文章目录
一.论文信息
论文题目: AugGPT: Leveraging XXX Transformer for Text Data Augmentation(AugGPT:利用XXX Transformer进行文本数据增强)
发表年份: 2023-arXiv
论文链接: https://arxiv.org/abs/2302.13007
作者信息: Haixing Dai*(美国佐治亚大学), Zhengliang Liu*, Wenxiong Liao*, Xiaoke Huang, Yihan Cao, Zihao Wu, Lin Zhao, Shaochen Xu, Wei Liu, Ninghao Liu, Sheng Li, Dajiang Zhu, Hongmin Cai, Lichao Sun, Quanzheng Li, Dinggang Shen, Tianming Liu, and Xiang Li
备注: 本文重点关注NLP领域数据增强的方法、作者实验的baseline模型、以及模型评估使用的指标,除此之外,本篇论文其余内容有机会再补充更新……
二.论文内容
摘要
在许多自然语言处理任务中,文本数据增强是克服有限样本挑战的有效策略。这一挑战在少样本学习场景中尤其突出,在这种场景中,目标域中的数据通常要少得多,质量也较低。缓解此类挑战的一个自然且广泛使用的策略是执行数据增强,以更好地捕捉数据不变性并增加样本大小。然而,现有的文本数据增强方法要么不能保证生成数据的正确标注(缺乏真实性),要么不能保证生成数据的足够多样性(缺乏紧凑性),或者两者兼有。受最近大型语言模型的成功,特别是XXX的发展的启发,本文提出了一种基于XXX的文本数据增强方法(AugGPT)。AugGPT将训练样本中的每个句子重新短语为多个概念相似但语义不同的样本。然后,增强后的样本可以用于下游模型训练。在小样本学习文本分类任务上的实验结果表明,与当前主流的文本数据增强方法相比,AugGPT方法在测试精度和增强样本分布方面具有更好的性能。
2.相关工作
2.1.数据增强
数据增强,即通过变换人工生成新文本,在文本分类中被广泛用于改进模型训练。在NLP中,现有的数据增强方法分不同的粒度级别:字符、单词、句子和文档。
字符级别的数据增强:
- 随机插入、交换、删除字符: 是指在文本中随机地插入、交换、替换或删除字符,以提高NLP模型对噪声的鲁棒性。
- 光学字符识别(OCR)的数据增强: 通过模拟使用OCR工具从图片中识别文本时发生的错误来生成新的文本。例如,使用OCR时,“0”(数字0)、“o”(小写欧)、“O”(大写欧)是很难区分的,所以可以模拟OCR识别错误的过程,生成新的文本。
- 拼写增强: 故意拼错一些经常拼错的单词。
- 键盘增强: 通过在QWERTY布局键盘上用另一个接近选定键的键替换选定键来模拟随机输入错误。比如键盘中“s”附近是“a”、“w”、“d”、“z”、“x”,因此可以用“a、w、d、z、x”任意一个键来代替原本单词中的“s”,模拟随机输入错误。
单词级别的数据增强:
- 随机交换、删除单词: 随机交换文本中的两个单词,随机删除文本中的一些单词[24]。
- 同义词增强: 使用PPDB同义词库[25]替换随机选择的单词[26],或者使用WordNet同义词库。[27]
