论文:Scale-Transferrable Object Detection
论文链接:https://pan.baidu.com/s/1i6Yjvpz
Scale-Transferrable Detection Network(STDN)是CVPR2018的文章,用于提高object detection算法对不同scale的object的检测效果。该算法采用DenseNet网络作为特征提取网络(自带高低层特征融合),基于多层特征做预测(类似SSD),并对预测结果做融合得到最终结果。该算法有两个特点:1、主网络采用DenseNet,了解DenseNet的同学应该知道该网络在一个block中,每一层的输入feature map是前面几层的输出feature map做concate后的结果,因此相当于高低层特征做了融合。高低层特征融合其实对object detection算法而言是比较重要的,FPN算法是显式地做了高低层特征融合,而SSD没有,这也是为什么SSD在小目标问题上检测效果不好的原因之一,因此该算法虽然看似SSD,但其实和SSD有区别。2、引入scale-transfer layer,实现了在几乎不增加参数量和计算量的前提下生成大尺寸的feature map(其他常见的算法基本上都是采用deconvolution或upsample),由于scale-transfer layer是一个转换操作,因此基本不会引入额外的参数量和计算量。
Figure1是object detection算法中常用的几种预测层设计方式:(a)是Faster RCNN的做法,显然这种做法所利用的特征层较少,效果一般;(b)是FPN算法的做法,基于融合后的特征做预测对于小目标的检测效果提升更加明显;(c)是SSD算法的做法,虽然也是基于多层特征做预测,但是每个预测分支还是基于单层特征,因此虽然浅层用来预测小目标,但由于浅层没有与富含语义信息的高层做融合,因此对于小目标的检测效果一般;(d)本文的scale transfer module(STM)示意图,其实和SSD有点类似,也是基于多层特征单独做预测,然后对每层的预测结果做整合,但因为主网络是DenseNet,所以存在高低层特征的融合,因此实际上有类似FPN的效果。除了这一个创新点外,还有一个创新点在于提速,提速一方面是通过对特征提取层的输出feature map做通道缩减,另一方面是生成特征金字塔中尺寸较大的feature map时采用scale-transfer layer实现,这种实现方式基本上不会引入参数量和计算量。
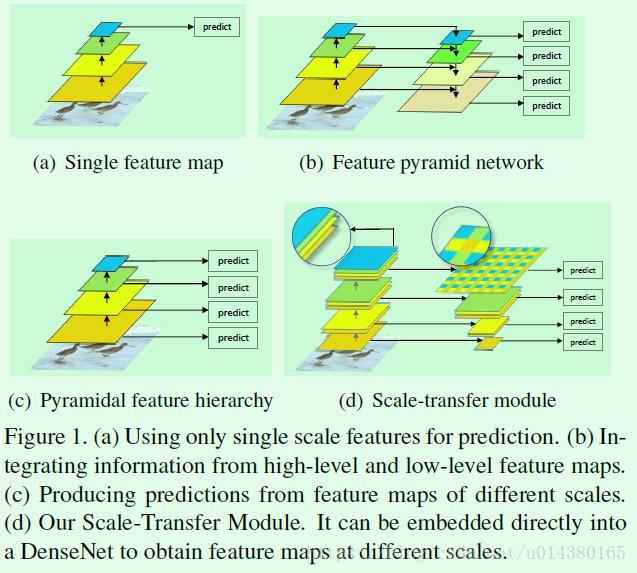
Figure2是Scale-Transferrable Detection Network(STDN)的网络结构图。首先基于300*300的输入图像得到9*9大小的feature map,然后基于9*9的feature map得到一系列相同尺寸的feature map,这些feature map是后续生成特征金字塔的基础。