【S2ST】Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation
Abstract
与自动语音识别 (ASR)、机器翻译 (MT) 和文本到语音 (TTS) 合成等传统级联系统可用的数据量相比,直接语音翻译 (S2ST) 模型存在数据稀缺问题。使用未标记的语音数据和数据增强进行自监督预训练来解决这个问题。得到了6.6-12.1 BLEU 的提升。
Introduction
直接的S2ST让数据短缺这个问题更为严重,本文应用了自监督预训练形式应用了大量的单语言的语音和文本,还将S2T中应用到的数据增强策略应用到了S2UT中。
System
框架图:
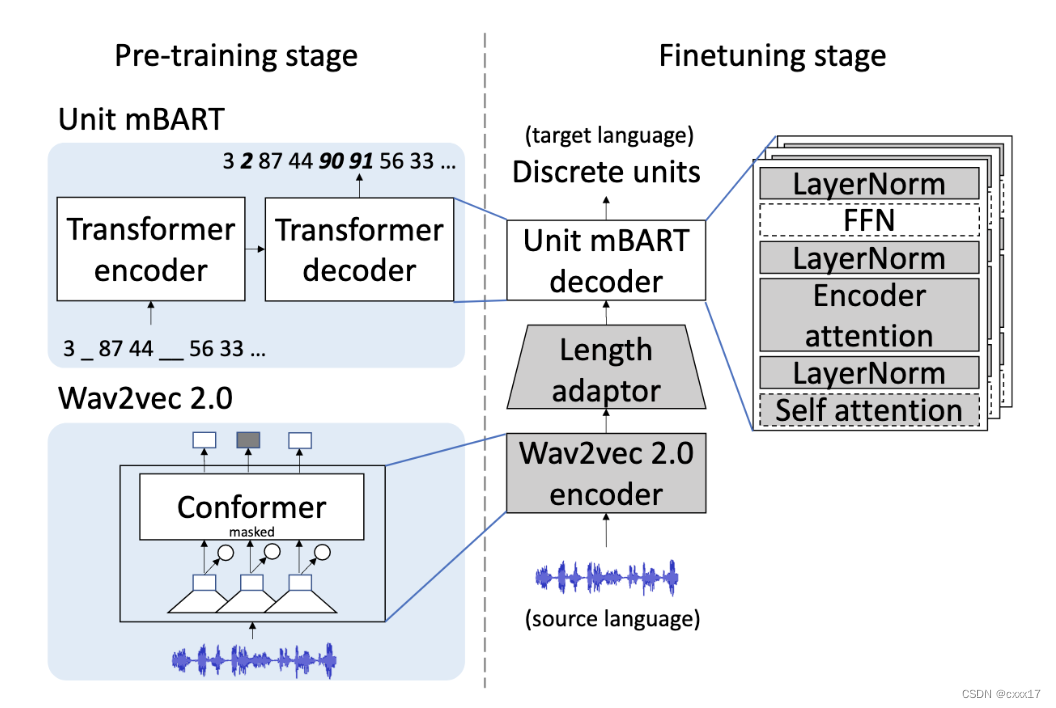
Speech-to-unit translation (S2UT) model
Follow “Direct Speech-to-Speech Translation With Discrete Units” 的方法,预测离散的units,直接的S2ST模型包括一个sequence-to-sequence的S2UT模型,以及一个unit HiFi-GAN vocoder。这篇工作中,探索了encoder和decoder的pretraining.
