1、摘要
Feature pyramids are a basic component in recognition systems for detecting objects at diferent scales.But recent deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive.In this paper, we exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost.【好用但是开销大,paper提出一个方法来少开销的使用】
2、简介
一些使用pyramid方法
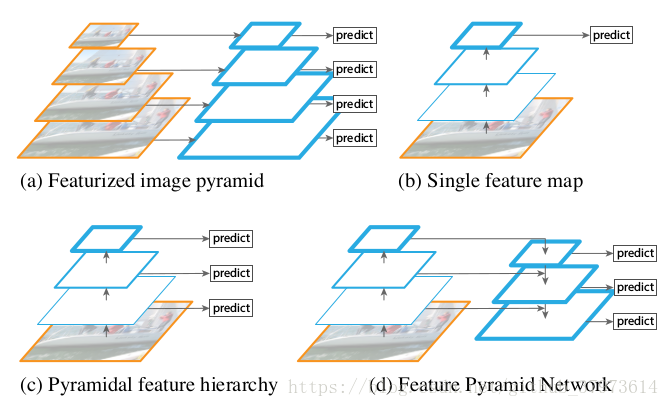
蓝色框代表feature map,框的线条越粗,其语义表达能力越强。我们可以获取输入图像的不同的尺寸,并在不同尺度上提取特征(如:SIFT、HOG),然后进行目标的预测。【参考】
- (a)用图片金字塔生成特征金字塔,在非深度的方法中比较常见,通过将图片放缩到不同的大小,这样一些类似于固定滑窗的方法就可以检测到不同大小的物体,这个内存和时间上有巨大的开销。因为CNN提取特征十分的耗时。
- (b)只在特征最上层进行预测【(b)展示了现在深度学习方法的常用策略,用深度网络提取feature maps代替了传统方法提取feature maps,深度网络提取的特征表达能力更强,从低层到高层的过程中,语义逐渐加强,我们直接在且仅在最后一层进行predict。CNN卷积操作考察的是局部像素之间的关联性、池化操作则是对局部信息进行统计,因此CNN越top,feature map中的每个单元格的感受野就越大,相对的,就没有浅层那么精细,分辨率就会下降得比较厉害,这个问题将在小目标比较突出。】
- (c)特征层分层预测【SSD-Style的单线,每层分别predict;没能重复利用上大的feature map,对小目标检测效果不好。在高层这种感受野比较大的层上预测scale比较大的物体,在浅层这种感受野比较小的层上预测scale比较小的物体,但是这样会导致一个问题,浅层分辨率虽然比较高,但是语义化层度不高,去预测小目标的效果还是不好。】
- (d)FPN从高层携带信息传给底层,再分层预测,本文所使用的【we rely on an architecture that combines low-resolution, semantically strong feature with high-resolution, semantically weak features via a top-down pathway and lateral connections. The result is a feature pyramid that has rich semantics at all levels and is built quickly from a single input image scale.】鉴于(c),FPN使用d,就是在达到了top层高语义后,再通过不断地进行upsample,然后和CNN网络中的浅层的特征融合,融合后的特征既有较高的语义性,也有较高的分辨率,这样再去分别预测不同scale的物体就会有比较好的效果。在实际使用的时候,作者的特征是across scales的,换句话说,在预测某个scale目标的时候,其他scale的特征也会起到一定的作用,这就是FPN的整体思路。
3、FPN building block
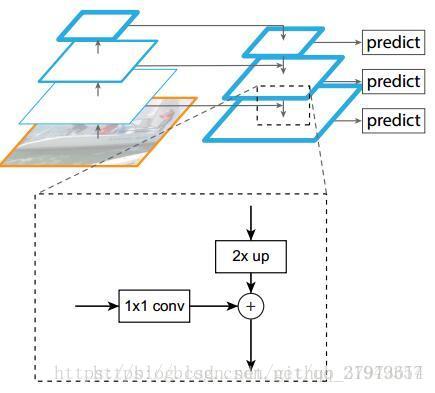
很明显有三条线,分别为:左边是Bottom-up pathway,上面是top-down pathway,最后将他们融合起来得到下面的lateral connections:
- bottom-up路线:作者使用了ResNet作为基础网络,对于本文的特征金字塔, 作者为每个阶段定义一个金字塔级别,然后选择每个阶段的最后一层的输出作为特征图的参考集【因为ResNet网络有非常多的层(20 or 101),那么将所有层分成几个阶段,取每个阶段的最后一个层来最为金字塔中的
