Scale-Transferrable Object Detection算法详解
论文背景
论文名称:Scale-Transferrable Object Detection
论文日期:2018年提交至CVPR
算法背景
在目标检测领域,针对多尺寸对象的检测一直是一个难点,本文提出了一个名为STDN算法,可转化尺寸检测算法。
- 不同于之前的算法:利用网络的多个网络层的特征映射进行结合预测。
- STDN:利用具有向量化的超分辨率网络层(又被称为可转换尺寸层/模块)显式地探索跨多个检测标度的跨尺度一致性特性。
尺寸转化模块适用于基础网络,只有一点计算消耗。
尺寸转化模块与 DenseNet 网络结合,组成一个one-stage目标检测器。
本文在PASCAL VOC 2007 与 MS COCO两个数据集上进行了测试实验。
算法简介
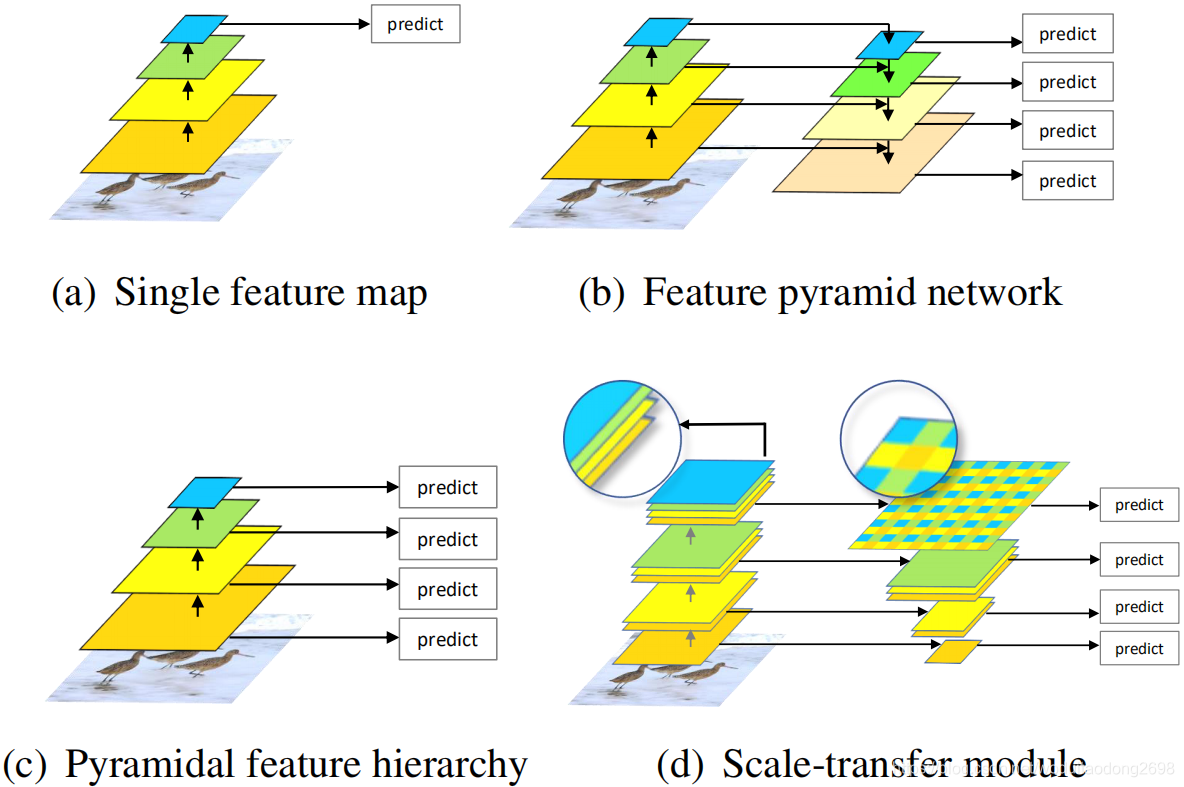
多尺寸问题一直是目标检测领域的一个难点,为了解决这一问题,多种方法被提出:
- 图片金字塔,获得不同尺寸的特征。 但是会增加内存与计算消耗。
- RPN自动提取特征,例如Faster R-CNN使用一层神经网络以及一个特征映射预测不同尺寸与比例的候选区域。但是卷积神经网络每一层的感受野是固定的,而待检测对象的尺寸是不确定的,会导致检测准确率下降。
- 利用不同深度的网络层的特征映射预测不同尺寸的对象,例如SSD, MS-CNN。浅层的特征图具有更小的感受野,用于预测小尺寸的对象,而深层的特征图具有更大的感受野,用于预测大尺寸对象。但是浅层特征图具有更少的语义信息,会影响检测准确率。
- 结合不同网络层的语义信息,例如FPN,ZIP,DSSD等。一个由上而下的结构用于结合不同深度的特征图,从而获得所有尺寸的更多语义信息。但是特征金字塔的构造会需要添加多余的网络层,从而导致计算量增加。
