版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/winycg/article/details/82830673
感知算法
线性分类器:
f(x;w,b)=⟨w,x⟩+b,决策:
sgn[f(x;w,b)]
线性感知机(Perception)算法:
输入:训练数据
D={(xi,yi)}i=1N,学习步长
η>0
输出:感知模型的
w,b
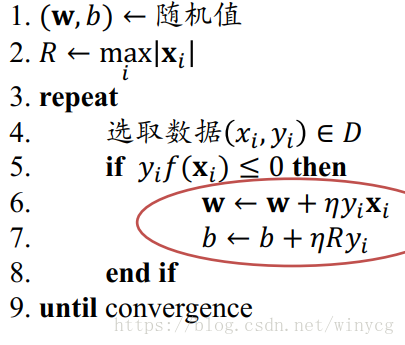
证明:
yift+1(xi)>yift(xi)
yift+1(xi)=yi[⟨wt+1,xi⟩+bt+1]=yi[⟨wt+ηyixi,xi⟩+bt+ηRyi]=yi[⟨wt,xi⟩+bt+⟨ηyixi,xi⟩+ηRyi]=yift(xi)+η(⟨xi,xi⟩+R)>yift(xi)
每次更新都会减少错误。将0替换为
τ>0可以得到带边距的感知机。
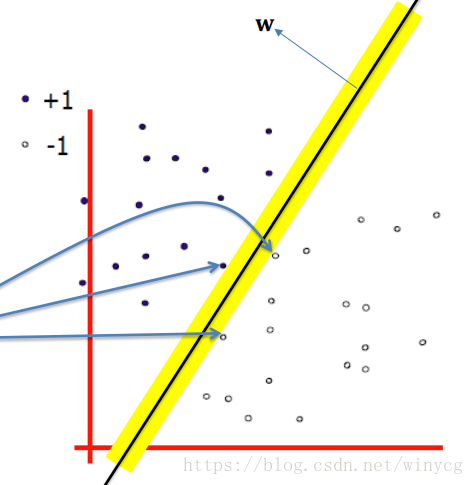
线性SVM
感知算法的优化目标是最小化分类误差,SVM的优化目标是最大化分类边距,边距是指两个分离的超平面(决策边界)间的距离,位于分类边距上的数据点成为支持向量。图中蓝线所指的就是支持向量。
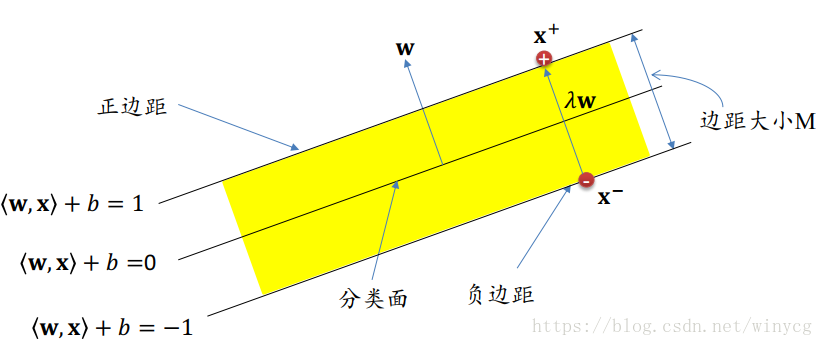
计算边距的大小:
普及知识:直线
f(x;w,b)=⟨w,x⟩+b的权重向量
w与直线
f(x;w,b)是垂直的。不妨举个例子:设
x+y+1=0,则权重
w=(1,1),此时直线和向量
w在坐标系中是垂直的。
假设为如图所示的正边距和负边距,则两者之间的间距为:
⟨w,x+⟩+b−(⟨w,x−⟩+b)=⟨w,x+−x−⟩=2
对于
x+和
x−,有
x+−x−=λw
两个公式联立可得:
λ⟨w,w⟩=2⇒λ=∥w∥22
边距大小
M=∥x+−x−∥=∥λw∥=∥w∥2
SVM的学习过程归结为寻找合适的
w和
b:
- 所有的训练数据都在正确的分类区域
yi(⟨w,xi⟩+b)≥1,其中yi∈{−1,+1}
- 最大化边距:
max∥w∥2⇔min∥w∥2
其中,公式中的1和2都是与分类边距有关。
软边距的SVM
如果不存在一个分类面使得训练数据能够被完美分开,那么边距不再是硬性限制(软边距),需要在优化目标中加入错误惩罚,错误惩罚为出错数据点与正确位置的距离。
优化目标:
min∥w∥2+C∑i=1Nξi
约束条件:
yi(⟨w,xi⟩+b)≥1−ξi,ξi≥0,i=1,2,...,N
其中参数
C是一个权衡,
C变大,牺牲了分类间隔,减少了训练集错误。
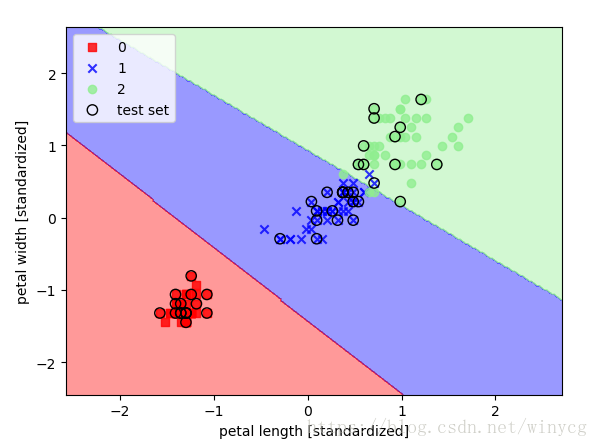
利用线性SVM对鸢尾花数据集进行分类:
from sklearn.svm import SVC
import numpy as np
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
svm = SVC(kernel='linear', C=1.0, random_state=0)
svm.fit(X_train_std, y_train)