前言
大多数弱监督目标检测(WSOD)采用的框架是将多实例学习(MIL)和CNN结合起来,这种框架通常会将特定于某个类别的具有最高置信度的proposal挖掘出来,以训练基于CNN的分类器,但并不会考虑图像中的目标实例的数量。如果图像中有多个目标实例属于同一类别,那么具有较低置信度的目标实例可能会被认为是背景。而被选择的目标实例的尺度和外观变化都是有限的,因此仅用这些目标实例是无法训练出一个具有强大区别能力的分类器的。更糟糕的是,那些被忽略掉的目标实例在训练时可能会被当作负样本,这将进一步降低CNN分类器的区别能力。
为了解决图像中的多目标实例问题,本文提出了一个端到端的目标实例挖掘框架(OIM),它的提出基于两个基础假设:
- 具有最高置信度的proposal及其周围高度重叠的proposal可能属于同一类;
- 属于同一类的目标在外观上应该具有很高的相似度。
在OIM中,构建了空间图和外观图,以挖掘图像中所有可能存在的目标实例,并将这些目标实例用于训练,
- 空间图用于对高置信度的proposal和它周围的proposal的空间关系进行建模;
- 外观图用于捕获所有可能的目标实例,这些目标实例与高置信度的proposal的外观具有很高的相似度。
通过将这两个图整合到训练中,只需图像级别的监督就能精确挖掘图像中所有可能的目标实例,也就是OIM。而更多的目标实例参与到训练中,也会使CNN分类器的区别能力和泛化能力更强。OIM还可以防止学习过程陷入局部最优,因为每个类有更多的目标参与到训练中,并且它们具有很高的相似度。
下图展示了原始图像和它对应的objectness map,说明了目标实例挖掘的过程(从左到右) ,第一到第四列分别代表随机初始化,epoch1,epoch3,最后一个epoch,蓝色和红色的bbox分别表示检测分数小于0.5和检测分数大于0.5的被检测到的实例。这个图说明随着迭代次数的增加,属于同一个类的多个目标实例都能被检测到,并用于训练中。
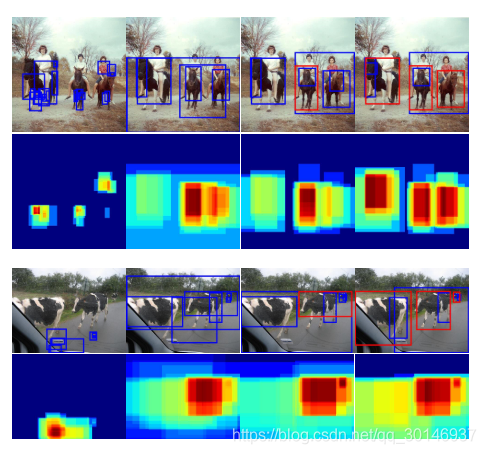
现有的WSOD方法还存在一个问题,置信度最高的proposal很容易集中在目标的局部区域,尤其是对于一些非刚性物体,例如人和动物。这导致的问题是,只能检测到目标的一小部分。为了解决这个问题,本文还提出了一个object instance reweighted loss,让网络把更少的注意力放在局部位置,而更多的关注每个目标较大的部分。
实现方法
下图为框架的整体结构,由两部分组成:第一部分是多实例检测器(MID),它使用加权MIL池同时进行候选区域的选择和分类操作;第二部分是OIM和instance reweighted loss。使用在ImageNet上预训练过的VGG16作为backbone,候选区域的生成采用的是Selective Search方法。
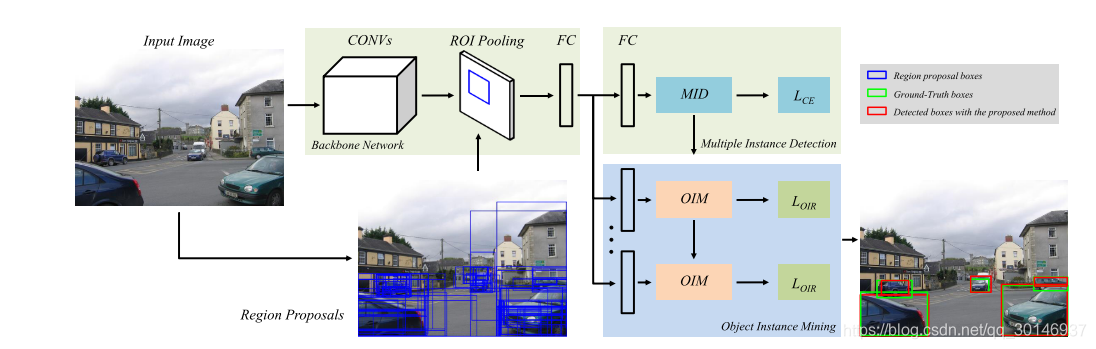
训练时的过程大致如下:
- 首先用MID对候选区域进行分类,分为不同的预测的类别;
- 然后将检测器的结果和proposal的特征整合起来,送入OIM中,用空间图和外观图搜索图像中属于同一类别的所有可能的目标实例;
- 除此之外,instance reweighted loss让网络更多的关注每个目标较大的部分。
1. Object instance Mining(OIM)
给定输入图像 ,类别标签是 ,候选区域为 ,相对应的置信度为 ,能够从中选出具有最高置信度 的核心实例(core instance) ,其中 表示该核心实例的索引。核心空间图(core spatial graph)可以被定义为: , 中的每个节点表示一个被选择的proposal,该proposal与核心实例的重叠度(空间相似度)大于一个阈值 ; 中的每条边表示这种空间相似度。 中的每个节点都将被选择,并且被标记为和 一样的类别标签。
将每个proposal的特征向量定义为
,他们是通过全连接层产生的。每个向量对一个proposal的特征表示进行编码。外观图被定义为:
,