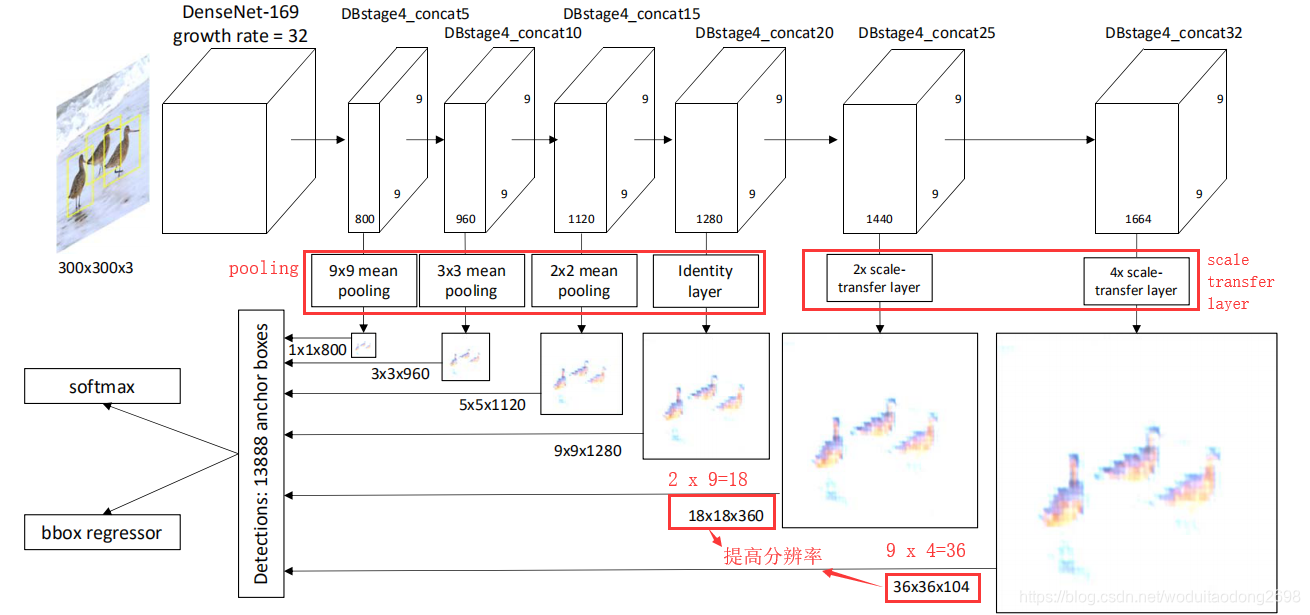
STDN:获得高级语义多尺寸特征图,同时不会影响检测速率。将STM嵌入到DenseNet网络,DenseNet网络结构就是结合结合低层与高层的特征,从而得到更强大的特征。DenseNet的表现优于ResNet,是2018年发表在CVPR上的一篇文章。
STM:由池化与尺寸转化层两部分构成。
- pooling:获取小尺寸的特征图;
- Scale-transfer layer:获得大尺寸特征图。
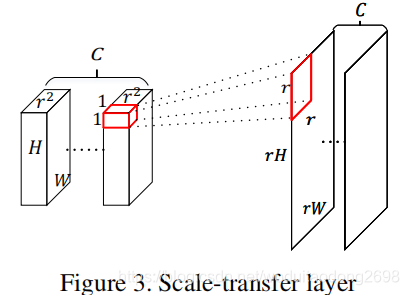
本算法利用scale-transfer layer,拓展了特征图的长与宽,而不增加通道数量。这能有效减少参数数量,提高检测效率。
STM的两个优势:
- 能有效结合DenseNet的特征图的低级对象细节特征与高级语义特征。
- 由池化层与超分辨率层组成,没有额外的参数与计算量。
本文的主要贡献:
- 提出了一个获取特征金字塔的新框架,结合高级与低级语义特征;
- 在高层使用超参数层获得高分辨率特征图,从而不增加参数量。
- 在PASCAL VOC 2007与MS COCO数据集上进行了测试实验,准确率超过前沿算法,同时速度增快。
算法对比
目前常用的优化多尺寸目标检测的方法:
- 提取多个网络层的特征,然后使用结合的特征进行目标检测。例如ION,HyperNet,YOLOv2。
- 利用不同深度的特征图预测不同尺寸的对象。例如 SSD,MS-CNN,DSOD。
- 结合以上两种优化方法。例如 FPN,TDM,DSSD。
本文就是第三种优化方法, 利用不同的特征图预测不同尺寸的对象,使用STM模块获取不同分辨率的特征图,同时利用DenseNet结合不同网络层的特征。
算法详解
网络结构
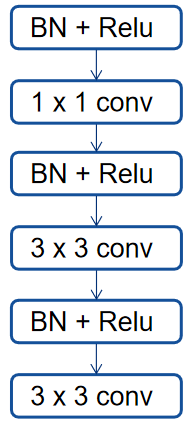
