参考代码:BASNet
1. 概述
导读:文章研究的问题是显著性目标检测,但相比于文章之前的一些算法更加关注目标的边缘区域,从而得到更好的显著性目标(分割)结果。对此文章在一个编解码组成的U型网络结构上预测得到显著性目标结果,之后在此基础上添加了一个显著性目标优化模块去更近一步优化分割结果,从而得到更加精细化的边缘呈现。除了网络上的改进之外,文章还提出了hybrid loss,其实是二值交叉熵(BCE)/结构相似度(Structural Similarity,SSIM)/IoU损失三者的结合,这三个损失分别用于监督和侧重于最后结果中的不同成分(也就是文章说到的pixel-level/patch-level/map-level),从而得到整体上更加好的结果。文章的方法在1080 TiGPU上运算速度为25FPS(224*224的输入)。
对于显著性目标检测任务来说,不仅仅需要关注全局信息还需要关注局部细节信息,从而得到更好的显著性目标结果。除了上述提到的对于输入图像信息的抽取方法之外,网络的监督也是需要改进的地方,经常使用的BCE损失函数倾向于在边界区域产生较低的置信度,因而就导致了边界的模糊化。对应于上面提到的两点文章分别采用了下面的策略:
- 1)使用一个ResNet-34组成的U型编解码结构,充分获取网络中的全局和局部信息,生成一个较为coarse的显著性分割结果,之后还额外添加了一个显著性分割结果U型优化模块去提升分割质量;
