1介绍
尺度问题是目标检测的核心,为了检测不同尺度的目标,一个基本的策略是使用图像金字塔[1]来获得不同尺度的特征。但是,这会大大增加内存和计算复杂度,从而降低目标检测器的实时性。
卷积神经网络近几年已经在图片分类、语义分割和目标检测上取得了相当大的成功。用卷积神经网络代替手工提取特征,大大提高了目标检测器的性能。Fater R-CNN[25]使用一层卷积特征图来预测不同尺度和长宽比的候选区域提案。由于CNN中每一层的感受野是固定的,所以存在固定的感受野与图像中不同尺度的对象之间存在着不一致。SSD[22]和MS-CNN[3]利用卷积不同层的特征图来预测不同尺度的物体,如图1c。浅层特征具有小的感受野用于检测小目标,深层特征具有较大感受野用于检测大目标。然而,浅层特征的语义信息较少,这可能会影响小目标检测的性能。FPN [20], ZIP[19]和DSSD[7]集成了所有尺度特征图上的语义信息如图b。自顶向下的体系结构将高级语义特征映射与低级语义特征映射相结合,从而在所有尺度上生成更多的语义特征映射。然而添加额外的层了提高检测效果,但却增加额外的计算开销。
为了获得高级语义多尺度特征图,同时又不影响检测的速度,我们开发了一个scale-transfer模块(STM),并将该模块直接嵌入到DenseNet中。DenseNet的作用是在CNN中集成低级和高级的特性,以获得更强大的特性。由于网络结构紧密相连,其特点是
DenseNet自然比普通卷积功能更强大。STM由池化层和scale-transfer层组成。池化层用于获取小尺度特征图,scale-transfer层用于获取大尺度特征图。scale-transfer层由于其简单、高效的特点,首次提出用它来做图像超分辨率[28],也有一些人用它来做语义分割 [30]。我们利用该层扩展特征图分辨率来做目标检测。
我们采用scale-transfer模块构造一种单级目标探测STDN,如图二所示。由于DenseNet最后一层稠密块的feature map的通道数量最多,因此scale-transfer层通过压缩通道的数量来扩展feature map的宽度和高度(图1(d))。这样可以有效地减少下一卷积层的参数个数。
STM层适合基础网络并且能进行端到端的训练。首先,结合DenseNet[14]在低层对象细节特征和高层语义特征特征。我们将证明这将证明目标检测的准确性。其次,STM由池化层和super-resolution层组成,不需要额外的参数和计算。实验结果表明,本文提出的框架能够准确地检测目标,满足实时性要求.
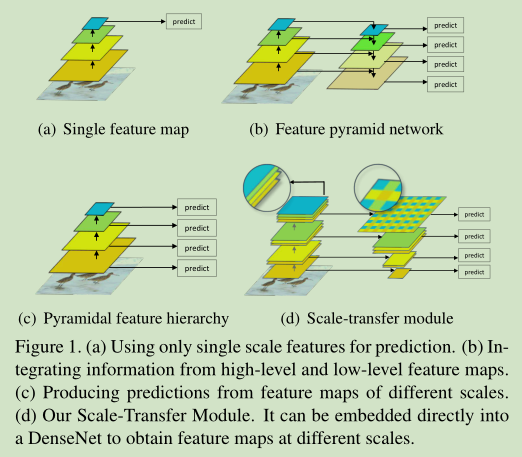
图一,(a)只使用单一尺度特征进行预测(b)结合高层与低层特征图信息。(c)根据不同尺度的特征图进行预测。(d)我们Scale-Transfer模块。它可以直接嵌入到DenseNet中,获得不同尺度的特征图。
我们提出的方法属于第三类方法。我们使用DenseNet[14]来结合不同层的特征,并使用scale-transfer模块来获得不同分辨率的特征图。我们的模块可以直接嵌入到DenseNet网络中,成本很低。

图二,STDN多尺度检测网络结构,我们使用DenseNet-169[14]作为基本网络。图中显示了DenseNet-169的最后一个密集块中的几个层。密集块中各层的输出具有相同的高度和宽度。我们使用scale-transfer层来获得高分辨率的特征图来检测小目标,使用池化层来获得接受域大的特征图来检测大目标。这些层可以直接嵌入到基本网络中,而不需要太多的计算开销。尺度转换模块保证了探测器的实时性。
3. Scale-Transferrable Detection Network
我们使用DenseNet[14]作为我们的基本网络。在DenseNet的每一个密集块中,对于每一层,它的feature map都被用作所有后续层的输入。密集块的最后一层的输出通道数最多,适合作为scale-transfer层的输入,通过压缩通道数来扩展特征图的宽度和高度。然后描述了生成不同尺度特征图的尺度转换模块。接下来,我们描述了整个目标检测/位置预测网络体系结构和网络训练细节。
3.1. Base Network : DenseNet
作者使用DenseNet-169作为基础网络并在ILSVRC CLSLOC数据集上预训练。DenseNet的每一层输出包含前面层的输出。从而结合了输入图像的低层和高层特征,适合于对象检测。我们将输入层(7×7卷积层,stride = 2,然后是3×3 max pooling层,stride = 2)替换为3×3卷积层和1卷积层2×2平均池化层。第一个卷积层的步长是2,其他的是1。三个卷积层的输出通道都是64。我们称这些层为Stem block。对应表1中的前三个卷积操作。一种解释是原始DenseNet-169的输入层由于连续两次向下采样而丢失了很多信息。这将损害对象检测的性能,特别是对小对象。

