论文地址 : https://www.aclweb.org/anthology/P19-1189/
已有研究工作:
TDS,training data selection,可以用来解决监督模型中的数据跨域、分布不匹配的问题,可以去除噪声和不相干的样本。一般的方法是将整个数据集在某种度量标准下进行评分或排序,然后选择前n项。作者认为这样的方法不能体现出领域知识的有效特征,也不能应用于不同的数据性质。对于更通用的度量方法,需要对超参数,也就是阈值的设定有进一步的研究。而且,它和模型训练是相互独立的,不能获得来自任务的反馈。
本文的工作和创新点:
TDS本身是一个有指数复杂度的组合优化问题,不可能穷尽所有组合。因此解决思路是视为一个决策序列。本文使用RL来解决,目标是正确度量训练样本和目标域之间的相关性,根据特定任务所选样本获得的反馈来指导选择过程。模型包括一个产生选择概率的部分SDG(selection distribution generator)一个用于学习数据表示的特征提取器,一个用于测量所选数据性能的分类器。
研究方法:
模型的主要结构如下图所示。
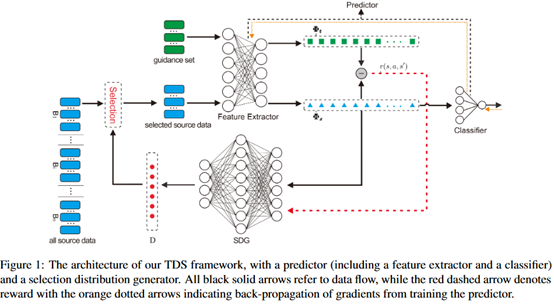
Predictor:包括特征提取器和分类器两个部分。特征提取器是将选择的数据转换为向量表示,输入包括两个部分,一部分是目标域中提取得到的未标记的数据,另一部分是从原域中选择出来的数据。分类器是在一轮TDS结束之后,评估它的表现部分,它的输入来自于特征提取器,它评估的结果也会反馈给特征提取器。
SDG:本身是一个MLP,在每一步中,SDG获得输入来自于特征提取器,产生的输出表示每个实例被选择的概率。
联合训练框架:使用策略梯度将SDG和Predictor联合训练,整体的流程如下:

State:一个给定的状态包括选择的实例和特征提取器的参数,分别用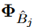 和
和 来表示。
来表示。
Action:是一组0-1空间,决定某个实例是否被选择。
Reward:TDS在数学上的目标是确保所选数组符合目标域的分布,奖励函数如下:
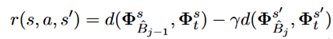
其中d是衡量分布差异的范数,可以通过JS散度(Jensen-Shannon divergence)、MMD(maximum mean discrepancy)、RENYI(the symmetric Renyi divergence)、
loss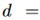
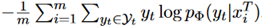 来实现。是一个减少未来分布差异影响的常数。
来实现。是一个减少未来分布差异影响的常数。
优化:优化的目标函数如下:
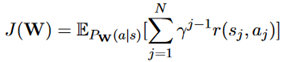
SDG的参数通过策略梯度来更新:
,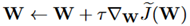
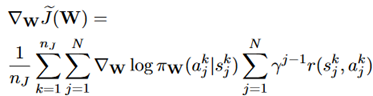
其中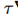 表示的学习率递减速率。
表示的学习率递减速率。
实验部分:在SANCL和产品评论两个数据集上展开实验,前者是POS标记和依赖项解析任务,后者是情感分析任务。在实验中并没有指定阈值n,也就是要选择的实例数量,由模型自主决定,不是一个定值。Predictor先在数据集上预训练两个epoch。实验结果如下:
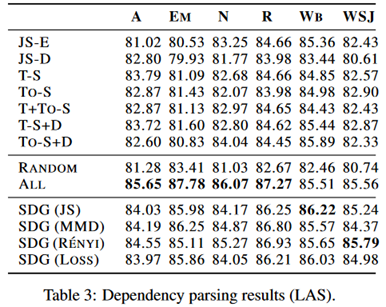
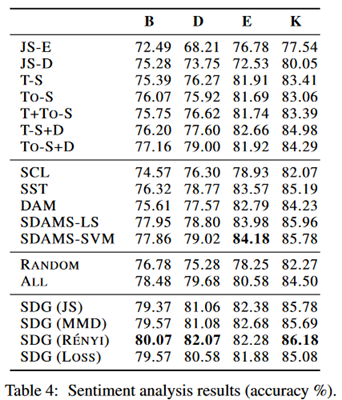
可以看到优于baseline模型,大多数情况下优于在所有源数据上训练的同一个预测器。
评价:
TDS,也就是针对任务选择质量更高的数据,从而排除一些噪声的影响。本文的主要优点在于将TDS的过程和模型的训练过程通过RL统一在一个框架中。同时不需要对TDS过程设置阈值。