接着为了生成特征金字塔,对于特征金字塔中尺寸较小的feature map,采用pooling的方式得到;而对于特征金字塔中尺寸较大的feature map,采用scale-transfer layer来得到,这两种方式合在一起称作scale-transfer module。
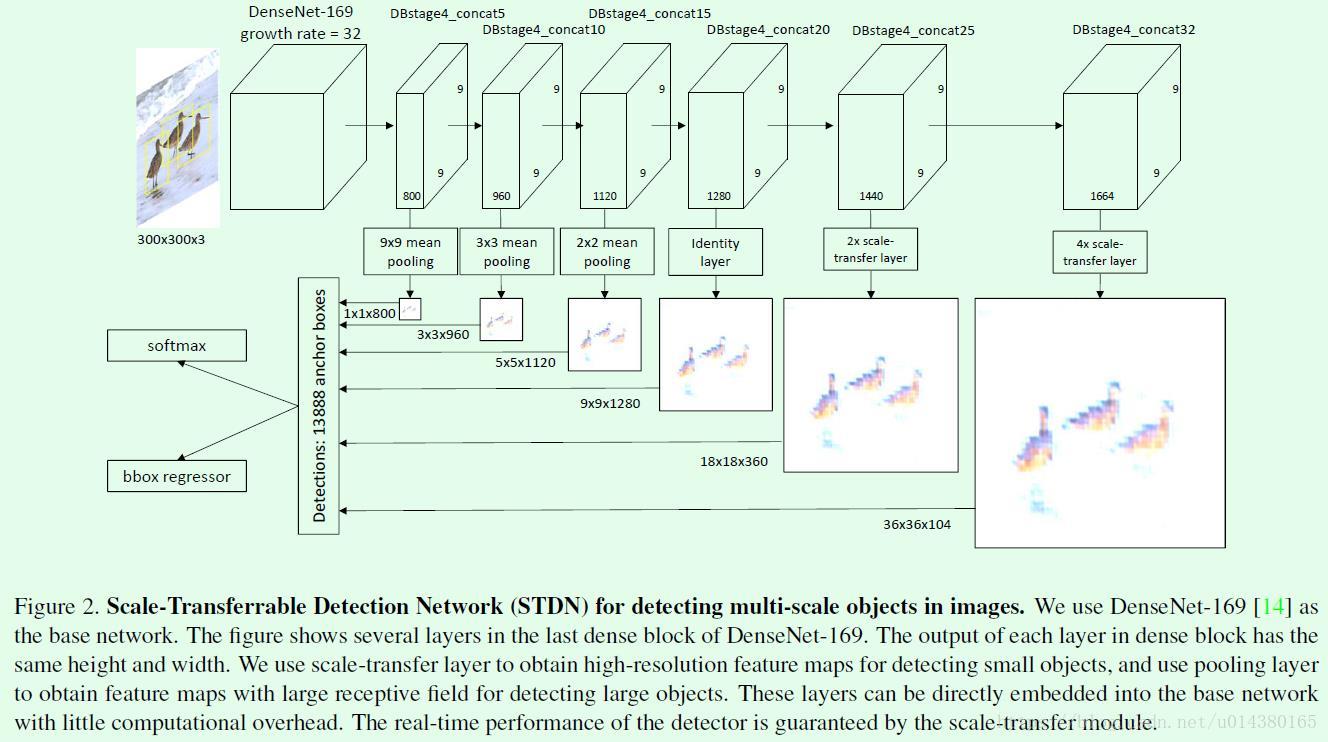
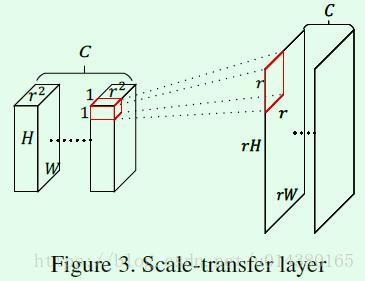
Figure3是scale-transfer layer的示意图,本质上就是通道到宽高的“reshape”操作。什么意思呢?以Figure2中对最右边的feature map做scale-transfer为例,输入feature map的维度是9*9*1664,经过一个4*scale-transfer layer后得到36*36*104维度的feature map。这个4就代表Figure3中的r,也就是要将feature map的长宽变为原来的多少倍。具体怎么transfer呢?再看看Figure3,首先将输入feature map在channel维度上按照r^2长度进行划分,也就是划分成C个,每个通道长度为r^2的feature map,然后将每个1*1*r^2区域转换成r*r维度作为输出feature map上r*r大小的结果,最后得到rH*rW*C的feature map,因此和deconvolution、upsample不同的是,这种scale-transfer操作基本上不会引入额外的参数量和计算量。
