
- 这是2020放在arxiv上的一篇自监督暗图增强的文章,很多后续的无监督暗图增强论文都会引用到并且和它比较
- 文章从贝叶斯概率的角度分析了retinex的公式如下:
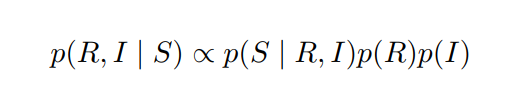
从而等式右边的三项概率的最大化可以分别由3个损失函数导向:
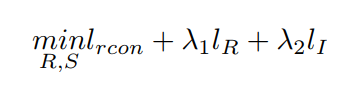
第一项文章定义为L1损失,很常见:
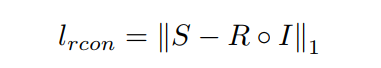
第二项则定义为暗图的亮度分量(HSV颜色空间中的V)直方图均衡化后的结果F(S)和R的亮度分量的L1距离以及R的平滑损失:
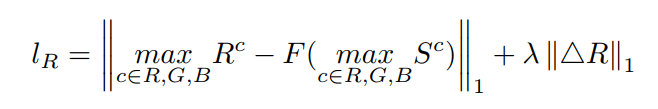
第三项定义如下:
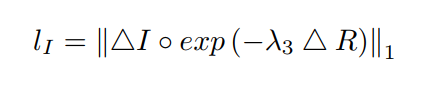
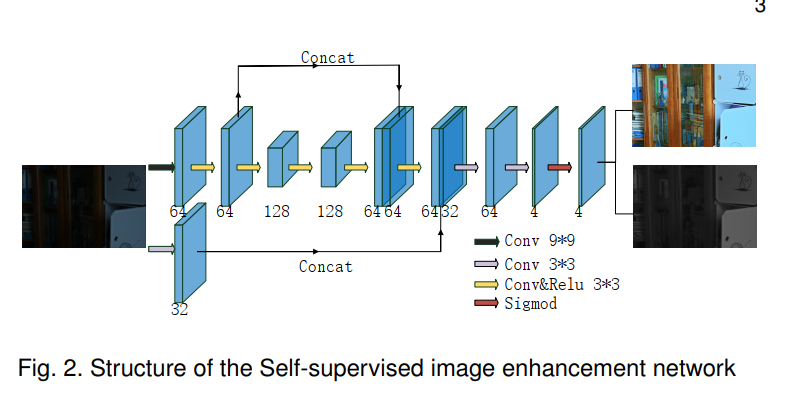
网络结构如下图所示:
- 文章提出先downsample再upsample的网络能去噪,但会使得图片变模糊
- 用LOL的485张真实图像训练,patch size是48*48
- 文章也提到了,其实不同次训练达不到相同的结果

- 同时,文章也提出了,训练可以只用一张图片。在LOL的15张测试集上,选一张作为训练集,训练10000个epoch,再在这15张上测试,效果一样很好。并且,由于用单张图片来训练时,随着迭代次数的增加,网络产生的结果并没有伪影出现,说明伪影并非由于网络设计导致(所以矛头指向了随机梯度下降和数据集?):
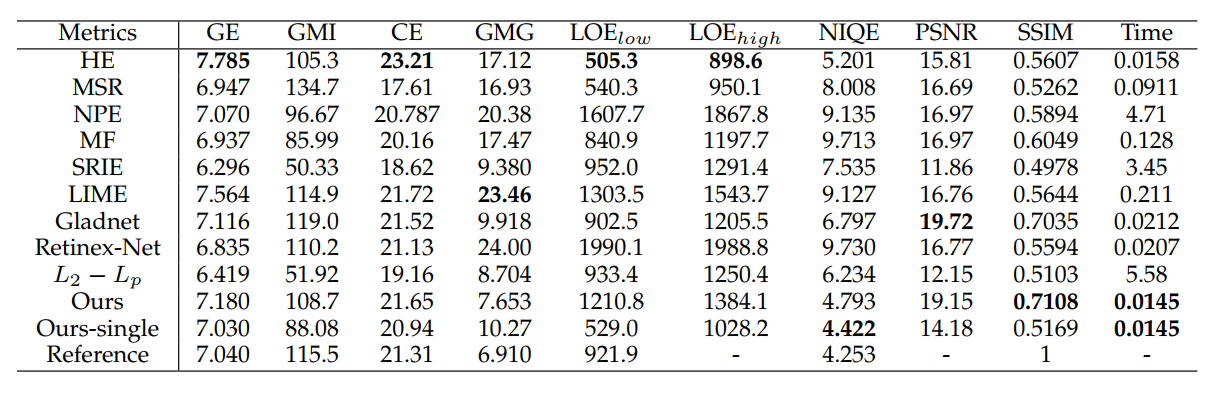
视觉效果看起来也不错:
