原文链接:Scale-Transferrable Object Detection(暂时只有网盘的 - -)
这篇论文是上交的,收录于CVPR2018。
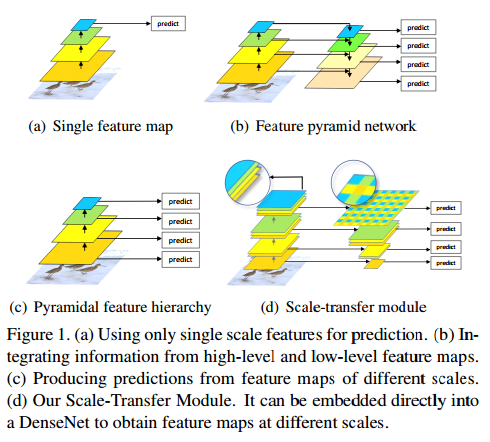
直接看算法过程。Figure1 是几种常见的detect算法对比,(a)是最原始的用一层feature来predict;(b)是FPN,Top-down结构;(c)是SSD,多scale检测;(d)是STDN,也就是本文算法,大致可以看出是和SSD比较类似的,base network是densenet 169,具体见figure 2 (densenet不清楚的移步这里)。
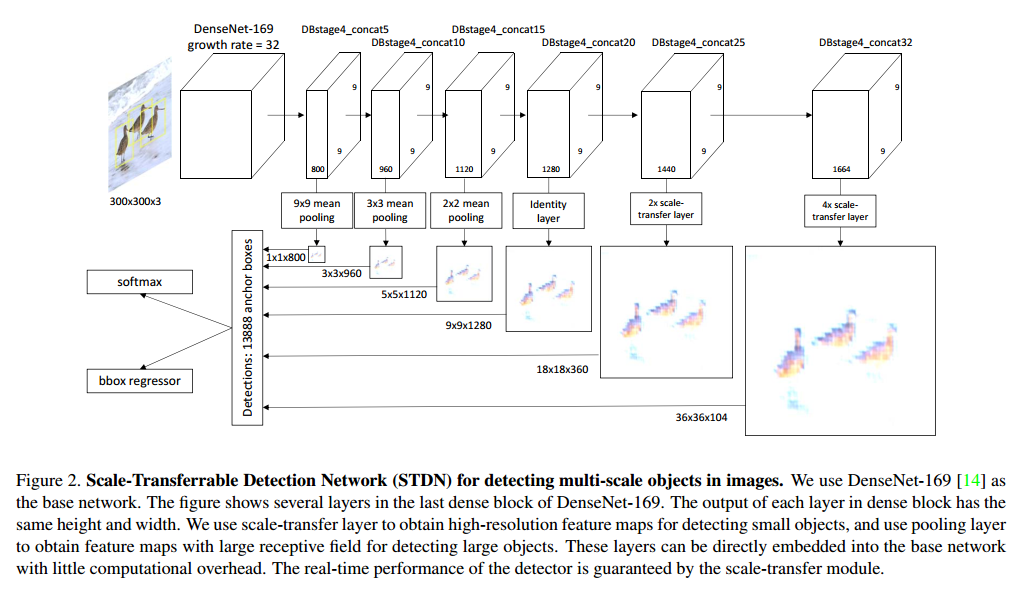
如下图2所示,STDN也是采用SSD的架构,构造出6个不同resolution layer来进行detect。
base ntework是densenet 169, 其网络结构移步这里。
在每个densenet block里,每个layer的输出size是一样的,从图2中看出作者采用的是最后一个densenet block里的6层layer来生成6个不同resolution layer(对应于shicai densenet的concat 5_5,contact5_10,……)。对于low resolution lauer,直接采用mean pool来生成,对于high resloution layer ,采用作者提出的scale transfer layer 进行上采样,这样就能得到如图2所示的6个用于predict的不同resolution layer。
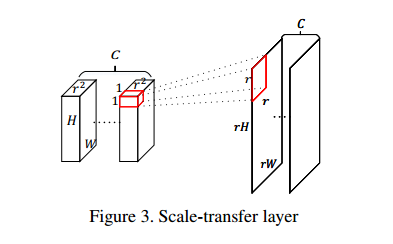
那么scale transfer layer 是怎么进行上采样的呢?从图3可以看出,在此就不贴公式了,直接口头表述。对于H× W ×C · r2
的feature map,根据channel,以r2 为一组,将其划分为C组,每一组都可以理解为是r2个H × W 的feature map,把同一组的H × W 的feature map上的同一位置的像素点组合到一起,也就是说把1*1*r2变成了r*r*1*1,那么一组feature map就变成了rh*rw,完成了上采样。算法和DUC很相似。
此外,为什么要用最后一个densenet block呢?作者说明了网络的顶层具有高语义信息和低细节信息(也就是低分辨率吧)更有利于进行OD,其实这个还是很好理解的,但是会不会引用一部分低block信息会更好一点呢?这个有待考究,有时间的话我会试一下~
文中作者也比较了,直接将VGG换为Densenet,接上SSD和STDN进行了比较,验证了算法的有效性。
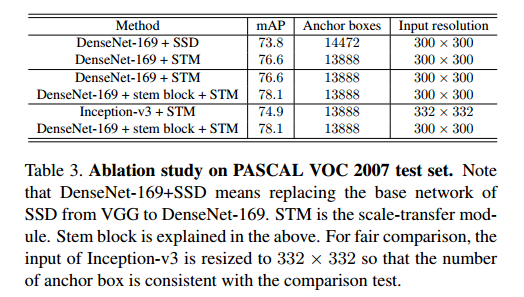
再贴一个本文算法和其它算法在VOC上的对比图,效果还是蛮不错的。coco的就不贴了。。
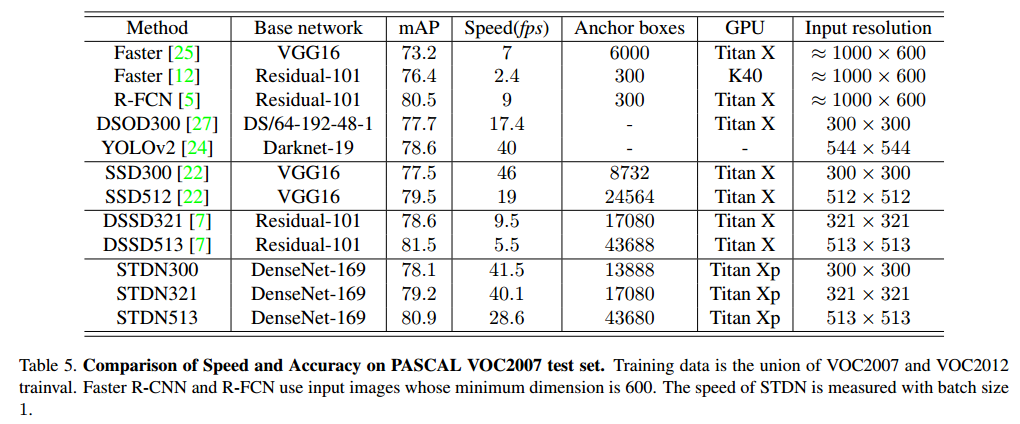
总结:本文是基于SSD算法进行改进,前置网络采用densenet,考虑到追求速度,为什么要接那么多layer去生成low resolution layer呢,多浪费时间,何不从网络本身进行上下采样来获得predict layer。。反正densenent够深,特征提取的应该是很棒的。作者的上采样方法可以说是模仿DUC的。
文章看的比较匆促,表述不清或有错误的看官请指出,共同进步~
2018.05.08