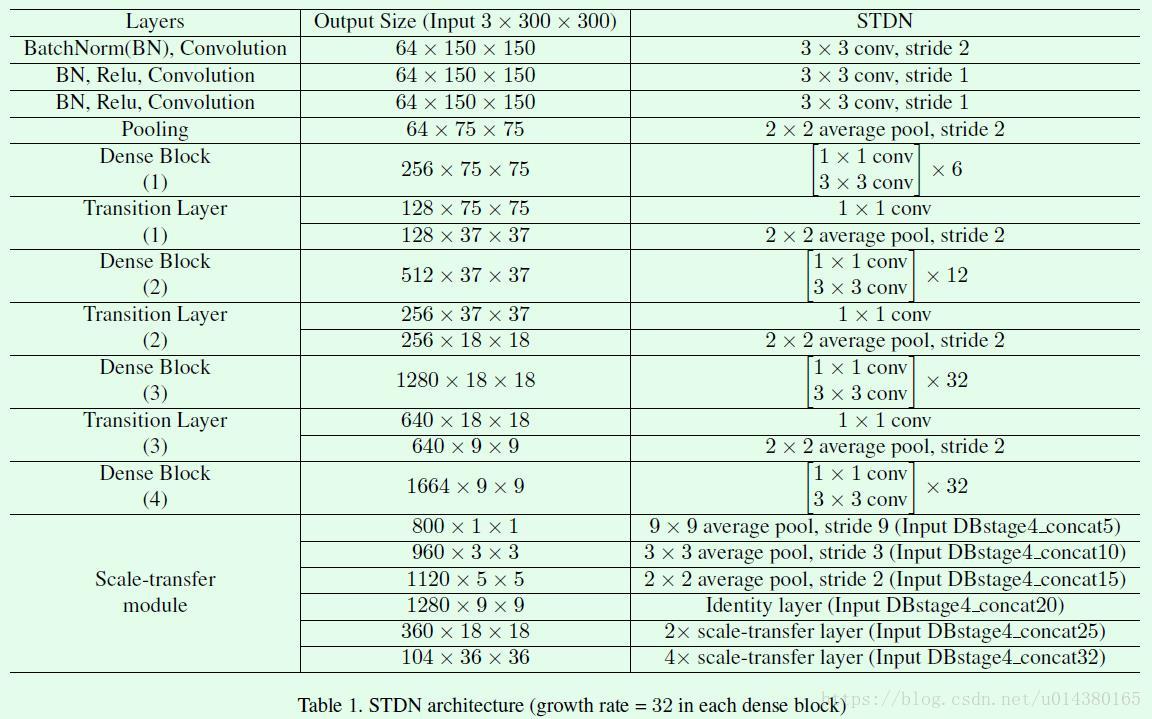
综上,Table1给出了STDN网络的具体信息。
实验结果:
Table2是在VOC 2007数据集上的测试结果。
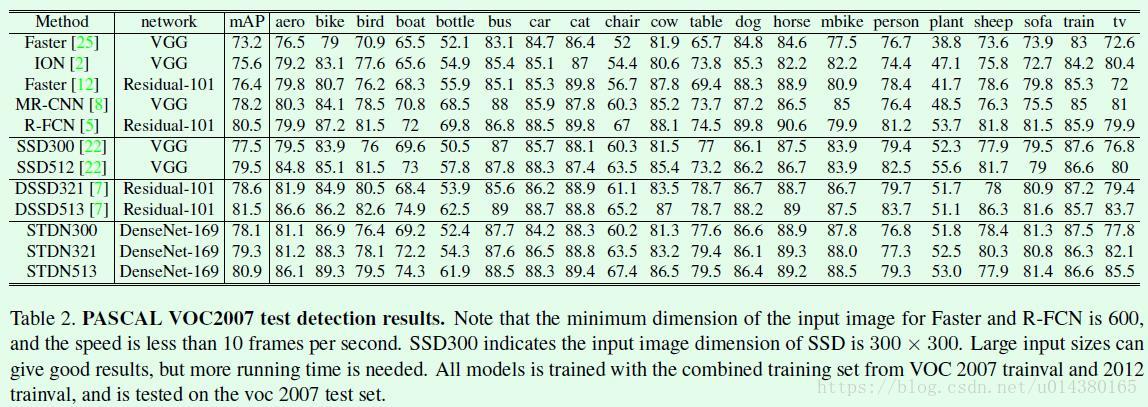
Table3是分析STDN几个子部分:scale-transfer Module、stem block所带来的提升,说明一下stem block是指Table1中的前3个3*3的卷积层和1个2*2的max pooling,这是作者对原来DenseNet网络的前两层(7*7卷积+3*3的max pooling)的修改。第一格中的两个算法对比可以看出利用STM模块得到的feature map进行预测效果提升明显。第二格中的两个算法对比可以看出stem block修改带来的提升。第三格中的两个算法对比可以看出主网络采用DenseNet-169带来的提升。
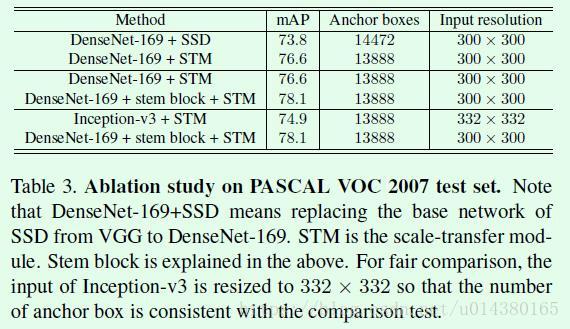
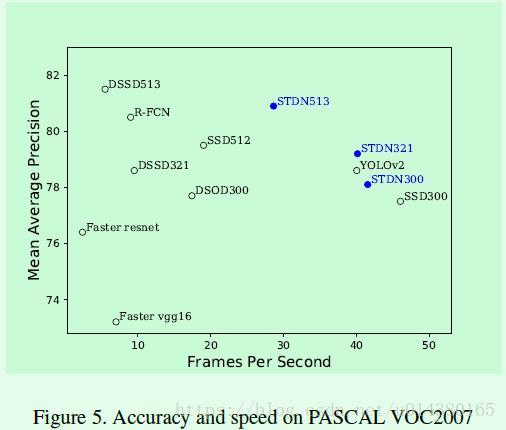
Table4是在COCO数据集上的结果。Table5是在VOC2007上的速度和准确率对比,作者强调,虽然STDN513在效果上低于DSSD513,但是速度是DSSD513的5倍。确实,STDN在准确率和速度平衡之间做得挺不错。
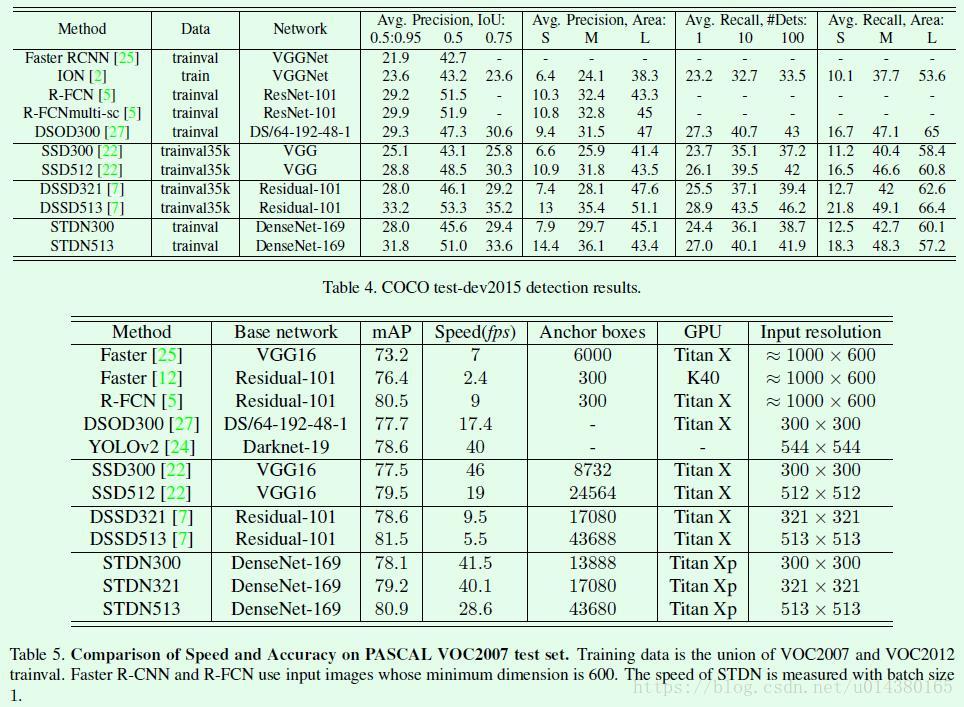
Figure5是几个算法在速度和准确率之间的对比图。