- 词嵌入数据增强: 将单词替换为与其top-n个相似的单词来创建新句子。Wang等人[28]提出了一种基于词嵌入的数据增强方法,将单词替换为与其top-n个相似的单词来创建新句子。考虑了不同的预训练词嵌入(例如,GoogleNews[29])。该方法的原理是,在嵌入空间中彼此靠近的单词往往出现在相似的上下文中,这可能有助于保持语法一致性。 然而,基于词嵌入的方法(embedding-based methods)存在一个严重的缺陷,即:嵌入空间中相近的词不一定语义相似,但语义的变化会影响分类结果。例如,“热”和“冷”通常出现在相似的上下文中,因此它们的词嵌入接近,但它们具有完全相反的语义。**反拟嵌入增强算法[30]、[31]**利用同义词词典和反义词词典对初始词嵌入进行调整,解决了这一问题。具体而言,近义词嵌入之间的距离会缩短,反义词嵌入之间的距离会增大。
- 上下文增强[32-33]: 使用BERT[34-35]、DistilBERT[36]、RoBERTA[37]等掩码语言模型(MLMs)根据上下文生成新文本。具体来说,首先在文本的某些位置添加标记<mask>或者用<mask>来替换文本中的某些单词,然后让掩码语言模型(MLMs)来预测应该将哪些单词放在<mask>所处的位置。由于MLMs是在大量文本上进行预训练的,上下文增强通常可以生成有意义的新文本。举个例子吧,原始的英文句子为:“She is a pretty <mask>.” 由于<mask>将句子中的单词进行了遮挡,利用MLMs可以进行预测,例如:“She is a pretty student.” ,“She is a pretty girl.” 、“She is a pretty teacher.” ……
句子和文本级别的数据增强:
- 反向翻译[38](句子和文本级别): 使用翻译模型进行数据增强。将文本翻译成另一种语言,然后将其翻译回原始语言。由于翻译过程的随机性,增强后的文本与原文不同,但保持了语义的一致性。
- 文档复述: Gangal等人[39]提出了一种对整个文档进行复述的方法,以保持文档级的一致性。
一般来说,无论粒度级别或文本生成骨干(即基于规则或语言模型),数据增强的目标都是产生合理的和多样化的新样本,以保持语义一致性。
4.方法
4.1.整体框架
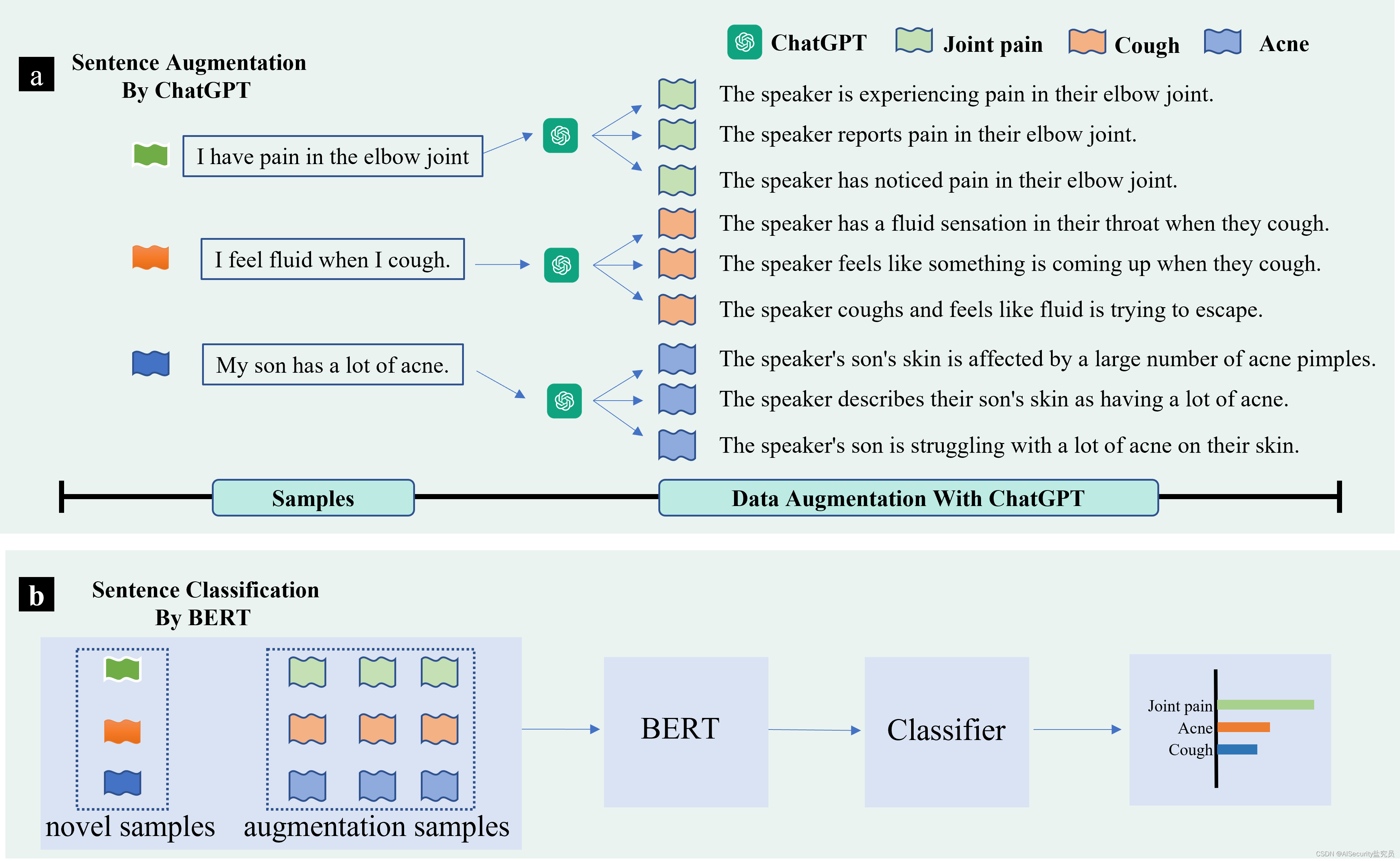
AugGPT框架。a(上图):首先使用XXX进行数据增强。将所有类别的样本输入XXX,并提示XXX生成与已有标记实例保持语义一致性的样本。b(下图):下一步,作者在小样本和生成的数据样本上训练一个基于bert的句子分类器,并评估模型的分类性能。
4.4.Baseline方法
在实验部分,作者将该方法与其他流行的数据增强方法进行了比较。对于这些方法,作者使用了开源库中的实现,包括nlpag[83]和textattack[84]。
-
InsertCharAugmentation: 在文本的随机位置插入随机字符。
-
SubstituteCharAugmentation: 随机替换所选字符。
-
SwapCharAugmentation[22]: 随机交换两个字符。
-
DeleteCharAugmentation: 随机删除字符。
-
OCRAugmentation: 模拟OCR方式进行数据增强,例如:把“I”替换成“1”,把“O”替换成“0”。
-