Model pre-training
Encoder pre-training: wav2vec 2.0
提取speech represention. Conformer-based wav2vec 2.0
Decoder pre-training: unit mBART
应用reduced dicrete units预训练mBART
Model finetuning
应用不同的finetune策略
- LNA-E
finetune: encoder的 LN 和 self.attention 参数, decoder所有参数 - LNA-D
finetune: decoder的 LN 和 self.attention 参数, encoder所有参数 - LNA-E,D
finetune: encoder, decoder的 LN 和 self.attention 参数, - Full
finetune: encoder, decoder所有参数
Data augmentation
应用MT模型,产生translation,再应用text->unit产生paired数据
Experiments
Data
Fisher, VoxPopuli
Model setup
多语言 HuBERT (mHuBERT) 模型、k-means 模型和基于单元的 HiFi-GAN 声码器,将目标语音编码为 1000 个单元的词汇表。
Baselines
2个cascaded baselines: ASR+MT+TTS, S2T+TTS
2个S2UT baselines:
Evaluation
SACREBLEU, MOS
Results
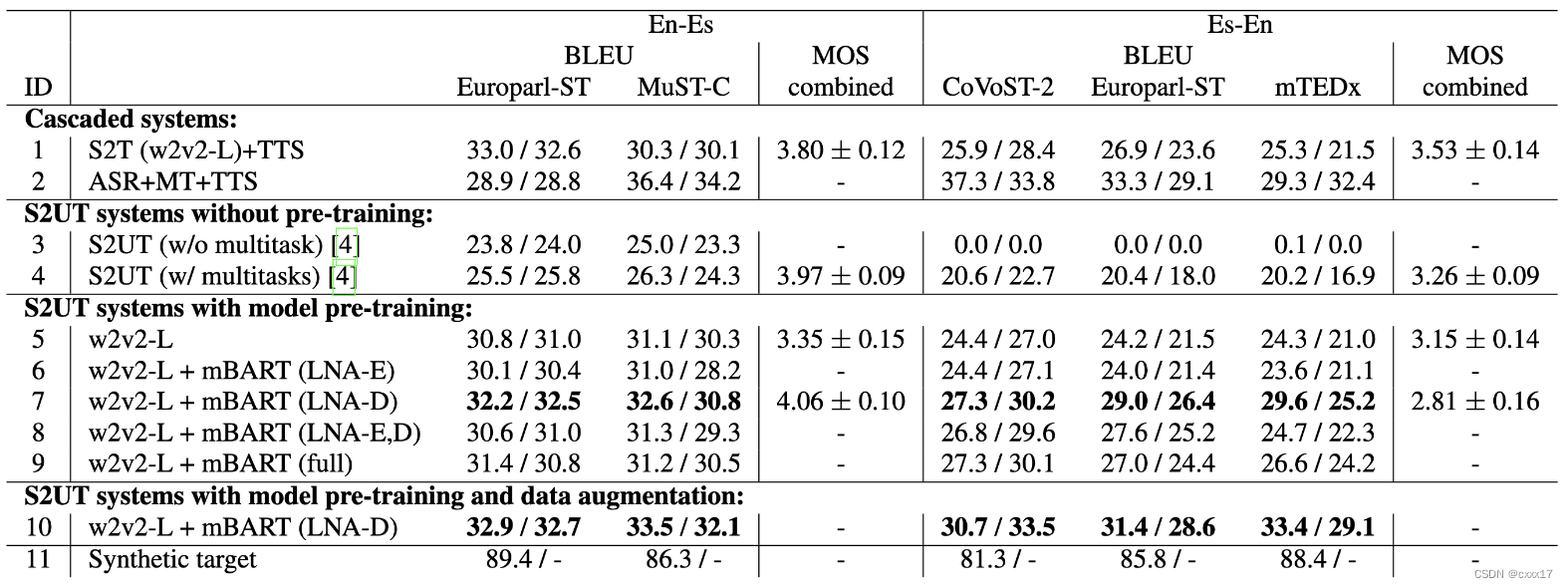