DenseNet
在DenseNet的每一个dense block中,对于每个层,其特征映射被用作所有后续层的输入。因此,这样就结合了输入图像的低层次和高层次特征。
stem block
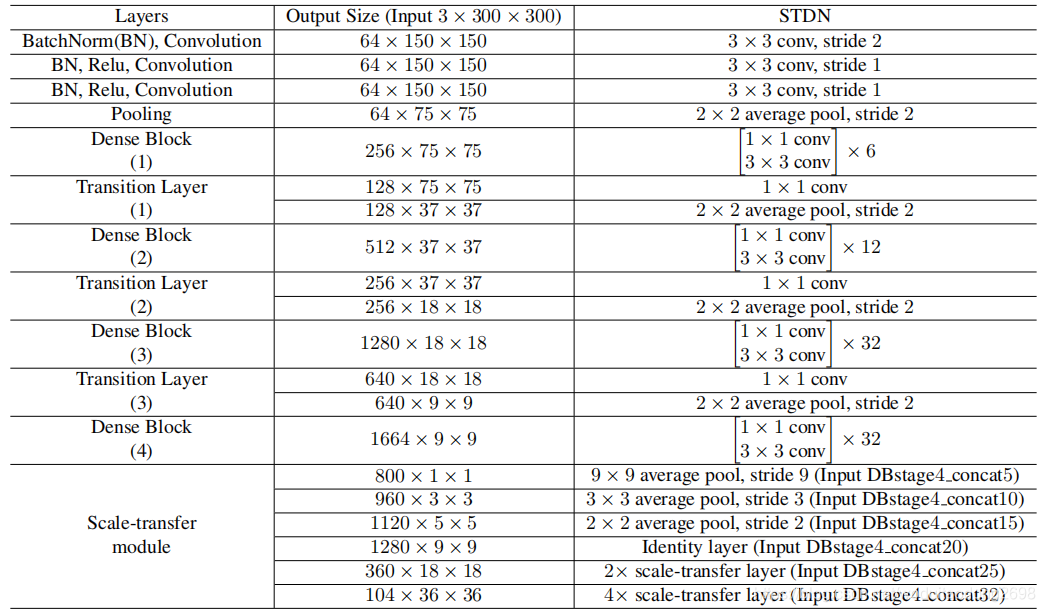
本文将输入层(7×7卷积层,步长=2,然后是3×3最大池层,步长=2)替换为3个3×3卷积层和1个2×2平均池层。第一卷积层的步长为2,其余的为1。所有三个卷积层的输出通道为64。
原始的DenseNet-169中的输入层由于连续两个下行采样而丢失了很多信息。这将降低目标检测的性能(尤指目标检测),适用于小型物体。
STM
在DenseNet的最后一个dense block中,除了通道数之外,所有层的输出都具有相同的宽度和高度。
为了获得具有丰富语义信息的不同分辨率的特征图,本文提出了STM。
- 在网络低层中,使用平均池化获得低分辨的特征图;
- 在网络深层中,使用scale-transfer layer获得高分辨率特征图。
具体实现过程:
输入:特征图尺寸H × W × C · r2,r是上采样因子。
输出:高分辨率特征图。
以 r=2为例:
将r2通道的特征值平铺到一个通道上,拓宽长与宽,减小通道数。从而减少参数,提高检测效率。

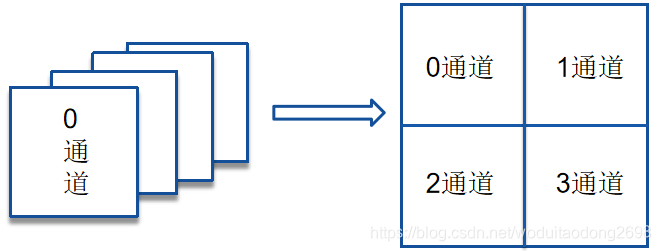
与反卷积不同,不需要在卷积操作前的反池化时,用0来进行填充,因此不需要额外的参数。
Object Localization Module
STDN由一个基础网络以及两个预测特定任务的子网络:
- 基础网络用于进行特征提取;
- 其中一个子网络用于目标分类;
- 另一个子网络用于边界框回归定位。
锚框
锚框尺寸与SSD相同,比例由三种,[1.6, 2.0, 3.0],IoU设置为0.5,但是在匹配过程之后,只有少量的正样本,因此采用hard negative mining用于解决正负样本不平衡问题,使用hard negative mining之后正负样本的比例最少为1:3。
hard negative mining:
先将初始样本放入分类器,然后再将错误分类的样本放入负样本中继续训练,直到达到分类要求,就是反复训练难以正确分类的样本。
分类子网络
分类损失函数为softmax。
最后输出的参数有KA个,K指共有K个对象,A指每个定位共有A个锚框。

定位子网络
损失函数为Smooth L1。
输出参数为4A,共A个锚框,每个锚框有4个坐标值。
训练损失函数
由分类损失函数与定位损失函数两部分组成。

实验
检测器基于MXNet框架,使用SGD进行训练。
本文分别在PASCAL VOC 与MS COCO两个数据集上进行测试实验。
PASCAL VOC:
IoU:0.5;
输入图片尺寸:300 x 300;
mini-batch:80;
学习率:前500个epoch: 0.001;
600个epoch:降为0.0001;
700个epoch:降为0.00001。
对比实验:
baseline:SSD
DSSD是在SSD基础上进行了改进,利用ResNet替代原来的VGG-16,同时融合了不同深度的网络层的特征。
DSSD准确率比SSD高,但是检测速率下降了。
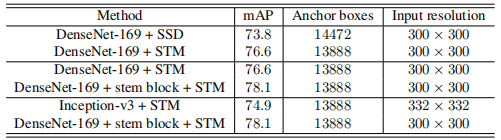
对比不同模块对结果的影响:
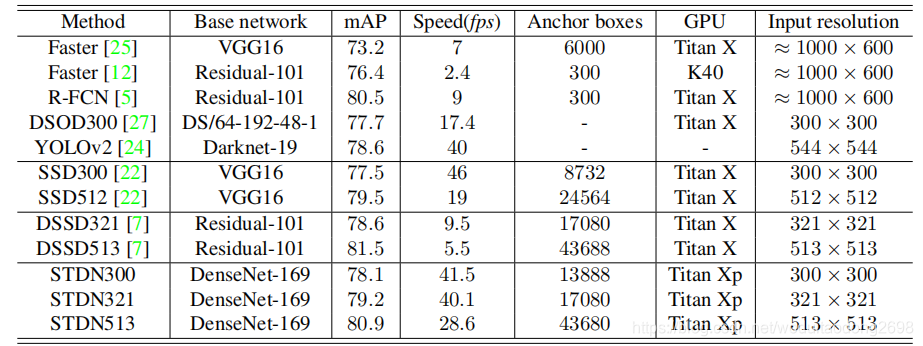
对比不同算法的检测速度:
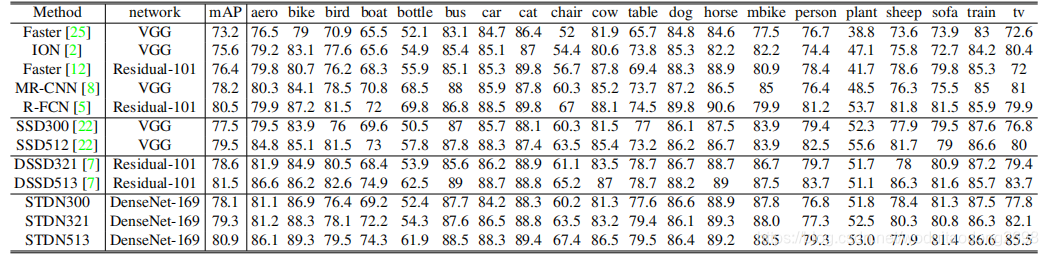
COCO:

结论
STDN算法提出了一个scale transfer layer,有效减小了参数数量。算法不仅提高了检测精度,还提高了检测速度。