 0
# 重复对抗性扰动的训练过程
out = model(X+pert)
loss = criterion(out, y)/M
# 通过M个step累加的grad,更新model的参数
loss.backward()
optimizer.step()
代码也不长,并且灵活性也很好,根本不需要像其他一些方法一样动不动就去改动模型的结构或对输入数据进行调整。作为一个忠实的pytorch用户,拿过来就可以用,也可以说是十分的贴心了。
FLAG方法的例子
官方代码:https://github.com/devnkong/FLAG
我的model:https://github.com/ytchx1999/GCN_res-FLAG
实验验证
FLAG是一种简单、通用且高效的方法,它在OGB的很多数据集上都达到了最好的效果。
结合毕设,我主要关注的是引文网络的节点分类任务,重点关注的是ogbn-arxiv数据集的一些结果。有一个需要注意的是,FLAG对目标节点和未标记节点采用不同的步长alpha( α l \alpha_l αl 和 α u \alpha_u αu),不过在ogbn-arxiv中是相同的。
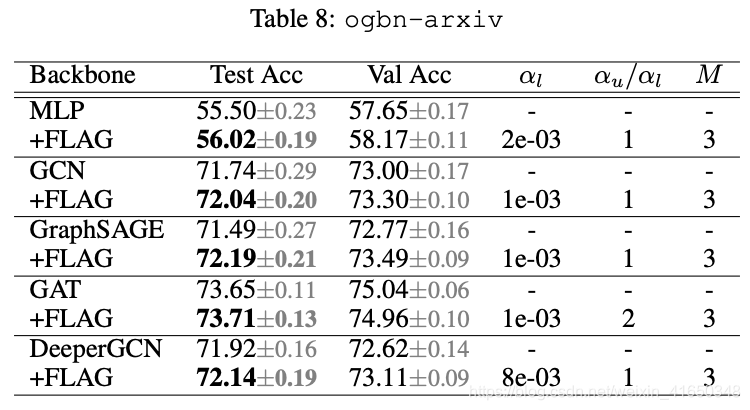
我自己的model进行实验也有类似的结果,说明FLAG方法还是相当靠谱的。

讨论与分析
- FLAG方法与BN、dropout等训练技巧一起使用会提高acc,进一步增强GNN模型。
- FLAG方法和其他数据增强方法相比,数据开销最小,训练成本比较低。
- FLAG方法在模型加深的时候,可以缓解过平滑问题。
- FLAG方法可以在minibatch算法中使用,也有很好的效果。
- FLAG方法可以增强模型的鲁棒性,这点毋庸置疑,但是是否能够提高acc,关键要看数据的分布。输入数据的分布不同,FLAG方法会有不同的表现。在ogbn-arxiv中可以很好地提高acc,但是在Cora中可能就会损害acc。
总结
使用FLAG方法可以提高GNN的泛化能力,可以改进很多GNN baseline。并且由于其高效性、低成本以及良好的扩展性,很多模型都可以直接使用,成为未来的一个研究方向。