S2ST with model pre-training
-
BLUE
11 说明ASR导致的错误
4 vs. 5 pretraining encoder 平均提升了5.6 BLEU(en-es)和4.0 BLEU(es-en).
4 vs. 7 pretraining decoder 平均提升了6.6 BLEU(en-es)和8.1 BLEU(es-en).
本文最好的 EnEs S2ST 模型与 S2T+TTS 基线相当,Es-En S2ST 模型比级联系统高出 2.8 BLEU(1 vs 7)。
此外,结合来自 ASR 语音的弱监督训练数据可以在 En-Es 上带来 +0.7 BLEU,在 Es-En 上带来 +3.1 BLEU(7 vs 10)。 -
MOS
表明 En-Es S2UT 系统比 Es TTS 产生更自然的语音(1 vs 7),而 Es-En S2UT 输出的质量要差得多。请注意,输出语音的自然度主要由单元声码器控制,我们使用预训练的模型而不进行微调。 -
unwritern language
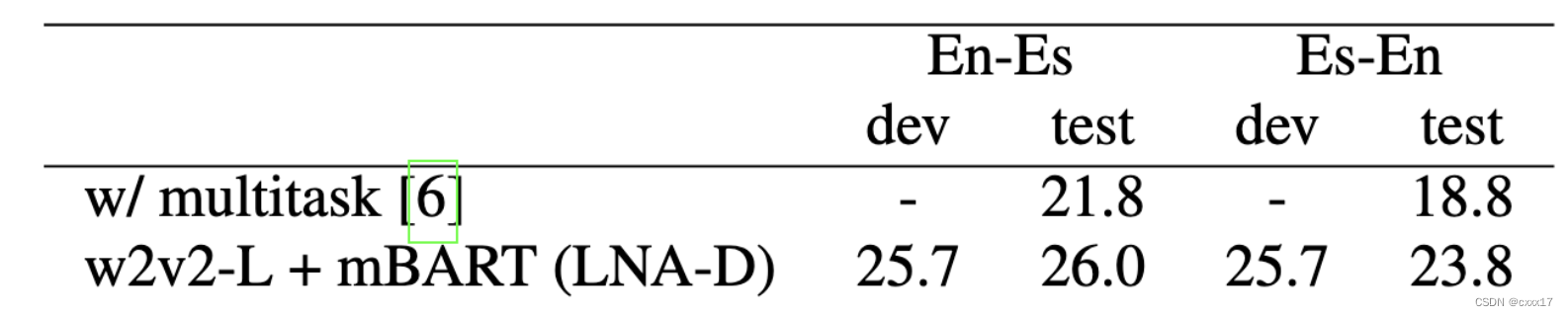
-
The data of pre-training
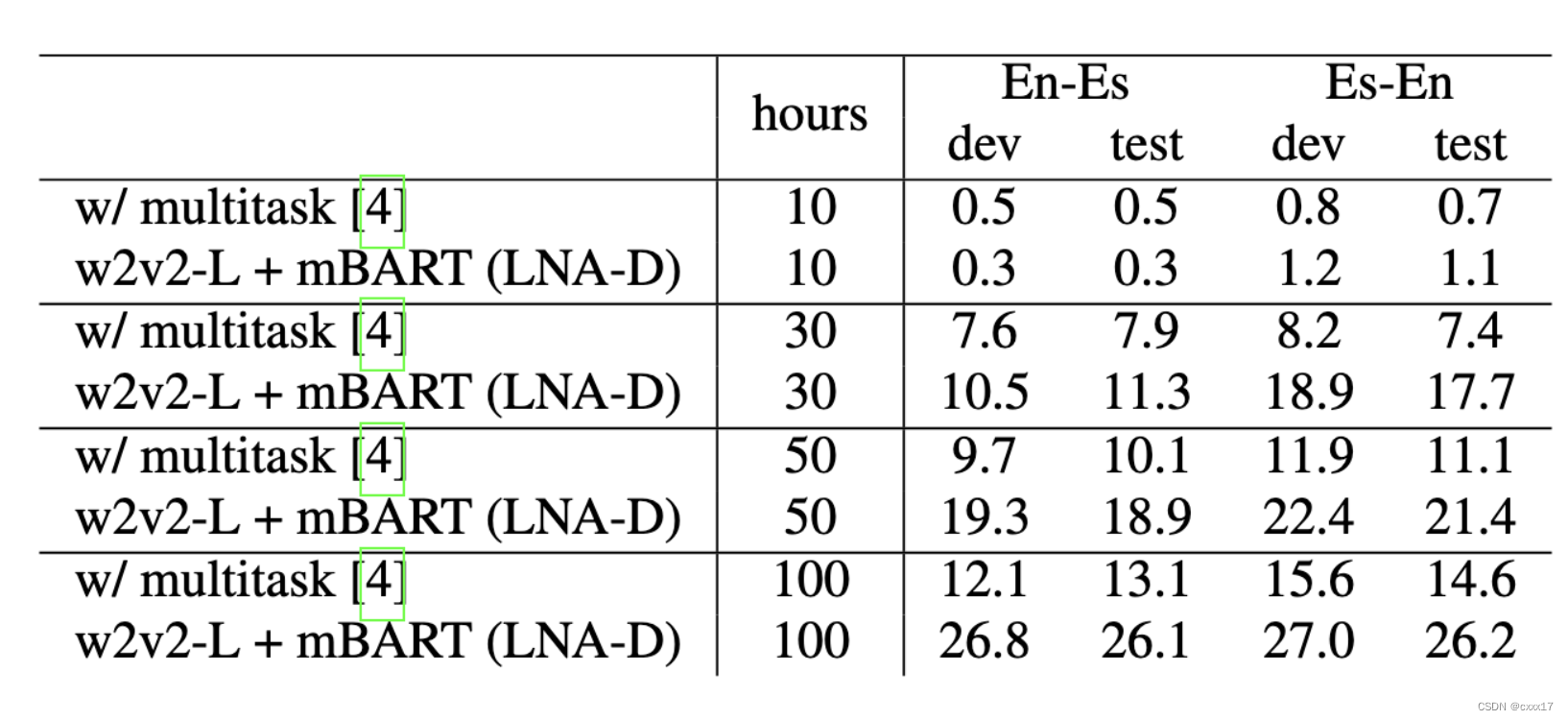
Model variations
- Conformer vs transformer wav2vec 2.0 (conformer +4.6 BLEU)
- mbart训练的超参
![[Image]](https://img-blog.csdnimg.cn/direct/4839a478c971482f8b7db83825a2011b.png)