鲁棒的跟踪算法需要检测模型来找回因为严重变形和视野外运动导致的丢失情况。
对于每一个正在跟踪的目标Z,我们计算它的置信得分,用长期跟踪滤波器AL,表示为

为了效率,我们使用在线SVM分类器作为detector而不是使用长期跟踪滤波器AL,我们通过 在预估的位置和尺度处 周围 drawing(绘制?)密集训练样本 来逐步地训练SVM分类器,并根据与 【54】 相似的 重叠度 分配这些样本的二值标签。
在本文的工作中,为了进一步减少计算资源的使用,我们只 take 位移样本 for 训练,我们用量化的 颜色 直方图作为特征表达,颜色特征也就是每个频道 在 CIE LAB 颜色空间被量化成4个 bin方向,就像 论文【54】中的那样。 为了改善对剧烈光照变化的鲁棒性,我们将非参数局部秩变换【53】应用于 L 信道。
在一帧中,给定一个训练集 
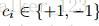
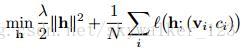

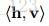
不像之前的【2,54】的方法,他们maintain一个大量的 支持向量池 来 进行增量更新,我们使用被动的 算法【9】(Online passive-aggressive algorithms)来更有效地更新 超平面 的参数 :

其中
下面摆出算法:

5 具体实施方法:
图 3 展示了我们提出的跟踪算法的主要步骤。我们学习了三种类型的相关滤波器(AT、AS、AL),它们分别用于平移估计、尺度估计和长期跟踪滤波器(捕获目标appearance的长期记忆滤波器)。我们还构建了一个基于SVM的再检测模块,用于从丢失目标附近区域中恢复目标。
上面图片中算法1总结了所提出的三个跟踪器。我们的平移过滤器 AT 通过结合 背景 信息将目标对象从背景中分离出来。现有的方法【24(KCF),11】使用一个扩大的目标bounding box窗以固定比率r=2.5搜索,以纳入目标周围的上下文信息。我们的实验分析(参见6.6节)显示,稍微增加上下文区域会带来更好的结果。我们把 r 的值设为较大的2.8。(我自己修改的算法中padding窗设置为了2.86),我们还考虑了bounding box的长宽比。我们观察到,当目标(例如行人)具有较小的纵横比时,r值越小,在垂直方向上就可以减少不必要的上下文区域。为此,当宽径比小于0.5时,我们在垂直方向上将r降低一半(更详细的分析见6.6节)。(相当于在程序里对不同目标设置不同的padding窗,以及不同的ratio)
为了训练SVM检测器,我们从一个以估计位置为中心的窗口中密集地抽取样本。当这些样本与目标bounding box的重叠比大于0.5时,我们给它们分配正标签;当它们的重叠比小于0.1时,我们给它们分配负标签。我们设置了激活检测模块的再检测阈值Tr=0.15,采用检测结果设置接受阈值Ta=0.38。这些设置意味着我们保守地采用每个检测结果,因为它会重新定位目标并重新初始化跟踪过程。我们将稳定阈值TS设置为0.38,以保守地更新滤波器AL,以维持目标外观的长期记忆。注意,所有这些阈值与由长期滤波器AL计算的置信分数相比较。正则化参数 lamda 设为0.0001。将高斯核宽度α设为0.1,生成 软标签 的其它核宽度α0与目标大小成正比,即=0.1*sqrt(W·H),学习率设置为0.01。对于尺度估计,我们使用特征金字塔的设置为21个层,并将比例因子α设置为1.03。在式子(22)分母中的超参数 τ 设置为 1。我们经验确定所有这些参数,并将它们固定在所有的实验中。