】。这种选择很自然的,因为每个阶段的最深层应该具有最强的特征。具体来说,对于ResNets,作者使用了每个阶段的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2, conv3, conv4和conv5的输出,并且注意它们相对于输入图像具有{4, 8, 16, 32}像素的步长。考虑到内存占用,没有将conv1包含在金字塔里。
- Top-down路线和横向连接:如何去结合低层高分辨率的特征,方法就是把更加抽象、语义更强的高层特征图进行上取样(upsample),然后把该特征横向连接(lateral connections)至前一个特征,因此高层特征得到加强。值得注意的是,横向连接的两层特征在空间尺寸上要相同。这样做应该主要是为了利用底层的定位细节信息。
- 上面图中显示了连接细节,把高层特征做2倍上采样(最近邻上采样法),然后将其和对应的bottom-up上的特征结合(bottom-up上的特征需要经过1*1卷积处理,目的是为了改变channels,和Top-down上的相同),结合方式是做像素间的加法。重复迭代此过程,直至生成最精细的特征图。迭代开始阶段,作者在C5层后面加上一个1*1的卷积核来产生最粗略的特征图,最后,作者用3*3的卷积核去处理已经融合的特征图(为了消除上采样的混叠效应),以生成最后需要的特征图。{C2,C3,C4,C5}层对应的融合特征层为{P2,P3,P4,P5},对应的层空间尺寸是相通的。
- 金字塔结构中所有层级共享分类层(回归层),就像featurized image pyramid中所做的那样。作者固定所有特征图中的维度(通道数,表示为d)。作者在本文中设置d=256,因此所有核外的卷积层(比如P2)具有256通道输出。这些额外层没有用非线性,而非线性会带来一些影响。
4、还有个FPN与fast RCNN部分【摘自here】


在代码中的一些实现过程(tensorflow):

(实际中的层数可能不是图中所表示,一般因为C1占用内存太多而不包括进金字塔层)
- 怎么做上采样?
- 首先上面的block左边是一个resnet的过程,右边是一个upsample,两个部分有特征融合。C5是ResNet最顶层的输出,它会通过一个1*1的卷积层,把通道数转为256,得到FPN的最上面一层P5。
- 如何做横向连接以及作用?
- P4是上采样之后的P5与1*1卷积之后的C4的像素相加。先要把P5和C4转换到一样的尺度,再直接进行相加。
- 作用:如果不进行特征的融合(即去掉所有的侧连接,虽然理论上分辨率是没有变的,语义也增强了,但是AR下降了10%左右,作者认为这是因为特征上下采样他多次,导致他们不适于定位。Bottom-up即左边的ResNet部分包含了更加精确的位置信息。)
- P2-P5最后又作了一次3*3的卷积,作用是消除上采样带来的混叠效应。
- 金字塔结构中所有层级共享分类层是怎么回事?
- 每个ROI都在P2-P5中的某一层得到了一个特征,然后送到了同一个分类和回归网络得到最终结果。
- FPN中每一层的heads参数都是共享的,作者认为共享参数的效果也不错就说明FPN中所有层的语义都相似。
- 本文的思想?
- 把高层的特征传下来,补充低层的语义,这样就可以获得高分辨率和强语义,有利于对各种scale的目标的检测。
- 不同尺度的ROI,使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5【因为同样大小的anchor,如果在高语义部分,即在如P5这种上层,那么映射回原图的部分会更大】,小尺度ROI就用前面一点的特征层,比如P4(因为上面说过了,要用感受野比较大的高层去预测scale大的物体,而感受野比较小的去预测比较小的物体)。那如何判断ROI该用哪个层的输出呢?paper中用了如下公式,但是代码做了更改,替换为roi_level:
- FPN是基于一个主干模型的,比如ResNet。常见的命名方式是:主干网络-层数-FPN,例如:ResNet-101-FPN。