SpellingAugmentation[23]: 故意拼写错误,例如:把“because”变成“becouse”。
-
KeyboardAugmentation[22]: 模拟键盘打字错误,例如把“s”,变成周围的“w”、“a”、“z”、“x”、“d”、“q”、“e”等字符。
-
SwapWordAug[24]: 随机交换文本中的单词,该方法是Wei等人提出的Easy Data Augmentation (EDA) 方法的子方法。
-
DeleteWordAug: 随机删除文本中的单词。
-
PPDBSynonymAug[26]: PPDB同义词库进行同义词替换。
-
WordNetSynonymAug: WordNet同义词库进行同义词替换。
-
SubstituteWordByGoogleNewsEmbeddings[28]: 利用embedding词嵌入空间中,前n个相似单词进行替换。(使用的词嵌入是用GoogleNews语料库预先训练的。)
-
InsertWordByGoogleNewsEmbeddings[83]: 它从GoogleNews语料库的词汇表中随机选择单词,并将其插入文本的随机位置。
-
CounterFittedEmbeddingAug: 它在反拟合嵌入空间中用单词的邻居替换单词。与googlenewsembeddings使用的GoogleNews词向量相比,反拟嵌入引入了同义词和反义词的约束,即同义词之间的嵌入会被拉近,反之亦然。
-
ContextualWordAugUsingBert(Insert): 该方法使用BERT根据上下文插入单词,即在输入文本的随机位置添加<mask>标记,然后让BERT预测该位置的标记。
-
ContextualWordAugUsingDistilBERT(Insert): 该方法使用DistilBERT代替BERT进行预测,其余部分与ContextualWordAugUsingBert(Insert)相同。
-
ContextualWordAugUsingRoBERTA(Insert): 该方法使用RoBERTA代替BERT进行预测,其余部分与ContextualWordAugUsingBert(Insert)相同。
-
ContextualWordAugUsingBert(Substitute): 该方法[32-33]使用BERT根据上下文进行单词替换,即用<mask>替换文本中随机选择的单词,然后让BERT预测该位置的内容。
-
ContextualWordAugUsingDistilBERT(Substitute): 该方法使用RoBERTA代替BERT进行预测,其余部分与ContextualWordAugUsingBert(替代)相同。
-
ContextualWordAugUsingRoBERTA(Substitute): 该方法[38]将文本先翻译成德语,再翻译成英语,得到一个与原文不同但语义相同的新文本。
4.6.评价指标
作者使用 余弦相似度 和 TransRate[86] 作为指标来评估增强数据的真实度(即生成的数据样本是否与原始样本接近)和紧凑度(即每个类别的样本是否紧凑到可以很好地区分)。
4.6.1.余弦相似度