- 2)将BCE/SSIM/IoU三个损失函数组合起来,在三个不同的侧重维度上进行监督,从而得到质量更高的结果;
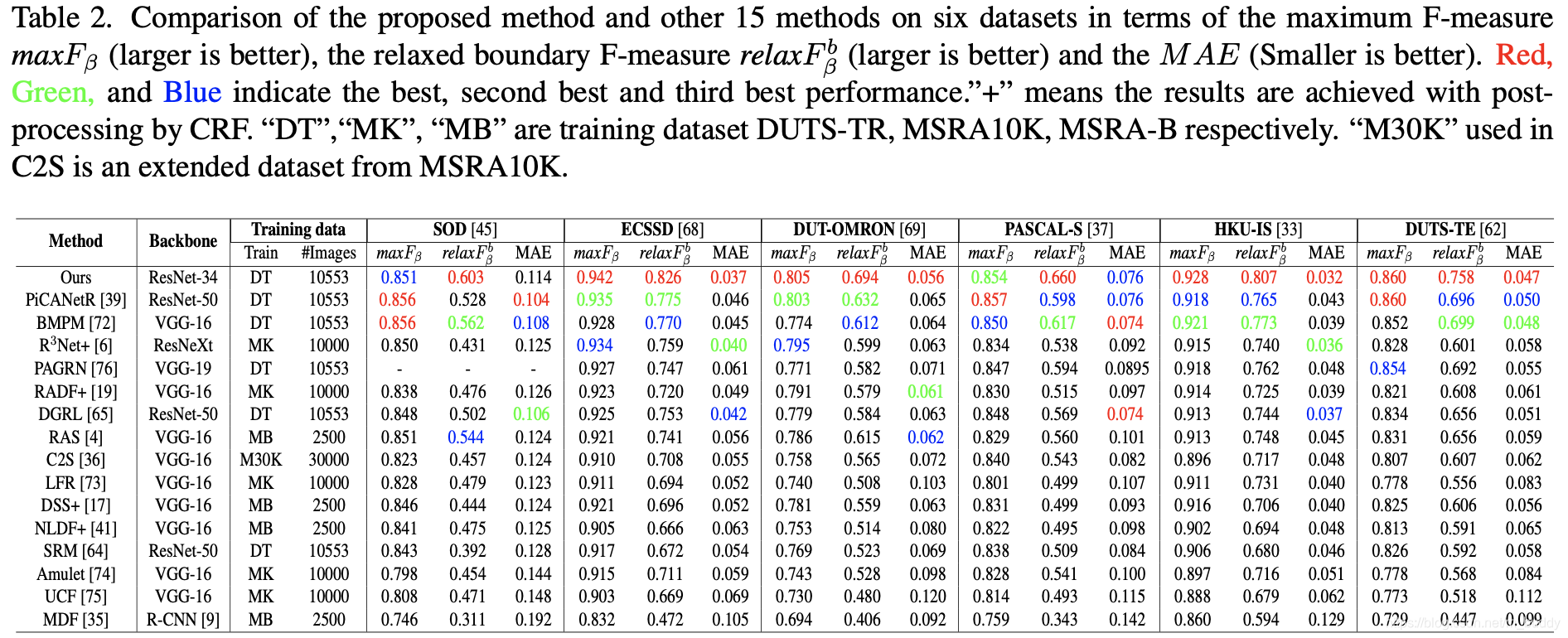
将文章的方法与之前的一些方法进行比较,对比见下图所示:

2. 方法设计
2.1 网络结构
文章pipeline的结构见下图所示:
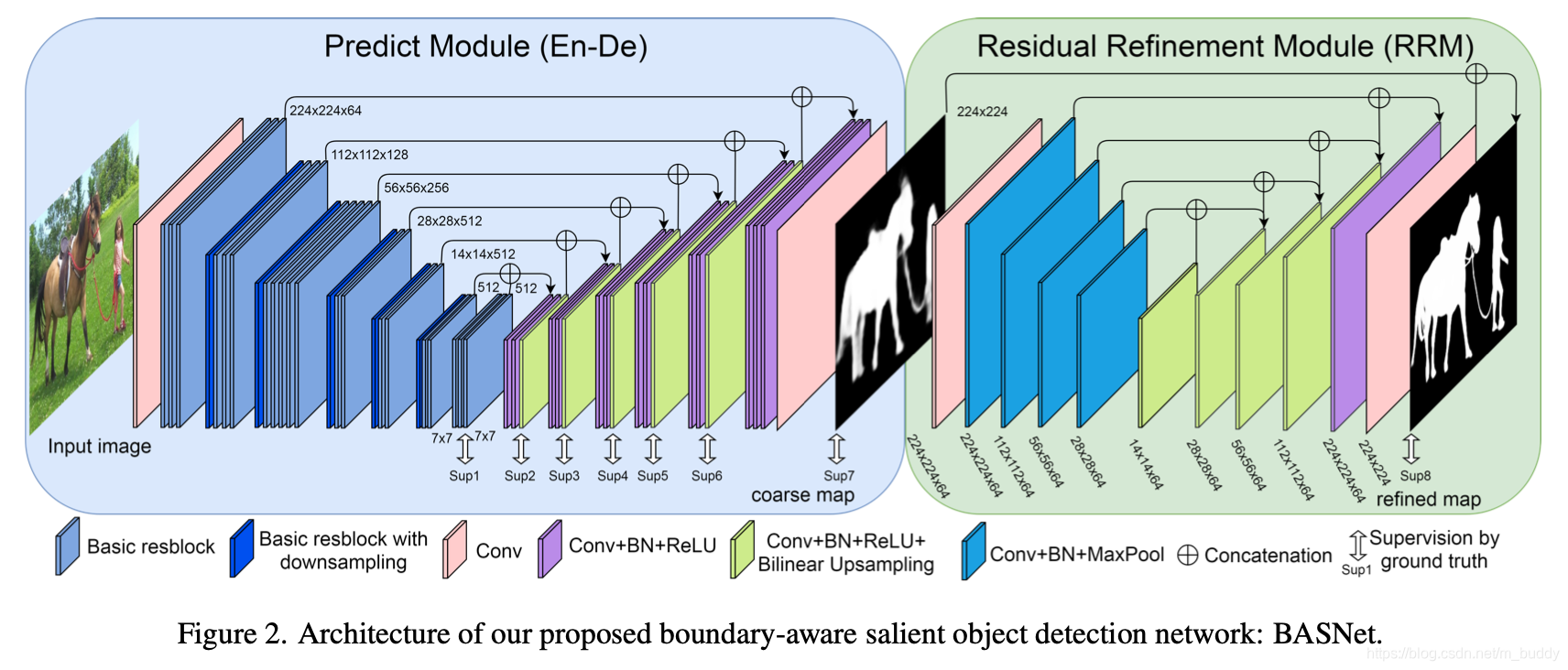
其主要由编解码预测模块和残差优化模块组成。
2.1 编解码预测模块
文章采用以ResNet-34为基础构建的编解码网络结构,从而很好地获取global/local信息。其具体网络结构见图2的左半部分所示,主要的改动有:
- 1)图像的输入端,将原来 s t r i d e = 2 stride=2 stride=2卷积核大小为 7 ∗ 7 7*7 7∗7替换为 s t r i d e = 1 stride=1 stride=1卷积核大小为 3 ∗ 3 3*3 3∗3,从而使得第一个stage输出的特征图与输入的尺寸保持一致;
- 2)在ResNet-34的后部添加了一两个由basic res-blocks(channel=512)构成的stage;
对于解码部分其结构大体与编码部分近似(由三个Conv+BN+ReLU构成),会与之前的特征图进行shortcut连接。在图2左半部分的对应解码stage部分还通过一个 3 ∗ 3 3*3 3∗3 conv+bilinear upsampling+sigmoid组成的预测分支得到显著性目标预测结果,用于引导更具表达能力的特征生成。
2.2 残差优化模块
除了上述提到在每个stage上进行预测监督,文章还在最后预测结果上进行了进一步优化,将编解码得到的coarse结果进一步优化,下图展示了文章的边界分布与期望的边界分布之间的差异:
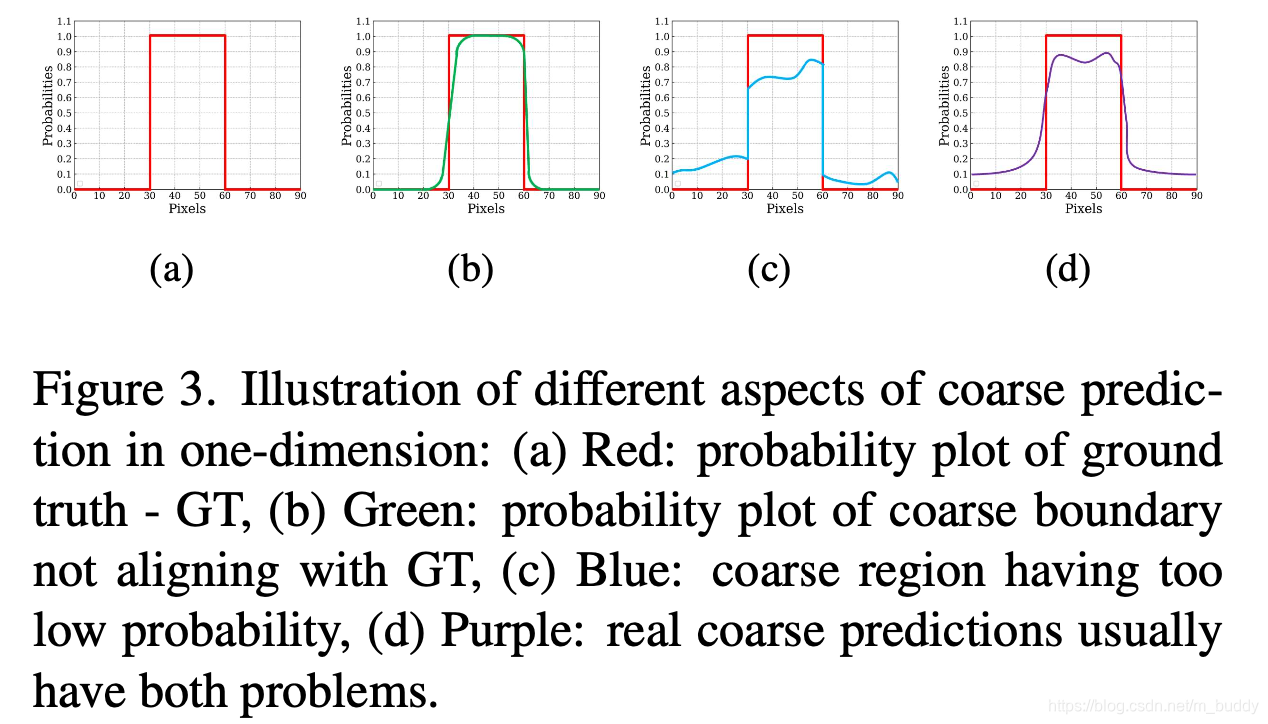
因而,文章最后的输出结果其实是两个部分进行叠加优化的结果:
S r e f i n e d = S c o a r s e + S r e s i d u a l S_{refined}=S_{coarse}+S_{residual} Srefined=Scoarse+Sresidual
同时为了更好获取不同尺度的信息,文章提出对应的残差优化模块,其结构见下图所示(c图):
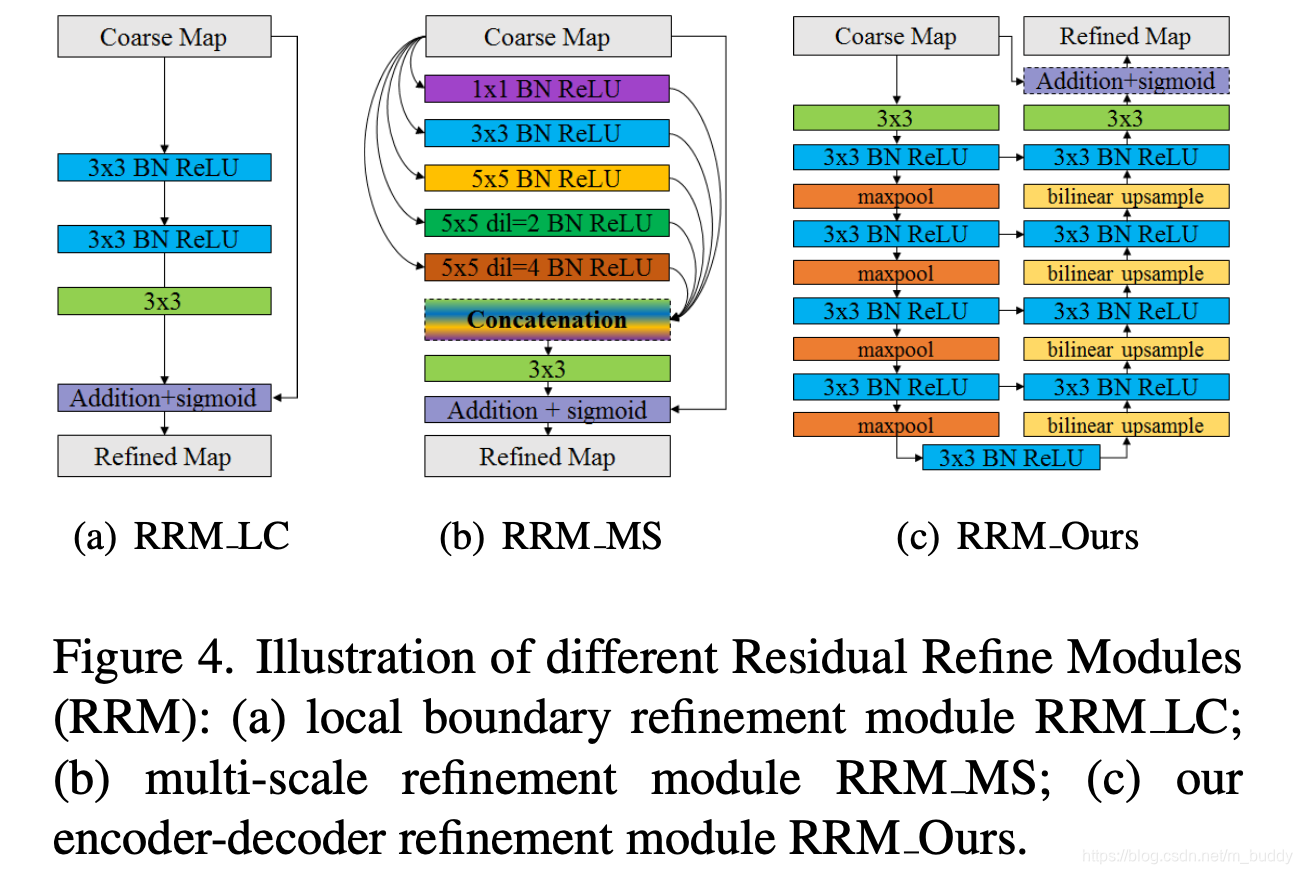
2.4 网络损失函数
文章的损失函数是由多个分支的预测监督得到的,表示为:
L = ∑ k = 1 K α k L ( k ) L=\sum_{k=1}^K\alpha_kL^{(k)} L=k=1∑KαkL(k)
其中, K = 8 K=8 K=8代表是图2中存在8个需要监督的训练的地方, α k \alpha_k αk是代表不同stage上的加权系数。那么对于具体每个stage上的损失函数其由3个部分组成:
L ( k ) = L b c e ( k ) + L s s i m ( k ) + L i o u ( k ) L^{(k)}=L_{bce}^{(k)}+L_{ssim}^{(k)}+L_{iou}^{(k)} L(k)=Lbce(k)+Lssim(k)+Liou(k)
其中对于BCE损失函数其定义为:
L b c e = − ∑ ( r , c ) [ G ( r , c ) l o g ( S ( r , c ) ) + ( 1 − G ( r , c ) ) l o g ( 1 − S ( r , c ) ) ] L_{bce}=-\sum_{(r,c)}[G(r,c)log(S(r,c))+(1-G(r,c))log(1-S(r,c))] Lbce=−(r,c)∑[G(r,c)log(S(r,c))+(1−G(r,c))log(1−S(r,c))]
其中, G ( r , c ) ∈ [ 0 , 1 ] G(r,c)\in[0,1] G(r,c)∈[0,1]代表是在位置 ( r , c ) (r,c) (r,c)处的取值。对于SSIM损失其描述的是图像结构上的差异,是通过patch采样得到的,其在图像(预测结果 S S S与GT 二值掩膜 G G G)中进行采样得到对应的两个样本(采样patch的大小为 N ∗ N N*N N∗N) x = { x j : j = 1 , … , N 2 } x=\{x_j:j=1,\dots,N^2\} x={
xj:j=1,…,N2}和 y = { y j : j = 1 , … , N 2 } y=\{y_j:j=1,\dots,N^2\} y={
yj:j=1,…,N2},则对应的损失函数描述为:
L s s i m = 1 − ( 2 μ x μ y + C 1 ) ( 2 σ x y + C 2 ) ( μ x 2 μ y 2 + C 1 ) ( σ x 2 + σ y 2 + C 2 ) L_{ssim}=1-\frac{(2\mu_x\mu_y+C_1)(2\sigma_{xy}+C_2)}{(\mu_x^2\mu_y^2+C_1)(\sigma_x^2+\sigma_y^2+C_2)} Lssim=1−(μx2μy2+C1)(σx2+σy2+C2)(2μxμy+C1)(2σxy+C2)
其中, μ x , μ y , σ x , σ y \mu_x,\mu_y,\sigma_x,\sigma_y μx,μy,σx,σy代表采样区域 x x x和 y y y的均值和方差, C 1 = 0.0 1 2 C_1=0.01^2 C1=0.012和 C 2 = 0.0 3 2 C_2=0.03^2 C2=0.032为常量用于防止除0的情况,该损失函数会在边界区域给予较大的权重,从而帮助边界进行回归。对于IoU的损失函数,其表示为:
L i o u = 1 − ∑ r = 1 H ∑ c = 1 W S ( r , c ) G ( r , c ) ∑ r = 1 H ∑ c = 1 W [ S ( r , c ) + G ( r , c ) − S ( r , c ) G ( r , c ) ] L_{iou}=1-\frac{\sum_{r=1}^H\sum_{c=1}^WS(r,c)G(r,c)}{\sum_{r=1}^H\sum_{c=1}^W[S(r,c)+G(r,c)-S(r,c)G(r,c)]} Liou=1−∑r=1H∑c=1W[S(r,c)+G(r,c)−S(r,c)G(r,c)]∑r=1H∑c=1WS(r,c)G(r,c)
在下图中展示了三种损失函数在网络训练的不同阶段扮演的贡献力度(从纵向来看):

从上图中可以看到三个损失函数在不同的阶段上扮演了不同的角色(在不同的阶段中扮演不同的重要性),从而在不同方面帮助得到更好的分割结果。
上述文章涉及到的网络结构与损失函数对于最后网络性能的影响见下表所示:
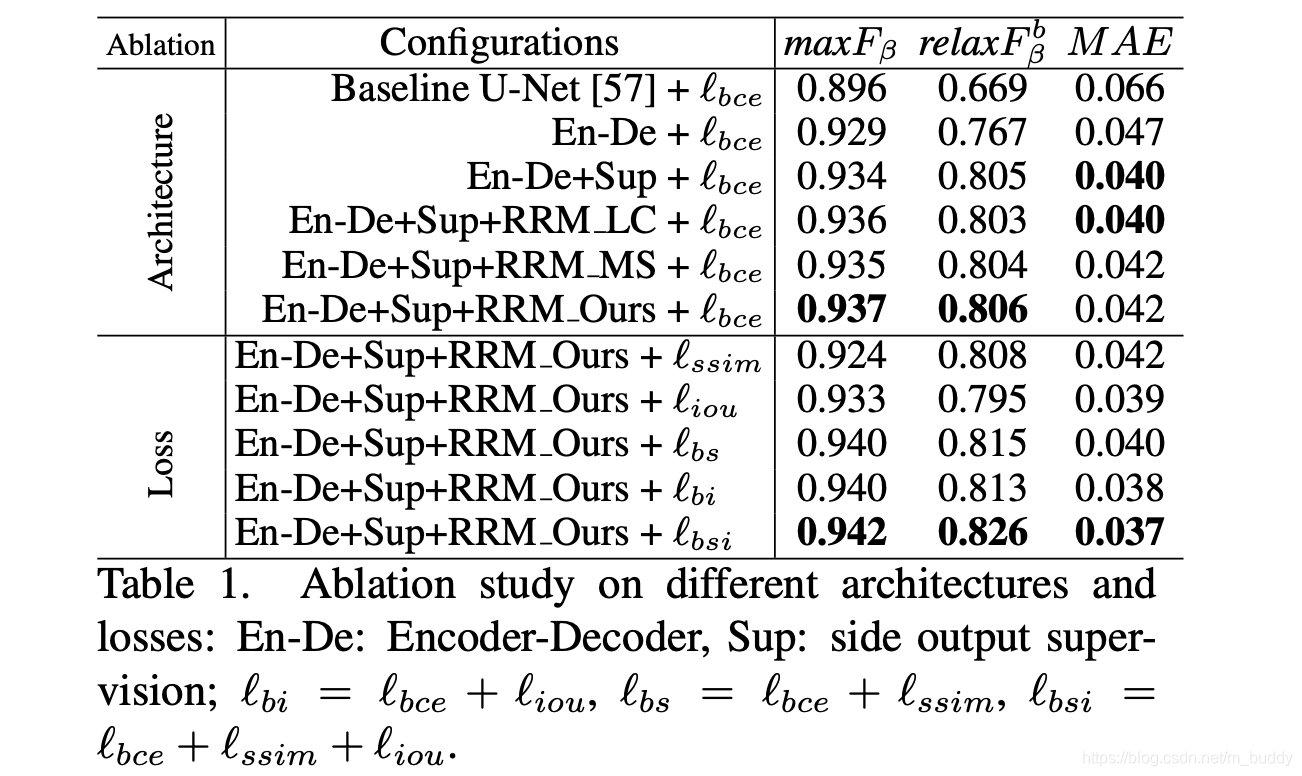
3. 实验结果