前言
许多工作证明分类器在面对对抗攻击(adversarial attack)时是非常脆弱的,比如有一种对抗样本,它只对原图进行很轻微地修改,但是在视觉上与原图相比是完全不同的。因此也有很多工作致力于提升分类器的鲁棒性。
最近的一些工作发现,目标检测器也会由于蓄意设计的输入而受到攻击,如下图所示,展示了标准检测器和鲁棒性更强的检测器分别检测clean和adversarial图像的效果,可以看到,标准检测器在检测adversarial图像时,检测结果非常糟糕,而鲁棒性更强的检测器在检测adversarial图像时可以得到合理的检测结果。

由于目标检测在监控和自动驾驶上的重要性,找出能够使目标检测器免受各种对抗攻击的方法是非常重要的。虽然很多工作证明攻击检测器是可行的,但仍不清楚能否提升检测器的鲁棒性。本文通过将对抗训练框架从分类泛化到检测上,来提高目标检测器面对不同类型的攻击时的鲁棒性,并提出实现这一目标的可行方法。
本文的贡献如下:
- 对目标检测器的不同攻击进行分类与分析,找出它们的共同之处;
- 强调并分析了不同的任务损失函数之间的相互作用,以及它们对检测器鲁棒性的影响;
- 将对抗训练框架从分类泛化到检测上,提出一种对抗训练方法来处理任务损失函数之间的相互影响,以提升检测器的鲁棒性。
目标检测的任务损失函数
一个目标检测器将图像
作为输入,输出的是
个检测到的目标,每个目标由
和
表示,即
,其中
是对于
个类别的概率向量,
是bbox,最后通过NMS操作来得到最终的检测结果。损失函数为:
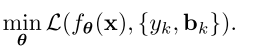
其中
表示gt,
是输入图像,用
对检测器
进行参数化,那么检测器的训练就可以归结为
的估计值。
就是损失函数,它衡量的是输出
和gt之间的不同,其最小值对应最合适的
,这个损失函数可以表示为分类损失和定位损失的结合:
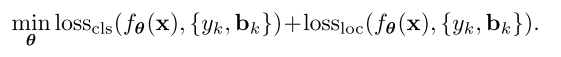
可以看到,分类和定位任务共享了一些中间计算,但是它们使用输出
的不同部分来分别计算各自的损失,这可以作为多任务学习的一个实例。
目标检测中的攻击
对于目标检测来说,有许多不同的攻击方法,但从多任务学习这个角度来看的话,它们的框架和设计原则是相同的:通过利用单个任务损失函数的变体或其组合来实现对检测器的攻击。根据这个思路,本文将攻击方法进行分类,如下表所示,可以看到,有些方法使用的是分类损失,有些方法使用的是分类损失和定位损失的结合。
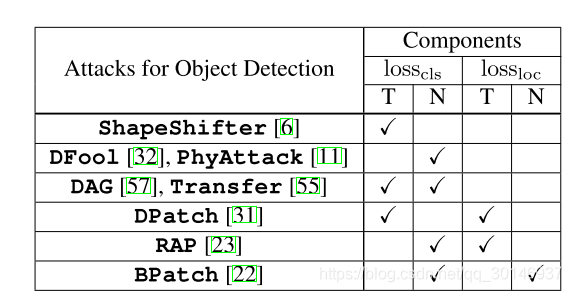
单个任务损失函数对生成攻击的有效性有以下两个方面:
- 分类和定位任务共享同一个base-net,也就是说base-net的弱点也会由其上的所有任务共享;
- 虽然分类和定位的输出是在base-net 上的两个不同的分支,但是由于测试阶段的NMS操作使它们又被耦合到一起,即使用类别分数和bbox定位来去除多余的检测结果,如下图所示:
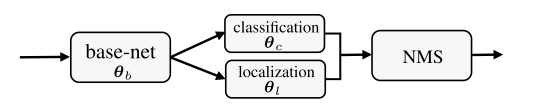
任务损失函数对鲁棒性的影响
由于分类和定位任务共享同一个base-net,因此这两个任务之间不可避免地会产生相互影响,接下来从不同的角度来分析任务损失函数对模型鲁棒性的影响。
1. 任务损失函数的相互影响
不同的任务会相互影响,针对一个任务进行的对抗攻击可能会降低模型在另一个任务上的性能。
为了说明这一点,本文在研究一个因素的同时会边际化另一个因素。比如,当考虑分类时,会忽视定位这一因素,那么问题就会变成多标签分类任务;当考虑定位时,会忽视分类这一因素,那么就变成与类别无关的目标检测问题。由于NMS操作也会使分类和定位耦合,因此只观察输出结果在经过NMS操作之前的模型的性能。如果anchor box与任意一个gt的IoU大于0.5,那么该anchor box就是正样本,也就是前景。对于分类任务,计算的是anchor box的分类精度;对于定位任务,计算的是预测的bbox与gt之间的平均IoU,两个任务损失之间的相互影响如下图所示:
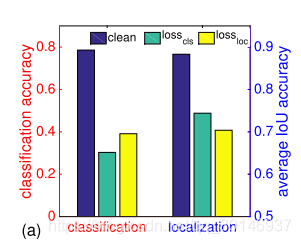
- 基于分类损失( )的攻击降低了分类的性能,并且同时降低了定位的性能,如左边的柱状图所示;
- 基于定位损失( )的攻击不仅降低了定位的性能,也降低了分类的性能,如右边的柱状图所示。
这可以被看成是一种交叉任务攻击,也就是说,当仅使用分类损失来生成对抗图像时,攻击会被转移到定位任务上,并使定位的性能降低。这也就是基于单个任务损失生成的对抗图像为什么能够攻击整个目标检测器的原因之一。
2. 任务梯度的错位
两个任务的梯度共享同一方向的一定级别,但并未完全对齐,从而导致任务梯度错位,可能会混淆后续的对抗性训练。

为了说明这一点,本文分析了从两个损失中导出的图像梯度,
和
,
和
之间的element-wise的散点图如下图所示:
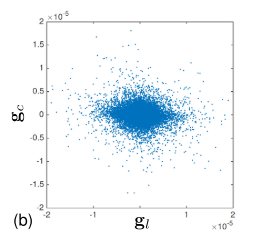
- 两个任务梯度的量级是不同的,也就是说两个任务梯度的值的范围是不同的,从图中可以看出 的值的范围明显比 大,这说明两个任务损失之间潜在的不平衡;
- 任务梯度的方向是不连续的,即点在图中呈现的是非对角的形式,这说明两个任务梯度之间存在潜在的冲突。
为了表示每个任务的最大化梯度的任务域,本文还对任务梯度域进行可视化,如下图所示:
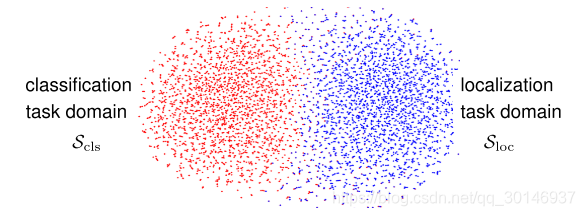
给定一个单一的clean图像x,上图中的每个点表示一个对抗样本,不同颜色表示用来生成对抗样本的不同的任务损失,即
和
,从图中可以看出,两个域并没有被完全分离开,它们有重叠的部分也有分离的部分,重叠的部分证明了两个任务损失之间的相互影响,分离的部分是任务梯度错位的一种反映。
通过对抗训练增强检测的鲁棒性
根据以上的分析,本文提出以下公式来使目标检测的训练更有鲁棒性:
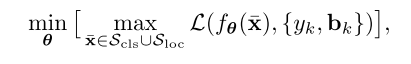
其中面向任务的域
和
分别表示每个任务产生的可行域(permissible domain)
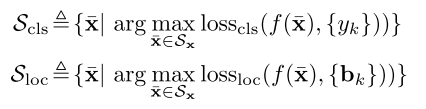
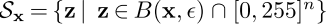
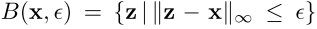
表示以clean图像
为中心,半径为perturbation budget
的
球,设
表示将输入投影到可行区域
中的投影算子。
本文的对抗训练与常规的对抗训练相比有以下几处差异:
- 使用多任务监督源来进行对抗训练。在分类案例的对抗训练中,只涉及一个来源,而在本文的对抗训练中,有多个(在存在多个目标的情况下)和异类(分类和定位)的监督源,来生成对抗样本,进行对抗训练;
- 面向任务的域约束。常规的对抗训练使用任务不可知(task-agnostic)域约束 ,而本文引入面向任务的域约束 ,该约束将可行域限制为一个图像集,这个图像集对分类损失或定位损失进行最大化处理。最终用于训练的对抗样本就是这个图像集中能够最大化整体损失的那个样本。本文提出的面向任务的域约束的优点为,可以生成由每个任务指导的对抗样本,而不会受到它们之间的干扰。
如果将面向任务的域放宽到 ,设置与整个图像相对应的bbox坐标,为图像分配一个单一的类别标签,那么就变成了分类设置下的常规对抗训练。因此,本文为鲁棒性的检测而提出的对抗训练,就可以被视为分类设置下的常规对抗训练的一种自然的泛化。然而,虽然两个任务根据其整体优势都有助于提高模型的鲁棒性,但由于面向任务的域与 是不同的,因此在生成单个对抗样本的任务之间没有任何干扰。
总结
本文提出了一种方法来增强目标检测器面对对抗攻击时的鲁棒性,作者认为,在分类的情况下,clean图像的检测精度,与目标检测器的鲁棒性之间存在一种trade-off,如何使这个trade-off达到最佳就是以后的工作了。而且,通过将目标检测看作是多任务学习的一个实例,本文也可以作为提升其它多任务学习鲁棒性的一个参考。