为了评估数据增广方法生成的样本与实际样本之间的语义相似度,采用了生成样本与测试数据集实际样本之间的嵌入相似度。一些最常见的相似性度量包括欧氏距离、余弦相似度和点积相似度。在这项研究中,作者选择余弦相似度来捕获潜空间中的距离关系。余弦相似度度量的是两个向量夹角的余弦值。当两个向量更加相似时,这个值会增大,并且限定在0到1之间。由于未进行微调的预训练语言模型难以捕捉语义,作者通过BERT-flow[87]方法在基础数据集上对预训练BERT进行微调,最后应用微调后的BERT得到smaple嵌入。余弦相似性度量在NLP中常用[88],作者遵循这一惯例。
4.6.2.TransRate
TransRate是一种基于预训练模型提取的特征与其标签之间的互信息来量化可迁移性的指标,只需对目标数据进行一次遍历。当所有类别的数据协方差矩阵都相同时,该度量达到最小值,这使得无法区分不同类别的数据,使得任何分类器都无法获得比随机猜测更好的结果。因此,较高的TransRate可能表明数据的可学习性更好。
6.总结和讨论
本文提出了一种新的用于小样本分类的数据增强方法。与其他方法不同的是,该模型在语义层面对有限的数据进行扩展,以增强数据的一致性和鲁棒性,从而获得了比当前大多数文本数据增强方法更好的性能。 随着LLM的发展及其多任务学习者的性质[77],NLP中的一系列任务可以以类似的方式得到增强甚至取代。
尽管AugGPT在数据增强方面表现出了很好的效果,但它有一定的局限性。 例如,在医学文本识别和增强时,由于XXX缺乏领域知识,AugGPT可能会产生不正确的增强结果。在未来的工作中,作者将研究通过模型微调、上下文学习(提示工程)、知识蒸馏、风格迁移等,将通用领域的大语言模型(如XXX)适应于特定领域的数据,如医疗文本。
AugGPT证明了增强结果可以有效提升下游分类任务的性能。未来研究的一个有希望的方向是在更广泛的下游任务中研究AugGPT。例如,XXX具有较强的关键点提取能力和句子理解能力,可用于文本摘要等任务。具体来说,XXX对于特定领域的科学论文摘要[90]和临床报告摘要[91]可能有价值。公开可用的特定领域科学论文摘要数据集和临床报告数据集非常罕见,并且由于隐私问题和对专家知识的需求,通常以小规模提供。然而,XXX可以通过以不同的表示风格生成不同的增强摘要样本来解决这一挑战。XXX生成的数据通常都很简洁,对于进一步增强训练模型的泛化能力很有价值。
DALLE2[92]和稳定扩散模型(Stable Diffusion)[93]等生成图像模型的急剧兴起,在计算机视觉中为将AugGPT应用于少样本学习任务提供了机会。例如,精确的语言描述可用于指导生成模型从文本中生成图像或作为少样本学习任务的数据增强方法,特别是与高效的微调方法[94],[95]相结合,如LoRA以实现稳定扩散。因此,来自大型语言模型的先验知识可以促进计算机视觉中生成模型的更快的域适应和更好的少样本学习。
最近的研究表明,大型语言模型(LLM),如XXX-3和XXX,能够解决心智理论(ToM)任务,以前被认为是人类特有的[96]。虽然LLM类似于tom的能力可能是改进性能的意外副产品,但认知科学和人类大脑之间的潜在联系是一个有待探索的成熟领域。认知和脑科学的进步也可以用来启发和优化llm的设计。例如,有人认为BERT模型中神经元的激活模式和人脑网络中的神经元激活模式可能有相似之处,并且可以耦合在一起[97]。这为利用脑科学的先验知识开发LLM提供了一个有希望的新方向。随着研究人员继续研究LLM和人脑之间的联系,作者可能会发现增强AI系统性能和能力的新方法,导致该领域令人兴奋的突破。