表1,STDN网络结构
3.2. High Efficiency Scale-Transfer Module
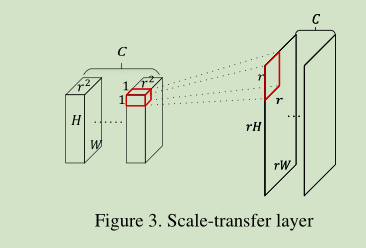
尺度问题是目标检测的核心问题。将多个不同分辨率特征图预测结果相结合,有利于多尺度目标的检测。但是,如图2所示,在最后一个密集块中,除通道数外所有层的输出都具有相同的宽度和高度。如图s所示,首先将输入feature map在channel维度上按照r^2长度进行划分,也就是划分成C个,每个通道长度为r^2的feature map,然后将每个1*1*r^2区域转换成r*r维度作为输出feature map上r*r大小的结果,最后得到rH*rW*C的feature map。例如,当输入图像为300×300时,DenseNet-169的最后一个密集块维度为9×9。结合scale-transfer计算公式,此时r=1/4。即经过scale-transfer后特征图尺度为9x4=36,通道数为1664x1/16=104。一种简单的方法是直接使用类似于SSD[22]的低分辨率地物图进行预测。但是,低层特征图缺乏对目标的语义信息,这可能导致对目标检测的性能较低。实验如表3所示。
Scale-tranfer模块非常高效,可以直接嵌入到DenseNet的密集块中。为了获得较强的语义特征映射,我们利用DenseNet的网络结构,通过concat操作将底层特征直接转移到网络的顶层。网络顶部的特征图既有低层的细节信息,又有高层的语义信息,从而提高了目标定位和分类的性能。此处concat结构就如同ResNet网络结构中的快捷路径。将浅层特征与深层特征相融合。
我们从DenseNet的最后一个密集块中得到了不同尺度的特征图。在scale-model模块中,我们使用平均池层来获得低分辨率的特征图。对于高分辨率的特征图,我们使用一种称为scale-model技术。
假设尺度传递层输入张量的维数为H×W×C·r2,其中r为上采样因子。scale-transfer层是元素周期性重排的一种操作。如图3所示,scale-transfer层通过压缩feature map中的通道数来扩展宽度和高度。公式如下:

ISR是高分辨率的特征图ILR 为低分辨率特征图。在卷积运算之前,反池化层需要填充0,而不是使用反卷积层,尺度转换层没有额外的参数和计算量。我们将平均池和scale-transfer层称为scale-transfer模块。我们将scale-transfer模块直接嵌入到DenseNet中,得到了不同尺度下的六个特征图。最后我们用着6个特征层来构建one-stage目标检测STDN.
scale-transfer层可以有效地减少DenseNet致密块最后一层的通道数,减少下一层的参数和计算量。这提高了探测器的速度
3.3. Object Localization Module
可标度转移检测网络(STDN)由一个基本网络和两个任务特定的预测子网络组成。基本网络的作用是做特征提取。第一个子网用于对象分类,第二个子网用于包围盒位置回归。
Anchor Boxes
我们从scale-transfer model中获得一些列的默认框,与SSD一样,我们在不同的层使用不同的默认框比例[1.6,2,3]。与ground turth的IOU大于0.5的默认框为正样本,其余为负样本。经过以上处理,大部分默认框为负样本,我们使用hard negative mining来保证正负比例为1:3
Classification Subnet
分类子网的作用是预测属于一个类别的每个锚点的属于哪一类别,它包括一个1×1卷积层和两个3×3卷积层。每个卷积层前面都有一个batchnorm层[15]和一个relu层。最后一个卷积层有KA滤波器,其中K是类别数量,A是每个空间位置的锚的数量。分类损失是多个类置信度softmax损失和
Box Regression Subnet
这个子网的目的是将每个锚框的偏移量返回到匹配的ground-truth对象。除了最后一个卷积层有4A滤波器外,box回归子网的结构与分类子网相同。Smooth L1损失[9]用于定位损失,边界盒损失仅用于阳性样本
Training Objective
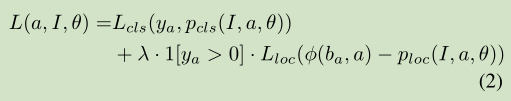
其中a为anchor,I是图片,θ是优化参数,L cls为分类损失,L loc为定位损失。Ya属于{0,1,….,k}是类标签,当为背景时ya=0。Ploc(I,a, θ)和Pcls(I,a, θ) )预计框编码和对应的类。φ(b a ,a) 是一个编码与锚a匹配的Ground truth,λ是一种交换系数
训练目标是将分类和定位损失最小化: