论文地址:http://papers.nips.cc/paper/6676-learning-efficient-object-detection-models-with-knowledge-distillation
github地址:无
Motivation
本文提出针对目标检测网络的知识蒸馏压缩算法。之前的大多数知识蒸馏压缩算法都用于分类网络,虽然能在保留精度的同时,压缩模型,提升速度,但只在分类任务上得到了印证,在更复杂的object detection上还有待探索。在目标检测任务中,存在特殊的挑战:
- 目标检测任务标签信息量更大,根据标签学到的模型更为复杂,压缩后损失更多
- 分类任务中,每个类别相对均衡,同等重要,而目标检测任务中,存在类别不平衡问题,背景类偏多
- 目标检测任务更为复杂,既有类别分类,也有位置回归的预测
- 现行的知识蒸馏主要针对同一域中数据进行蒸馏,对于跨域目标检测的任务而言,对知识的蒸馏有更高的要求
针对这些挑战,作者提出面向检测问题的一个基于知识迁移的端到端框架;针对检测中标签少,不均衡,回归损失等问题,结合FItNets15和新的loss予以解决。
Methods
作者以Faster R-CNN模型框架为例,从主干网络,RPN,RCN(头部)三个部分,进行了知识蒸馏
 对于主干网络,作者使用FitNet中的hint learning进行蒸馏,即加入adaptation layers使得feature map的维度匹配
对于主干网络,作者使用FitNet中的hint learning进行蒸馏,即加入adaptation layers使得feature map的维度匹配
对于分类任务的输出,使用加权cross entropy loss来解决类别失衡严重问题
对于回归任务,除了原本的smooth l1 loss,作者还提出teacher bounded regression loss,将教师的回归预测作为上界,学生网络回归的结果更优则该损失为0。
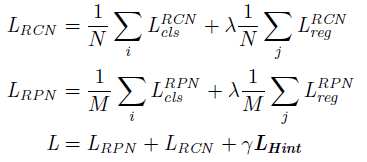
- N N N和 M M M分别是对应部分的batch-size大小, λ λ λ和 γ γ γ是超参数,作者这里分别设定为1和0.5
- L c l s L_{cls} Lcls包括 hard target 和知识蒸馏中的 soft target
- L r e g L_{reg} Lreg包括 smooth L1 和新提出的 teacher bounded L2 regression loss
- L H i n t L_{Hint} LHint为主干网络的损失
对于分类损失中的背景误分概率占比较高的情况,作者提出增大蒸馏交叉熵中背景类的权重来解决失衡问题。多加了一个 w c w_c wc, w 0 = 1.5 w_0=1.5 w0=1.5 for the background class, w i = 1 w_i=1 wi=1 for all the others
对于KD loss中的temperature scaling,作者设为1。

对于回归结果的蒸馏,由于回归的输出是无界的,且教师网络的预测方向可能与groundtruth的方向相反。因此,作者将教师的输出损失作为上界,当学生网络的输出损失大于上界时计入该损失否则不考虑该loss。
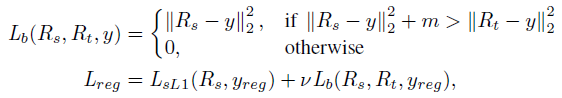
Experiments
Datasets: KITTI, PASCAL VOC 2007, MS COCO, ImageNet DET benchmark (ILSVRC 2014)
教师网络,即backbone部分:AlexNet, AlexNet with Tucker Decomposition, VGG16 and VGGM
Results



Thoughts
这篇文章也将知识蒸馏用于了目标检测网络,并且从hint learning和output learning两个level进行了蒸馏,其中对于回归的蒸馏以及分类上的加权来解决失衡问题对我是有所启发的。之前没有考虑过对回归的蒸馏方式存在的无边界问题。