中的每个节点表示一个被选择的proposal,该proposal与核心实例具有较高的外观相似度;
中的每条边表示这种外观相似度。相似度是通过计算核心实例的特征向量与其它proposal的特征向量之间的欧几里得距离得到的:
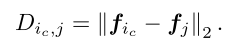
只有当proposal
满足以下两个条件,才能被添加到
的节点中:
- ;
- 与所有之前被选择的proposal之间没有重叠。
表示
的平均类间相似度,它使用
中所有节点的平均距离来表示这种相似度:
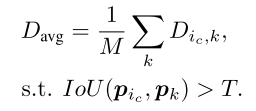
其中
表示满足以上条件的节点,
是
中这些节点的数量,
是一个由实验决定的超参数。
对于
中的每个节点,还要为它们构建空间图
,然后所有这些节点都参与到训练中。如果没有一个proposal与核心实例有较高的相似度,那么只有核心实例和它周围的proposal,也就是
参与到训练中。OIM的实现过程如以下算法所示:

总结一下就是:
- 给定输入图像 ,候选区域为 ,图像标签为 ;最终要得到的输出是外观图中的所有节点 ;
- 将图像 和proposal送入网络中,得到特征向量 ;
- 是训练数据的类别列表,对于 中的每个 ,如果图像标签是 ,选择置信度最高的proposal ,然后将 添加到 和 中;
- 计算其它proposal 与 的相似度 和IoU,如果IoU大于阈值 ,就将 添加到 中,并且计算 ;
- 基于 对proposal 进行升序排序;
- 设已经被添加到 中的proposan节点为 ,如果 ,并且 与 之间的IoU等于0,那么就将 添加到 和 中,IoU大于0的话不添加。
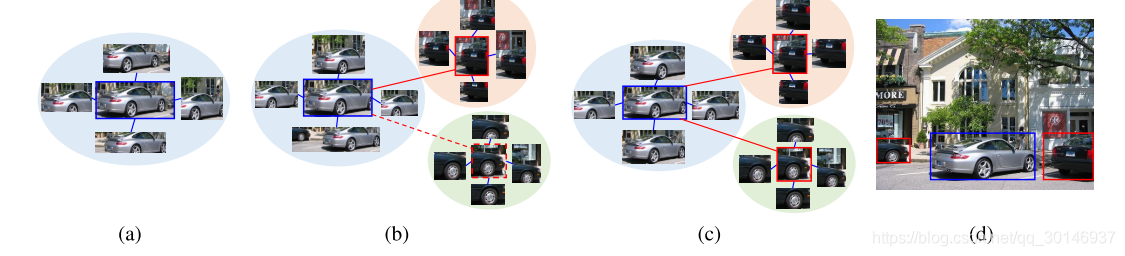
下图说明了检测属于相同类别的所有可能目标实例的过程,(a)是核心空间图,(b)到(c)描述了不同epoch的空间图和外观图,(d)展示了所有被检测到的实例。蓝色bbox表示检测到的具有最高置信度的核心实例,红色bbox与核心实例具有较高相似度的其它实例,蓝线和红线分别表示空间图和外观图的边,(b)中的红色实线表示外观相似度小于规定的阈值,因此该目标实例没有参与到这一阶段的训练中。
2. Instance Reweighted Loss
给定一个图像及其标签
,对于空间图
中的第
个proposal,它预测的标签
,其中
或
表示该proposal
是否属于类
,
是背景。下面这个损失函数中,
是第
个proposal的损失权重,
是
中用于训练的proposal,
是拥有最高置信度的核心proposal:
从上式可以看出,每个空间图中的proposal的贡献是相同的。因此,拥有相对来说较低置信度的非核心proposal,也就是位于核心proposal周围的那些区别度较低的proposal,它们在训练中就很难被学习到。为了解决这个问题,平衡核心proposal和非核心proposal的权重,让网络把更多的注意力放到区别度更低的非核心proposal上,本文提出了如下的instance reweighted loss:
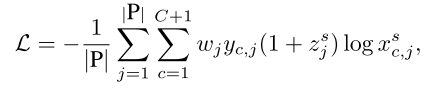
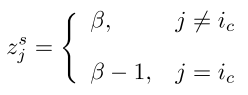
引入
来平衡空间图
中proposal的权重,
是一个超参数。在后向传播的过程中,非核心proposal的梯度扩大到原来的
倍,而核心proposal的的梯度被缩放到原来的
倍。
使用标准的多类别交叉熵损失函数来训练多标签分类,训练时将多类别交叉熵损失函数与instance reweighted loss结合起来。
结论
本文提出的OIM通过充分挖掘图像中属于同一类别的目标实例,解决了WSOD中的局部最优问题。虽然挖出了许多其它的目标实例,但它们与核心实例相比,区别度很小,网络很难注意到它们。为了让网络更多的注意到这些目标实例,本文还提出instance reweighted loss,用于平衡核心实例与非核心实例的权重,这样可以得到更精确的结果。
